本文主要是介绍【分库分表】基于mysql+shardingSphere的分库分表技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.什么是分库分表
2.分片方法
3.测试数据
4.shardingSphere
4.1.介绍
4.2.sharding jdbc
4.3.sharding proxy
4.4.两者之间的对比
5.留个尾巴
1.什么是分库分表
分库分表是一种场景解决方案,它的出现是为了解决一些场景问题的,哪些场景喃?
-
单表过大的话,读请求进来,查数据需要的时间会过长
-
读请求过多,单节点IO压力太大,IO压力太大会造成什么?可能会造成IO阻塞,造成响应速度变慢。
分库分表是指的两种维度,一种维度是分库,另一种维度是分表。分的话有两种分法,一种是水平分,另一种是垂直分。
水平分是指将数据分为多段,一个服务器节点上存放一段,读写的时候走自己要的那一段所在服务器上。一段也叫一个分片(sharding)
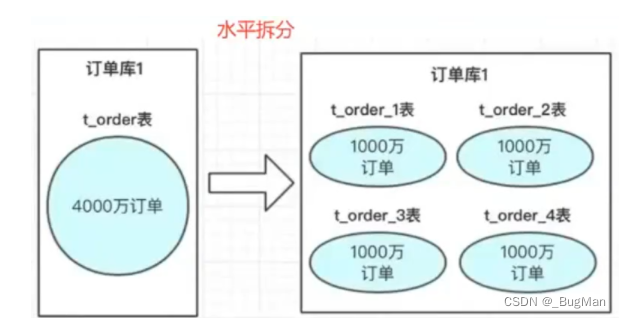
垂直分是指将一个库或者一个表从一个整体拆成多个部分,不同服务器上存储一部分:

2.分片方法
其实总的来说分库都还好,垂直分库对应着服务拆成微服务做到资源隔离各玩儿各的,问题都还不大,而且一般不会出现水平分库,因为库里面数据多的也就某一些表,我们面对更多的是水平分表。水平分表首先要面对的就是如何分片?
分片方法有如下几种:
-
hash分片法
-
range分片法
hash分片法:
主键对服务器数量取余。

这种方式在扩容后数据需要重新散列一遍,重新散列一遍花时间吗?当然花时间,但是不散列又不行,为什么喃?举个例,原来id=12的数据散列到了0表,扩容后不迁移的话按照规则id=12的表会散列到4表,这就会导致id=12这条数据在查找的时候找不到:
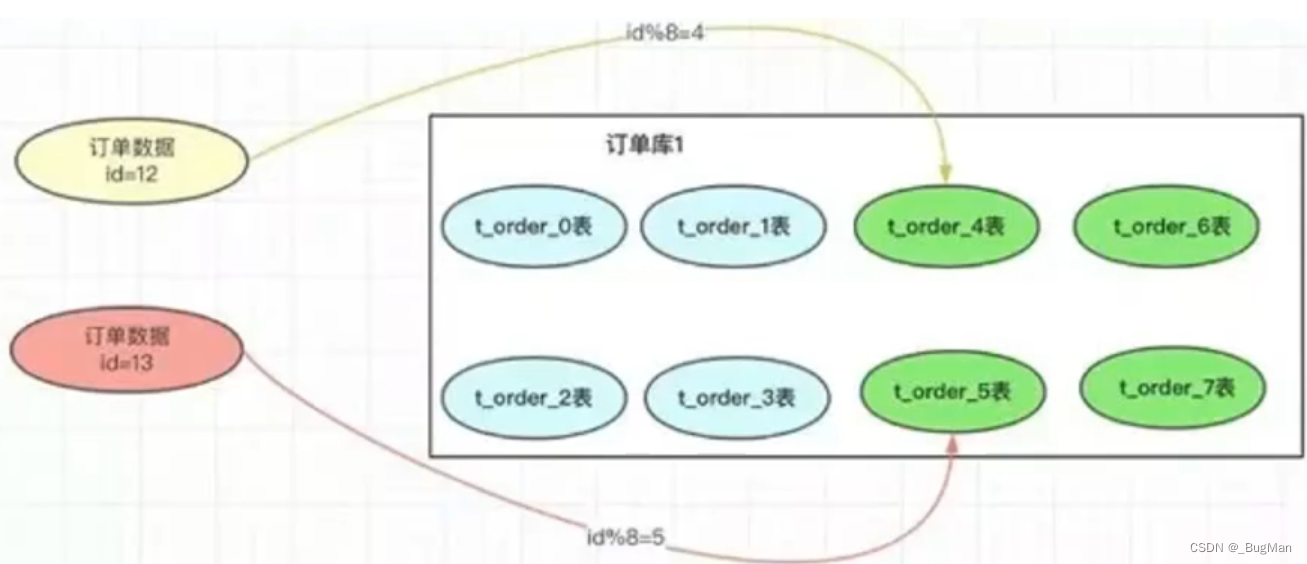
当然hash算法可以用一致性hash算法来优化,但其数据迁移肯定是无法规避的,且一致性hash算法本身也存在无法规避的缺点。博主之前有一篇一致性hash算法的文章,可移步:
一致性hash算法_一直hash算法-CSDN博客
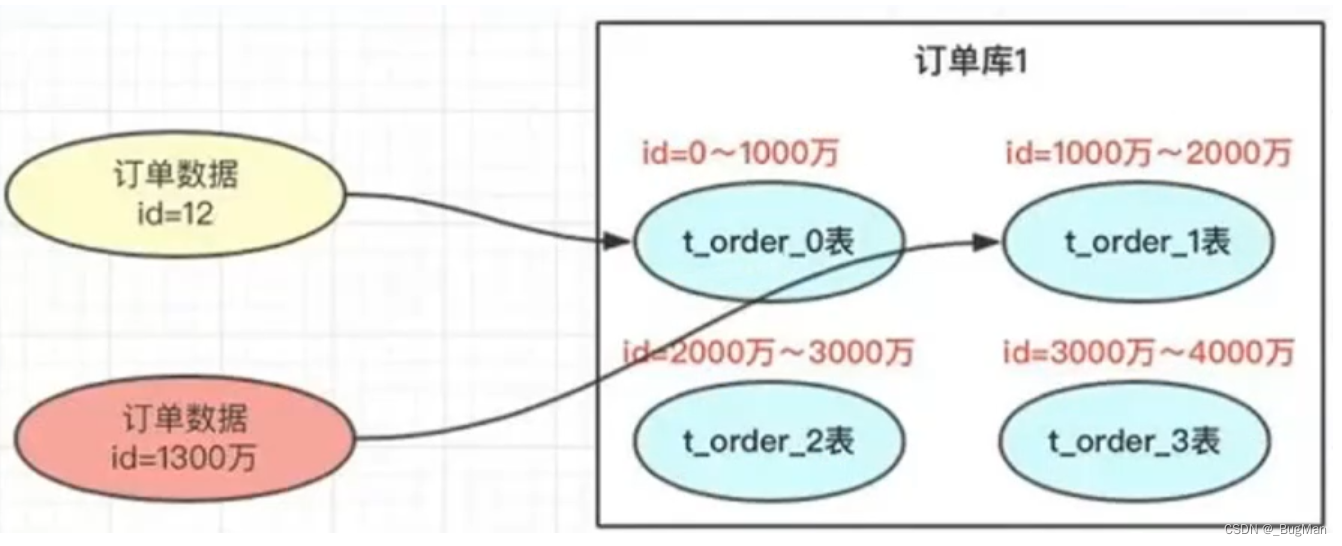
range分片法:
按照编号顺序均匀的分片,好处是扩容不用散列,但是新数据往往是使用频率更高的数据,会导致压力不均匀,而且现在一般唯一ID为了安全性都是无序的,比如采用UUID做主键的时候,所以range分片法的场景适用也很有限。
3.测试数据
用一张订单表来做测试数据,根据主键来分库分表:
create table order_( id varchar(100) primary key, productName VARCHAR(100), productId VARCHAR(100), createTime datetime, statue INT )ENGINE=INNODB;
准备了两个库,db01和db02都有这张订单表:

依赖版本:
千万注意版本的对齐!
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--prometheus --><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId></dependency> <!-- MySQL驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.29</version></dependency><!-- MyBatis Plus Starter --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><!--sharding-jdbc--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><!-- Alibaba Druid 数据源 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.6.3</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
4.shardingSphere
4.1.介绍
分片方法说起来容易,要自己去实现一个全过程的分片分表还是很繁琐的,需要手动实现多数据源,然后实现散列算法来控制读写请求映射到哪一台服务器,升级一点的功能还包括要与服务器进行心跳通信,获取服务器的信息等等。所以说还是直接用"轮子"吧。
Apache ShardingSphere 是一个开源的分布式数据库中间件解决方案,它由阿里巴巴集团开源,目前是 Apache 软件基金会旗下的顶级项目。ShardingSphere 通过提供一组与数据库交互的标准化接口(如JDBC驱动或代理服务),对上层应用隐藏了复杂的分布式数据库处理逻辑,为开发者提供了易用且功能强大的分库分表、读写分离、数据治理、弹性伸缩等功能。
ShardingSphere分为三部分:Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar。
4.2.sharding jdbc
其中Sharding-JDBC,其会托管JDBC,然后支持实现分库分表、读写分离。分库分表和读写分离都是通过配置实现的,配置好数据源,然后配置好分库规则即可。当然读写分离的前提是数据库已经配置成了读写分离的模式。以下是配置示例:
spring:application:name: testDemoshardingsphere:datasource:names: ds0,ds1ds0:driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/db01?serverTimezone=UTCusername: rootpassword: adminds1:driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/db02?serverTimezone=UTCusername: rootpassword: adminsharding:default-database-strategy:inline:sharding-column: order_idalgorithm-expression: ds$->{order_id % 2}tables:t_order:actual-data-nodes: ds$->{0..1}.t_order_$->{0..1}table-strategy:inline:sharding-column: order_idalgorithm-expression: t_order_$->{order_id % 2}#读写分离master-slave-rules:ms_ds:master-data-source-name: ds0slave-data-source-names: ds1load-balance-algorithm-type: ROUND_ROBIN #负载均衡算法props:sql.show: true #是否打印sql
上述YAML配置已经使用了inline表达式实现了基于order_id字段的分库和分表规则。当然还提供了接口,对于自定义分库、分表规则,可以通过实现ShardingSphere提供的接口来自定义算法类,并在配置中引用这些类。
public class CustomDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {// 根据order_id和其他可能的业务逻辑计算数据库名称int orderId = shardingValue.getValue();return "ds" + (orderId % 2); // 这里仅作为示例,实际请根据业务需求编写}
}
spring:application:name: testDemoshardingsphere:# ... 数据源配置 ...sharding:default-database-strategy:precise:sharding-column: order_idalgorithm-class-name: com.example.CustomDatabaseShardingAlgorithmtables:t_order:actual-data-nodes: ds$->{0..1}.t_order_$->{0..1}table-strategy:precise:sharding-column: order_id# 同样可以为表级别分片指定自定义算法类algorithm-class-name: com.example.CustomTableShardingAlgorithm# ... 读写分离配置 ...props:sql.show: true
同样的,如果需要自定义分表规则,也需要创建一个实现相应接口(如PreciseShardingAlgorithm)的类,并在table-strategy部分通过algorithm-class-name属性引用它。以上示例中的CustomTableShardingAlgorithm即是一个假设存在的自定义分表策略类。请确保实际应用中已正确创建并配置此类。
4.3.sharding proxy
sharding proxy是一个中间件,也能实现分库分表和读写分离。不同于sharding jdbc需要侵入代码中对JDBC进行一个托管,sharding
proxy是无侵入式的,一个独立的组件。
sharding proxy需要先下载,然后解压、配置。
配置示例:
配置数据库的信息

然后需要导入mysql的驱动:

配置分库分表:
这里要注意了databaseName指向的数据库是一个总库,应用都会往这个库里面进行数据读写,然后由sharding proxy来向我们配置的不同数据源里进行分库分表。给出一个配置文件,大家感受一下,该配置文件基于Apache ShardingSphere 5.x版本的语法编写。不同版本可能配置项存在不同哈。
# config-sharding.yaml
schemaName: testDemo # 指定逻辑库名称
rules:- !SHARDINGdataSources:ds0:url: jdbc:mysql://localhost:3306/db01?serverTimezone=UTCusername: rootpassword: adminconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000type: com.alibaba.druid.pool.DruidDataSourceds1:url: jdbc:mysql://localhost:3306/db02?serverTimezone=UTCusername: rootpassword: admin# 其他连接池属性...
shardingRule:tables:t_order:actualDataNodes: ds$->{0..1}.t_order_$->{0..1}databaseStrategy:inline:shardingColumn: order_idalgorithmExpression: ds$->{order_id % 2}tableStrategy:inline:shardingColumn: order_idalgorithmExpression: t_order_$->{order_id % 2}
masterSlaveRules:ms_ds:masterDataSourceName: ds0slaveDataSourceNames: [ds1]loadBalanceAlgorithmType: ROUND_ROBIN
props:sql.show: true
4.4.两者之间的对比
sharding jdbc是侵入了应用,托管了JDBC,对代码有侵入性。
sharding proxy是对数据库下手,其并没用侵入数据库,也没用上数据库的bin log,而是去监听数据库的端口从而来拦截下sql。
但是proxy明显可以看到是中心化的,都在向一个点来写数据,是会有性能瓶颈的。
5.留个尾巴
不管是水平拆还是垂直拆,分库分表后一定会存在两个核心问题:
-
不好join,需要在程序层面进行join
-
分布式事务
sharding是如何解决第一个问题的喃?首先sharding会各个节点上进行全表扫描,用类似笛卡尔积的办法聚合成最终的结果。
至于第二个问题,留在后文,我们将深入探究一下sharding生态圈是如何实现分布式事务的。除此之外还有一些尾巴要留在后文继续展开,包括:
- sharding jdbc是如何托管JDBC的
- sharding proxy是否存在中心化架构带来的性能问题?有没有办法规避?
这篇关于【分库分表】基于mysql+shardingSphere的分库分表技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






