本文主要是介绍Elasticsearch:文本分析器剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Elasticsearch 中的分析器是一个软件模块,主要负责两个功能:tokenization (分词化) 和 normalization(规范化)。 Elasticsearch 采用分词化和规范化过程,因此文本字段被彻底分析并存储在倒排索引中以进行高级查询匹配。 在深入剖析分析器之前,让我们从较高的层次看一下这些概念。
Tokenization
Tokenization,也即分词化是将句子拆分成单个单词的过程,它遵循一定的规则。 例如,我们可以指示进程按分隔符(例如空格、字母、模式或其他标准)来打断句子。 这个过程由一个称为分词器(tokenizer)的组件执行,它的唯一工作是在将句子分解为单词时遵循一定的规则将句子分解为称为分词(token)的单个单词。 在分词化过程中通常使用空格分词器(whitespace tokenizer),句子中的每个单词都由空格分隔,删除任何标点符号和其他非字符。
POST _analyze
{"text": "I like Beijing, China","analyzer": "whitespace"
}结果:[I, like, Beijing, China]
单词也可以根据非字母、冒号或其他一些自定义分隔符进行拆分。 例如,一位影评人的评价是,“The movie was sick!!! Hilarious :) :)” 可以拆分成单独的词:“The”、“movie”、“was”、“sick”、“Hilarious” 等(注意这些词尚未小写)。 或者 “picked-peppers” 可以分词为 “picked” 和“peppers”,“K8s” 可以分词为 “K” 和“s”,等等。 虽然这有助于搜索单词(单个或组合),但它只能回答所有查询,例如具有同义词、复数和我们前面提到的其他搜索的查询。 规范化(normalization)过程将从这里进行分析到下一阶段。
Normalization
规范化是以词干提取、同义词、停用词和其他特征的形式对分词(词)进行处理、转换、修改和丰富的地方。 这里是将附加功能添加到分析过程的地方,以确保数据被适当地存储以用于搜索目的。 一个这样的特征是词干提取:词干提取是一种将单词缩减(词干化)为其根词的操作。 例如,“author” 是 “authors”、“authoring” 和 “authored” 的词根。
除了词干提取之外,规范化还涉及在将它们添加到倒排索引之前找到合适的同义词。 例如,“author” 可能有其他同义词,如 “wordsmith”、“novelist”、“writer”等。 最后,每个文档都会有一些词,例如 “a”、“an”、“and”、“is”、“but”、“the” 等等,这些词被称为停用词(stop words),因为它们确实没有一个地方可以找到相关文件,因为这些词太普遍了。
这两个功能 —— 分词化和规范化 —— 都是由分析器模块执行的。 分析器通过使用过滤器和分词器来做到这一点。 让我们剖析分析器模块,看看它是由什么构成的。
分析器的剖析
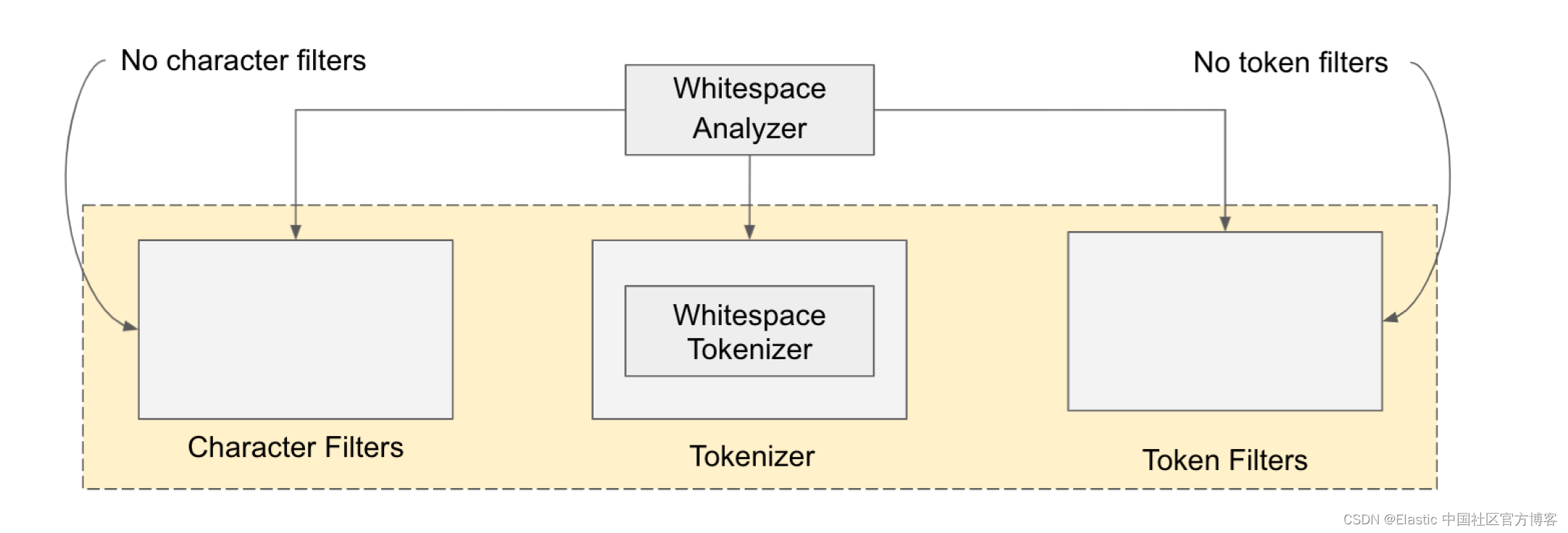
分词化和规范化基本上由三个软件组件执行:字符过滤器、分词器和分词过滤器 —— 它们基本上被粘合为一个分析器模块。 如下图所示,分析器模块由一组过滤器和一个分词器组成。 过滤器既可以在原始文本上作为字符过滤器使用,也可以在标记化文本上作为分词过滤器使用。 分词器(tokenizer)的工作是将句子拆分成单独的词(分词)。
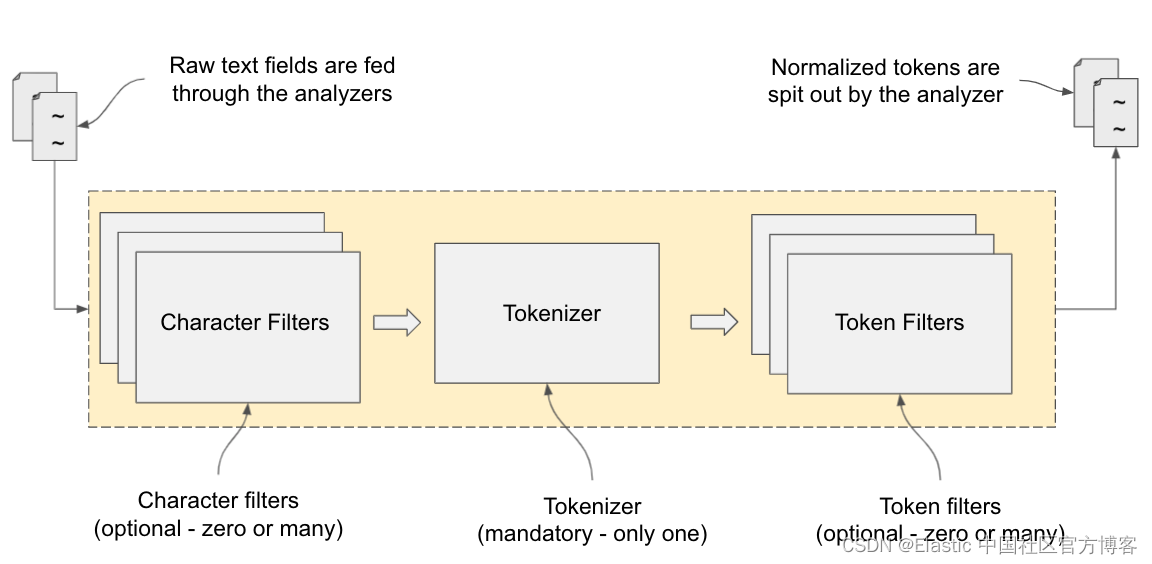
所有文本字段都通过此管道:原始文本由字符过滤器清理,并将生成的文本传递给分词器。 然后分词器将文本拆分为分词(也称作单个单词)。 然后,分词通过分词过滤器进行修改、丰富和增强。 最后,最终确定的分词将存储在适当的倒排索引中。 搜索查询也以与文本索引相同的方式进行分析。
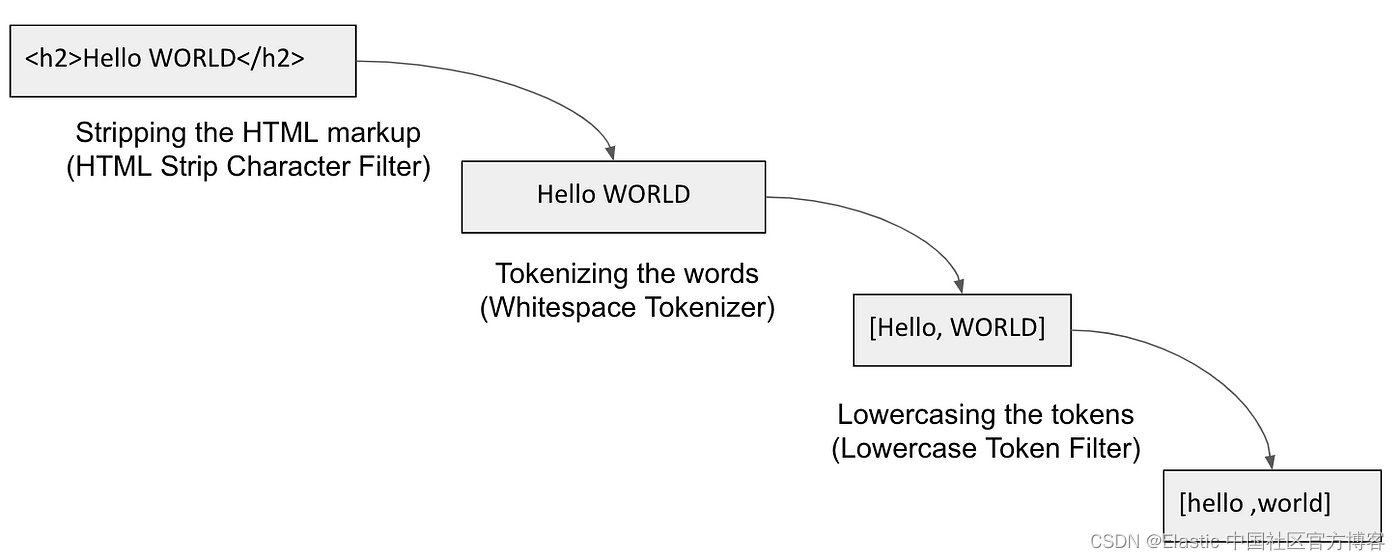
下图显示了一个解释分析过程的示例。
分析器由三个底层构建块组成。 这些都是:
- 字符过滤器(Character filters)—— 应用于字符级别,文本的每个字符都通过这些过滤器。
- 过滤器的工作是从文本字符串中删除不需要的字符。 例如,此过程可以从输入文本中清除 <h1>、<href>、<src> 等 HTML 标记。 它还有助于用其他文本替换某些文本(例如,希腊字母与等效的英语单词)或匹配正则表达式 (regex) 中的某些文本并将其替换为等效文本(例如,基于正则表达式匹配电子邮件并提取组织域)。 这些字符过滤器是可选的; 分析器可以在没有字符过滤器的情况下存在。 Elasticsearch 提供了三种开箱即用的字符过滤器:html_strip、mapping 和 pattern_replace。
- 分词器(tokenizer)—— 使用分隔符(例如空格、标点符号或某种形式的单词边界)将句子拆分为单词。更多分词器的描述,请参阅文章 “Elasticsearch: analyzer”
- 每个分析器(analyer)必须有一个且只有一个分词器。 Elasticsearch 提供了一些这样的分词器来帮助将传入的文本拆分成单独的分词。 然后可以将这些词输入分词过滤器以进一步规范化。 Elasticsearch 默认使用标准分析器(stanard analyzer),它根据语法和标点符号来分解单词。
- 分词过滤器(token filter) —— 处理由分词器生成的分词以进行进一步处理。 例如,分词可以更改大小写、创建同义词、提供词根(词干提取)或生成 n-gram 和 shingles 等。
- 分词过滤器是可选的。 它们可以是零个或多个,与分析器模块相关联。 Elasticsearch 开箱即用地提供了一长串分词过滤器。
请注意,字符和标记过滤器都是可选的,但我们必须有一个分词器。
更多阅读:
-
Elasticsearch:分词器中的 normalizer 使用案例
-
Elasticsearch: analyzer
-
Elasticsearch:词分析中的 Normalizer 的使用
这篇关于Elasticsearch:文本分析器剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





