本文主要是介绍2023年第三届中国高校大数据挑战赛D题超详细解题思路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
赛题 D:行业职业技术培训能力评价
本次给大家带来3月份大数据挑战赛D 题的详细思路。本次的C、D与去年12月份的A、B不同,难度大大降低。这也是因为去年千只队伍,最终只提交了127份论文的缘故(个人猜测)。预估选题人数大概为C:D=2:8。基于这样的选题人数,想要获奖,就必须在做D题的时候有一定的创新点才能博得评委眼前一亮。因此,在后续的思路介绍中每一问都给出创新点加分点以及多种模型的选择。
D题题目为行业职业技术培训能力评价,总体来看是数据+评价+预测类型题目,出题方式难度都是常规类型,常规难度。对于数学建模而言,我们是依靠数据进行的定量分析的过程。定量分析的量就是数据,因此我们需要对数据进行分析处理。想要从选D题的人中脱颖而出,数据预处理是必须得。在数模届,数据预处理就相当于数学大题的“解”一样。可以不会做题,但是“解”必须有,不写“解”是扣分的。因此,第一步一定要进行数据预处理而非直接进行问题一的求解
数据预处理
数据预处理包括异常值、缺失值、降维等。对于这里题目给出的数据,目前并未发现异常值、缺失值的存在。因此,本文的数据主要可以进行绘制折线图分析数据+分布方式的判定完成数据预处理工作。
绘制折线图分析数据的目的在于可以增加论文的可视化以及对给出的数据进行初步的分析处理。简单的可以直接使用Excel绘制,高级的可以直接使用python或者matlab进行绘制。(由于数据过多,这里为了美化可以绘制一部分人群的数据就可以类似于下图)。同时,可以判断题目给出数据的分布(正态分布与否)。


问题一、一般而言,入学的各技能考核成绩与对应的离校考核成绩绩可能存在着或多或少或无的关联性。请你对此进行分析?
问题一,需要我们对入学的各技能考核成绩与对应的离校考核成绩绩进行关联性分析,常见的关联分析模型以及适用范围,如下图所示。这里比较推荐直接使用Pearson或者Spaerman进行相关性分析。二者的不用在于数据是否服从正态分布,因此才需要在数据预处理阶段判定数据分布方式。
创新点:该问题大家基本都会选择Pearson或者Spaerman进行分析,想要与众不同就在于我们可以加入对数据分布方式的判定。还可以增加可视化,即绘制更加好看的可视化结果,例如可以绘制气泡图、矩阵热力图等具体形象的展示结果。

问题二(类型、学校)、不同的培训学校有不同的生源质量、学校办学条件、学校师资水平等的差异,仅仅用离校考核成绩的高低无法真正有效的体现一个学校的真正的培训能力。你运用附件数据,阐明什么类型的 培训学校,具体哪些培训学校在培训能力上面有较高的水平?请给不同类型的培训学校培训能力进行排序,以及给出培训能力前10的学校编号。
对于该问题,评价的主体是不用类型下的学校,主体是学校,这里需要选择一些指标来评价学校的好坏。可以选择很多指标,例如,
平均进步幅度:离校考核总分成绩与入学考核总分成绩之间的差值。它可以衡量学生在培训期间的进步程度。
目标达成率:设定一个阈值分数,达到该分数的才是可以视为合格。
培训质量稳定性指标:计算学校内学员离校考核成绩的标准差或方差,评估学校培训质量的稳定性。
成绩分布分析:分析学员离校考核成绩的分布情况,包括最高分、最低分、中位数等,以评估学校培训效果的全面性和均衡性。
培训质量指标:计算学校学生离校考核成绩的均值
进步学员比例:统计在各项技能或总分成绩上有所进步的学员比例,以反映学校培训的有效性。
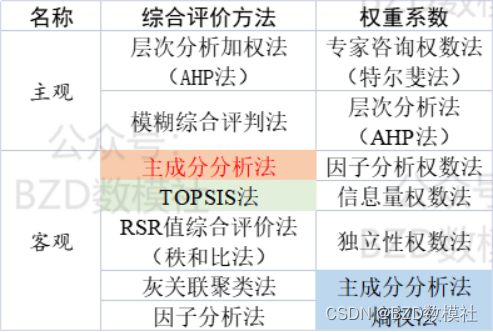
根据上述选择的指标对每个学校的数据进行计算,最终得到学校的各种指标得分。利用该得分结果建立评价模型进行评价即可。下面是评价模型的选择建议,对于各种评价模型均是可以的,在数模届没有绝对的对与错。这里的建议就是优先选择客观的评价模型,基于你们队伍选择的指标个数,指标个数多可以构建主成分分析,指标个数少可以构建熵权法、理想解法等。
创新点:对问题二而言最主要的在于指标的选择。每个队伍选择的指标都可能不太一样,这里的几个指标是大家可以参考着来。问题二指标选的越好得分就越高,评价模型这里选什么都可以,没有谁好谁坏之分。
问题三(技能、学校)、每个培训学校有不同的特色,如有些培训学校技能 1 的 培训能力很好,而有些学校可能是技能 2 的培训能力上有优势。请问, 哪些培训学校分别在哪种技能培训能力上有特色?每种技能列出前 5 名的学校编号。
对于问题是三,评价主体不再是不同类型下的学校而是不同技能下的学校。这里的大致做法步骤与问题二相同,只不过在指标的构建阶段,我们不能仅仅限于最终总分,还应该加入具体每一项技能的评价指标。这里我们以技能一为例,我们可以选择
技能一的平均进步幅度:离校考核技能一分成绩与入学考核技能一分成绩之间的差值。它可以衡量学生在培训期间的进步程度。
技能一的目标达成率:设定一个阈值分数,达到该分数的才是可以视为合格。
技能一的培训质量稳定性指标:计算学校内学员离校技能一考核成绩的标准差或方差,评估学校培训质量的稳定性。
技能一的成绩分布分析:分析学员离校技能一考核成绩的分布情况,包括最高分、最低分、中位数等,以评估学校培训效果的全面性和均衡性。
技能一的培训质量指标:计算学校学生离校技能一考核成绩的均值
技能一的进步学员比例:统计在技能一有所进步的学员比例,以反映学校培训的有效性。
选定指标后,可以建立与问题二相同或者不同的评价模型进行评价即可。选择相同的模型,好处在于整体文章具有整体性;选择不同的模型,可以提高文章模型复杂度,但是文章模型的整体性会降低。
创新点:对问题三而言与问题二相同,最主要的在于指标的选择。每个队伍选择的指标都可能不太一样,这里的几个指标是大家可以参考着来。问题三指标选的越好得分就越高,评价模型这里选什么都可以,没有谁好谁坏之分。
问题四(分数、学生)、假设行业主管部门计划给 10000 名学员颁发职业资格证书。 请问,哪些因素对获取职业资格证书有着非常重要的影响?数据表中最后有 10 名学员的离校考核成绩被删除,请你判断他们能否获取职业资格证?如果职业资格证分为一级和二级(一、二级比例为 1:3),那这 10 名学员中谁能获取一级职业资格证书?
问题四主要是两个部分需要先设定职业资格证书的对象,再进行预测最后有 10 名学员的情况。简单来讲,我们可以直接使用阈值划分将最终分数的前一万名设定为可以颁发职业资格证书,其中前25%为一级职业资格证,后75%为二级职业资格证。对于哪些因素对获取职业资格证书有着非常重要的影响?我们可以选取指标与最终成绩进行关联分析,根据相关性分析结果分析即可。
预测部分,根据选取指标与最终成绩关联分析的结果,选择关联性较好的指标进行构建线性回归模型,进行预测即可。对于预测模型的选择,与问题二三一样,没有对错之分,只要能求解计算就可以。

创新点:问题四的主要创新点就在于一万名证书的设定,如果不使用阈值划分可以有其他更好地设定一定是很好的加分项。其次,就是预测模型的选择,虽然与问题二三相同但是预测模型更加追求精度,精度越好的结果得分相应的也会好一些。因此我们可以选择一些比较高级的预测模型,例如本次论文我可以直接选择加权平均预测模型。
这篇关于2023年第三届中国高校大数据挑战赛D题超详细解题思路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







