本文主要是介绍Docker上部署LPG(loki+promtail+grafana)踩坑复盘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Docker上部署LPG(loki+promtail+grafana)踩坑复盘
- 声明
- 网上配置
- 部署踩坑
声明
参考掘金文章:https://juejin.cn/post/7008424451704356872
版本高的用docker compose命令,版本低的用docker-compose
按照文章描述,主要准备loki、promtail、docker-compose文件,修改其中部分配置,得到如下文件:

网上配置
-
loki.yml不用修改:
auth_enabled: falseserver:http_listen_port: 3100ingester:lifecycler:address: 127.0.0.1ring:kvstore:store: inmemoryreplication_factor: 1final_sleep: 0schunk_idle_period: 1h # 此时没有接收到新日志的任何块都将被刷新max_chunk_age: 1h # 所有的块将刷新时,他们达到这个年龄,默认是1hchunk_target_size: 1048576 # Loki将尝试构建最大为1.5MB的块,如果先达到chunk_idle_period或max_chunk_age,则首先刷新chunk_retain_period: 30s # 如果使用索引缓存,必须大于索引读缓存TTL(默认索引读缓存TTL为5m)max_transfer_retries: 0 # 块传输禁用schema_config:configs:- from: 2021-9-8store: boltdb-shipperobject_store: filesystemschema: v11index:prefix: index_period: 24hstorage_config:boltdb_shipper:active_index_directory: /loki/boltdb-shipper-activecache_location: /loki/boltdb-shipper-cachecache_ttl: 24h # 可以在更长的查询周期内提高更快的性能,使用更多的磁盘空间shared_store: filesystemfilesystem:directory: /loki/chunkscompactor:working_directory: /loki/boltdb-shipper-compactorshared_store: filesystemlimits_config:reject_old_samples: truereject_old_samples_max_age: 168hchunk_store_config:max_look_back_period: 0stable_manager:retention_deletes_enabled: falseretention_period: 0sruler:storage:type: locallocal:directory: /loki/rulesrule_path: /loki/rules-tempalertmanager_url: http://localhost:9093ring:kvstore:store: inmemoryenable_api: true -
promtail.yml不用修改:
server:http_listen_port: 9080grpc_listen_port: 0positions:filename: /tmp/positions.yamlclients:- url: http://loki:3100/loki/api/v1/pushscrape_configs:- job_name: systemstatic_configs:- targets:- localhostlabels:job: varlogs__path__: /var/log/*log -
docker-compose.yml修改service挂载部分:
version: "3"services:# 日志存储和解析loki:image: grafana/lokicontainer_name: lpg-lokivolumes:- /opt/docker/loki/:/etc/loki/# 修改loki默认配置文件路径command: -config.file=/etc/loki/loki.ymlports:- 3100:3100# 日志收集器promtail:image: grafana/promtailcontainer_name: lpg-promtailvolumes:# 将需要收集的日志所在目录挂载到promtail容器中- /opt/logs/health-center/:/var/log/- /opt/docker/promtail:/etc/promtail/# 修改promtail默认配置文件路径command: -config.file=/etc/promtail/promtail.yml# 日志可视化grafana:image: grafana/grafanacontainer_name: lpg-grafanaports:- 3000:3000 -
我的目录结构
部署踩坑
-
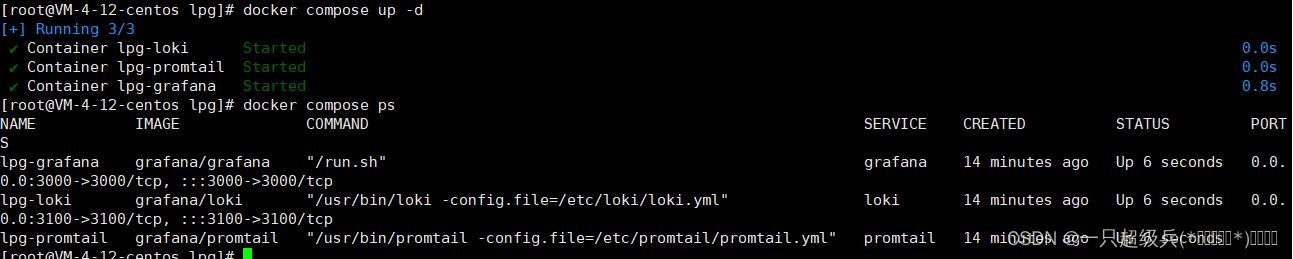
cd到docker-compose.yml目录下,后台运行
docker compose up -d,第一次拉取镜像较久踩坑过程中我注意到直接后台运行然后用logs命令来看日志会更好一些
-
完事之后先来几个命令校验:
docker compose ps,发现只有promtail是运行的
docker compose logs loki,看一下loki日志,提到日期解析异常的问题:
经过一顿gpt,发现是loki配置中的日期没有按照yyyy-MM-dd的格式,于是修改loki配置:
schema_config:configs:- from: 2021-09-08store: boltdb-shipperobject_store: filesystemschema: v11index:prefix: index_period: 24h完事后先
docker compose stop停下来,再重跑一次,然后查看进程,发现,还是loki起不来
查看日志,这次是这样:
一顿gpt后他说可能是什么目录权限问题,不过网上找到更简便的方式,只需要在loki中添加一句(wal):
ingester:lifecycler:address: 127.0.0.1ring:kvstore:store: inmemoryreplication_factor: 1final_sleep: 0schunk_idle_period: 1h # 此时没有接收到新日志的任何块都将被刷新max_chunk_age: 1h # 所有的块将刷新时,他们达到这个年龄,默认是1hchunk_target_size: 1048576 # Loki将尝试构建最大为1.5MB的块,如果先达到chunk_idle_period或max_chunk_age,则首先刷新chunk_retain_period: 30s # 如果使用索引缓存,必须大于索引读缓存TTL(默认索引读缓存TTL为5m)max_transfer_retries: 0 # 块传输禁用wal:dir: /loki/.cache/loki/wal/还是重来一次,暂停,启动,检查进程,这次可以了。
-
后续就是上grafana配置loki了。
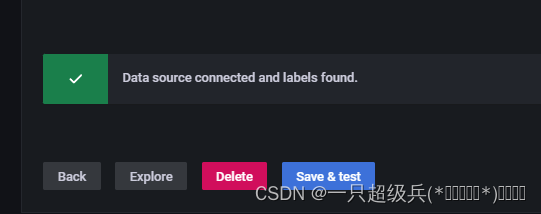
配置的时候也遇到一个大坑了,就是保存测试的时候提示:
Data source connected, but no labels received. Verify that Loki and Promtail is configured properly.
之后一顿搜索,看了github一篇又一篇,检查日志没有问题,检查挂载路径没有问题,3100端口也正常访问。最后在网上看到说加点日志就解决了,果然,在promtail放日志的目录下添加新的日志,再test,就检测到了。
-
后续继续研究多目录收集以及多机器日志收集,踩了坑再继续复盘。
这篇关于Docker上部署LPG(loki+promtail+grafana)踩坑复盘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








