本文主要是介绍异构图 Link 预测 理论与DGL 源码实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
异构图 Link 预测 理论与DGL 源码实战
文章源码下载地址:点我下载http://inf.zhihang.info/resources/pay/7692.html
书接上文,在上文 重磅好文透彻理解,异构图上 Node 分类理论与DGL源码实战 中,我们讲了 异构图节点分类回归 任务,而在以前的系列文章中,我们也陆续介绍了 同构图上的节点分类回归任务、边分类回归任务以及链接预测 任务。接着以前的写作印记,这一篇就该是 异构图上链接预测任务 了,一起来看看吧 ~ go go go
(1) 异构图上链接预测基础理解
链接预测,顾名思义,就是 图中边是否存在 的预测,本质上是把建模成二分类任务,来预测边存在的概率。但是 实际存在的边与随机采样的边 构建成了正负样本,外界不需要输入标签,学习的是 图结构自身 的信息,这里我们把归结为 无监督机器学习 。在 GraphSage与DGL实现同构图 Link 预测,通俗易懂好文强推 中,我们详细介绍了 同构图上的链接预测 ,把类推到异构图上即可。在异构图上进行链接预测,我们使用考虑边两侧的节点的Embeding信息,依据其 相似性与相关性等因素 ,来对 边的存在与否 进行判断。
这里 需要注意 的是:虽然是用的 边两侧的2个节点 的信息,但是从 训练多轮次 来看,依据 我们以前文章 介绍的知识 来理解,这2个节点也是 均融合的周围节点的局部结构与全局性质 的并结合图上空间结构做出的判断。
从 GraphSage与DGL实现同构图 Link 预测,通俗易懂好文强推 中,我们也了解到 图上链接预测属于 无监督机器学习,这和上一篇文章介绍的异构图上节点分类回归预测任务的不同非常相似,不同仅仅是在我们需要对链接预测进行 负边的采样。注意这里是 边采样, 而上文用的是节点采样,接口是不一样的,同时这两个任务的 损失与预测打分 函数也是不同的。
上文 我们已经说过 链接预测 是无监督机器学习,外界不用输入标签,模型学习的其实是基于图的自身结构与数据特性来判断边是否存在的机器学习任务。基于此,我们应该明白: 既然学习的是图上的某边是否存在,则我们仅仅 建图的时候提供各类节点的关系来建图 即可,可以依据用户历史行为日志来构建异构图的边,例如用户购买了某件商品就有用户-》购买-〉商品的关系存在,就可以构建一条边。
依据实际存在的节点关系建边构成正样本,而图上随机采样的边组成负样本,基于 间隔比较近的节点特性也相似的 同源偏好假设 来构建损失进行模型训练 ,可以说是 图上链接(关系)预测的精髓 了。而链接预测也是现在的很多互联网大厂 使用的最多的一种 建模方式 ,不需要显示的 标签 就可以学习到 需要 的 各类节点 的 Embeding, 非常 nice !!!
以前的文章对 同构/异构图 的各种机器学习任务均进行了 详细的阐述,本文这里就不在继续赘述了。
感兴趣的同学可以去 作者公众号 上去 阅读历史文章。这里我们直接开始本节 基于DGL和RGCN实现的异构图上 链接预测 机器学习任务的代码介绍吧~
(2) 代码时光
为了提高文章的 可读性与降低理解难度 ,也保持每一篇 文章的 相对对立性 ,让读者从任何一篇文章进来都是一篇完整的文章,本文和上文重复的代码,这里依然会 赘述 着进行介绍。阅读过上一篇文章的同学可以自行跳过哈,下面,就让我们开始coding 吧~
开篇先吼一嗓子 , talk is cheap , show me the code !!!
本文的代码讲的是 基于DGL和RGCN实现的异构图上链接预测 任务,整个源码流程是一个 小型的工业可用的工程 ,基于dgl实现,觉得有用赶紧 收藏转发 吧~
(2.1) 数据准备 (和上文相同)
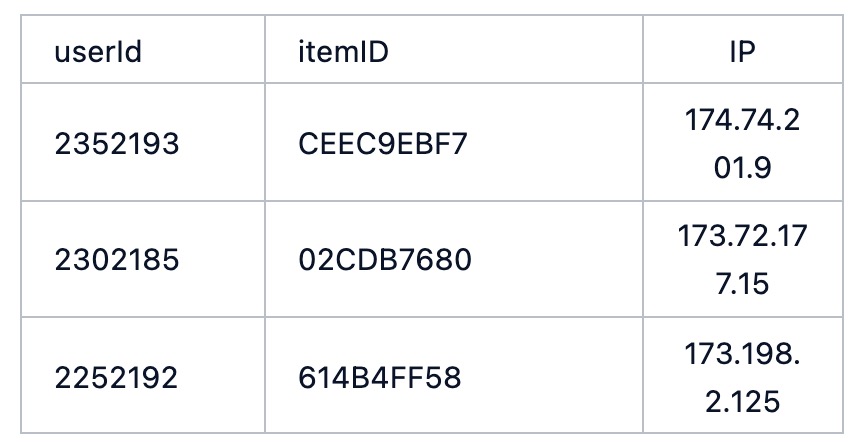
我们 假设 可以输入类似于这样的数据, 其中每2列对应这一种关系,例如 用户2352193 购买了商品CEEC9EBF7,用户用了IP 174.74.201.9登录了账号,用户用IP 174.74.201.9 购买了商品 CEEC9EBF7, 最终的 链接任务预测是预测用户的购买意愿,用户到该商品之间,是否会有边存在
更 常规的一种用法 是,基于无监督的训练,得到图上 各个节点的 Embeding ,这是非常有价值的中间数据产出,可以为我们其他的机器学习任务提供有力辅助。
我们可以把这样一份数据存入 source_data.csv 文件中,用 pandas 接口把数据读入:
graph_features_pdf = pd.read_csv('./source_data.csv')
因为对于异构图模型,节点和边的类型均有多种,为了处理方便,我们可以把各种类型的节点进行编码,再到后期对其进行解码,对 pandas 的 dataframe 数据结构的编解码,我们可以使用下面的代码:
@ 欢迎关注微信公众号:算法全栈之路#编码方法
def encode_map(input_array):p_map={}length=len(input_array)for index, ele in zip(range(length),input_array):# print(ele,index)p_map[str(ele)] = indexreturn p_map#解码方法
def decode_map(encode_map):de_map={}for k,v in encode_map.items():# index,ele de_map[v]=kreturn de_map然后用其中的各列node 进行 编码
@ 欢迎关注微信公众号:算法全栈之路userid_encode_map=encode_map(set(graph_features_pdf['user_id'].values))# 解码map
userid_decode_map=decode_map(userid_encode_map)
graph_features_pdf['user_id_encoded'] = graph_features_pdf['user_id'].apply(lambda e: userid_encode_map.get(str(e),-1))
# print unique值的个数
userid_count=len(set(graph_features_pdf['user_id_encoded'].values))
print(userid_count)# user login ip
u_e_ip_src = final_graph_features_pdf['user_id_encoded'].values
u_e_ip_dst = final_graph_features_pdf['ip_encoded'].values
u_e_ip_count = len(u_e_ip_dst)
print("u_e_ip_count", u_e_ip_count)# user buy item
u_e_item_src = final_graph_features_pdf['user_id_encoded'].values
u_e_item_dst = final_graph_features_pdf['item_id_encoded'].values
u_e_item_count = len(u_e_item_dst)
print("u_e_item_count", u_e_item_count)
这里仅仅以 用户节点编码 为例,itemId和 IP 同理编解码即可。注意: 这里的 u_e_ip_count,u_e_item_count 在下文有用到。
最后我们可以把图数据保存,供以后的异构图代码 demo使用。
`@ 欢迎关注微信公众号:算法全栈之路
final_graph_pdf=graph_features_pdf[[‘user_id_encoded’,‘ip_encoded’,‘item_id_encoded’,‘label’]].sort_values(by=‘user_id_encoded’, ascending=True)
final_graph_pdf.to_csv(‘result_label.csv’,index=False)`
基于此,异构图的基础准备数据就结束了,下面开始正式的coding了。
(2.2) 导包 (和上文相同)
老规矩,先导包,基于DGL和RGCN实现的异构图上链接预测任务只需要这些包就可以了。
@ 欢迎关注微信公众号:算法全栈之路import argparse
import torch
import torch.nn as nn
import dgl
import torch.optim as optim
from dgl.dataloading import MultiLayerFullNeighborSampler, EdgeDataLoader
from dgl.dataloading.negative_sampler import Uniform
import numpy as np
import pandas as pd
import itertools
import os
import tqdm
from dgl import save_graphs, load_graphs
import dgl.function as fn
import torch
import dgl
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv, SAGEConv, HeteroGraphConv
from dgl.utils import expand_as_pair
import tqdm
from collections import defaultdict
import torch as th
import dgl.nn as dglnn
from dgl.data.utils import makedirs, save_info, load_info
from sklearn.metrics import roc_auc_score
import gc
gc.collect()推荐一个工具,tqdm 很好用哦,结合 dataloading接口, 可以看到模型训练以及数据处理执行的进度,赶紧用起来吧~
各种模型工具无所谓分类,能解决问题的就是好工具,混用又有何不可呢? 实用就行!
(2.3) 构图
数据有了,接下来就是构图了,我们构建的是包含三种节点的异构图。
@ 欢迎关注微信公众号:算法全栈之路# user 登录 ip
u_e_ip_src = final_graph_pdf['user_id_encoded'].values
u_e_ip_dst = final_graph_pdf['ip_encoded'].values
# user 购买 item
u_e_item_src = final_graph_pdf['user_id_encoded'].values
u_e_item_dst = final_graph_pdf['item_id_encoded'].values
# item和ip 共同出现
ip_e_item_src = final_graph_pdf['ip_encoded'].values
ip_e_item_dst = final_graph_pdf['item_id_encoded'].values
# user 购买 label
user_node_buy_label = final_graph_pdf['label'].valueshetero_graph = dgl.heterograph({('user', 'u_e_ip', 'ip'): (u_e_ip_src, u_e_ip_dst),('ip', 'u_eby_ip', 'user'): (u_e_ip_dst, u_e_ip_src),('user', 'u_e_item', 'item'): (u_e_item_src, u_e_item_dst),('item', 'u_eby_item', 'user'): (u_e_item_dst, u_e_item_src),('ip', 'ip_e_item', 'item'): (ip_e_item_src, ip_e_item_dst),('item', 'item_eby_ip', 'ip'): (ip_e_item_dst, ip_e_item_src)
})# 注意:这里的代码本文是不需要的
# 这里是链接预测任务,是无监督机器学习,不需要标签,这里没有删除,仅仅注释起来,方便对比上一篇文章的代码
# 给 user node 添加标签
# hetero_graph.nodes['user'].data['label'] = torch.tensor(user_node_buy_label)print(hetero_graph)
这里异构图是无向图,因为无向,所以双向 ,构图的时候就 需要构建双向的边 ,代码很好理解,就不再赘述了哈。
这里和上文不同的是,这里是无监督机器学习任务,不需要对用户节点的边进行 label 赋值 。我这里仅仅是把注释起来哈。这里是不需要的。
(2.4) 模型的自定义函数
这里定义了 异构图上RGCN 会用到的模型的一系列自定义函数,终点看代码注释,结合上文第一小节的抽象理解,希望你能看明白哦。
@ 欢迎关注微信公众号:算法全栈之路class RelGraphConvLayer(nn.Module):def __init__(self,in_feat,out_feat,rel_names,num_bases,*,weight=True,bias=True,activation=None,self_loop=False,dropout=0.0):super(RelGraphConvLayer, self).__init__()self.in_feat = in_featself.out_feat = out_featself.rel_names = rel_namesself.num_bases = num_basesself.bias = biasself.activation = activationself.self_loop = self_loop# 这个地方只是起到计算的作用, 不保存数据self.conv = HeteroGraphConv({# graph conv 里面有模型参数weight,如果外边不传进去的话,里面新建# 相当于模型加了一层全链接, 对每一种类型的边计算卷积rel: GraphConv(in_feat, out_feat, norm='right', weight=False, bias=False)for rel in rel_names})self.use_weight = weightself.use_basis = num_bases < len(self.rel_names) and weightif self.use_weight:if self.use_basis:self.basis = dglnn.WeightBasis((in_feat, out_feat), num_bases, len(self.rel_names))else:# 每个关系,又一个weight,全连接层self.weight = nn.Parameter(th.Tensor(len(self.rel_names), in_feat, out_feat))nn.init.xavier_uniform_(self.weight, gain=nn.init.calculate_gain('relu'))# biasif bias:self.h_bias = nn.Parameter(th.Tensor(out_feat))nn.init.zeros_(self.h_bias)# weight for self loopif self.self_loop:self.loop_weight = nn.Parameter(th.Tensor(in_feat, out_feat))nn.init.xavier_uniform_(self.loop_weight,gain=nn.init.calculate_gain('relu'))self.dropout = nn.Dropout(dropout)def forward(self, g, inputs):g = g.local_var()if self.use_weight:weight = self.basis() if self.use_basis else self.weight# 这每个关系对应一个权重矩阵对应输入维度和输出维度wdict = {self.rel_names[i]: {'weight': w.squeeze(0)}for i, w in enumerate(th.split(weight, 1, dim=0))}else:wdict = {}if g.is_block:inputs_src = inputsinputs_dst = {k: v[:g.number_of_dst_nodes(k)] for k, v in inputs.items()}else:inputs_src = inputs_dst = inputs# 多类型的边结点卷积完成后的输出# 输入的是blocks 和 embedinghs = self.conv(g, inputs, mod_kwargs=wdict)def _apply(ntype, h):if self.self_loop:h = h + th.matmul(inputs_dst[ntype], self.loop_weight)if self.bias:h = h + self.h_biasif self.activation:h = self.activation(h)return self.dropout(h)#return {ntype: _apply(ntype, h) for ntype, h in hs.items()}class RelGraphEmbed(nn.Module):r"""Embedding layer for featureless heterograph."""def __init__(self,g,embed_size,embed_name='embed',activation=None,dropout=0.0):super(RelGraphEmbed, self).__init__()self.g = gself.embed_size = embed_sizeself.embed_name = embed_nameself.activation = activationself.dropout = nn.Dropout(dropout)# create weight embeddings for each node for each relationself.embeds = nn.ParameterDict()for ntype in g.ntypes:embed = nn.Parameter(torch.Tensor(g.number_of_nodes(ntype), self.embed_size))nn.init.xavier_uniform_(embed, gain=nn.init.calculate_gain('relu'))self.embeds[ntype] = embeddef forward(self, block=None):return self.embedsclass EntityClassify(nn.Module):def __init__(self,g,h_dim, out_dim,num_bases=-1,num_hidden_layers=1,dropout=0,use_self_loop=False):super(EntityClassify, self).__init__()self.g = gself.h_dim = h_dimself.out_dim = out_dimself.rel_names = list(set(g.etypes))self.rel_names.sort()if num_bases < 0 or num_bases > len(self.rel_names):self.num_bases = len(self.rel_names)else:self.num_bases = num_basesself.num_hidden_layers = num_hidden_layersself.dropout = dropoutself.use_self_loop = use_self_loopself.embed_layer = RelGraphEmbed(g, self.h_dim)self.layers = nn.ModuleList()# i2hself.layers.append(RelGraphConvLayer(self.h_dim, self.h_dim, self.rel_names,self.num_bases, activation=F.relu, self_loop=self.use_self_loop,dropout=self.dropout, weight=False))# h2h , 这里不添加隐层,只用2层卷积# for i in range(self.num_hidden_layers):# self.layers.append(RelGraphConvLayer(# self.h_dim, self.h_dim, self.rel_names,# self.num_bases, activation=F.relu, self_loop=self.use_self_loop,# dropout=self.dropout))# h2oself.layers.append(RelGraphConvLayer(self.h_dim, self.out_dim, self.rel_names,self.num_bases, activation=None,self_loop=self.use_self_loop))# 输入 blocks,embedingdef forward(self, h=None, blocks=None):if h is None:# full graph trainingh = self.embed_layer()if blocks is None:# full graph trainingfor layer in self.layers:h = layer(self.g, h)else:# minibatch training# 输入 blocks,embedingfor layer, block in zip(self.layers, blocks):h = layer(block, h)return hdef inference(self, g, batch_size, device="cpu", num_workers=0, x=None):if x is None:x = self.embed_layer()for l, layer in enumerate(self.layers):y = {k: th.zeros(g.number_of_nodes(k),self.h_dim if l != len(self.layers) - 1 else self.out_dim)for k in g.ntypes}sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1)dataloader = dgl.dataloading.NodeDataLoader(g,{k: th.arange(g.number_of_nodes(k)) for k in g.ntypes},sampler,batch_size=batch_size,shuffle=True,drop_last=False,num_workers=num_workers)for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader):# print(input_nodes)block = blocks[0].to(device)h = {k: x[k][input_nodes[k]].to(device) for k in input_nodes.keys()}h = layer(block, h)for k in h.keys():y[k][output_nodes[k]] = h[k].cpu()x = yreturn y上面的代码主要分为三大块:分别是 RelGraphConvLayer、 RelGraphEmbed 以及 EntityClassify。
首先就是:RelGraphConvLayer 。我们可以看到 RelGraphConvLayer 就是我们的 异构图卷积层layer, 其主要是调用了DGL实现的 HeteroGraphConv算子,从上面第一小节我们也详细阐述了 异构图卷积算子其实就是 对各种关系分别进行卷积然后进行同类型的节点的融合。
这里我们需要重点关注 的是:RelGraphConvLayer层的返回 ,从代码中,我们可以看到,对于每种节点类型是返回了一个Embeding, 维度是 out_feat。如果是带了激活函数的,则是返回激活后的一定维度的一个tensor。
过来是 RelGraphEmbed。 从代码中可以看到: 这个python类仅仅返回了一个字典,但是这个字典里却包括了 多个 Embeding Variable, 注意这里的 Variable 均是可以 随着网络训练变化更新 的。我们可以根据节点类型,节点ID取得对应元素的 Embeding 。 这种实现方法是不是解决了前文 GraphSage与DGL实现同构图 Link 预测,通俗易懂好文强推 和 基于GCN和DGL实现的图上 node 分类, 值得一看!!! 所提到的 动态更新的Embeding 的问题呢。
最后就是 EntityClassify类 了,我们可以看到 这个就是最终的模型RGCN结构了,包括了模型训练的 forward 和用于推断的inference方法 。这里的 inference 可以用于 各个节点的embedding的导出, 我们在后文有实例代码,接着看下去吧~
注意看 forword 方法里的 for layer, block in zip(self.layers, blocks) 这个位置, 这里就是我们前一小节所说的 采样层数和模型的卷积层数目是相同的说法 的由来,可以结合上文说明理解源码哦。
(2.5) 模型采样超参与边采样介绍
注意: 这里的采样是边采样,和上一篇文章不同 ,具体看代码。
@ 欢迎关注微信公众号:算法全栈之路# 根据节点类型和节点ID抽取embeding 参与模型训练更新
def extract_embed(node_embed, input_nodes):emb = {}for ntype, nid in input_nodes.items():nid = input_nodes[ntype]emb[ntype] = node_embed[ntype][nid]return emb# 采样定义
neg_sample_count = 1
batch_size=20480
# 采样2层全部节点
sampler = MultiLayerFullNeighborSampler(2)
# 边的条数,数目比顶点个数多很多.
# 这是 EdgeDataLoader 数据加载器
hetero_graph.edges['u_e_ip'].data['train_mask'] = torch.zeros(u_e_ip_count, dtype=torch.bool).bernoulli(1.0)
train_ip_eids = hetero_graph.edges['u_e_ip'].data['train_mask'].nonzero(as_tuple=True)[0]
ip_dataloader = EdgeDataLoader(hetero_graph, {'u_e_ip': train_ip_eids}, sampler, negative_sampler=Uniform(neg_sample_count), batch_size=batch_size
)hetero_graph.edges['u_e_item'].data['train_mask'] = torch.zeros(u_e_item_count, dtype=torch.bool).bernoulli(1.0)
train_item_eids = hetero_graph.edges['u_e_item'].data['train_mask'].nonzero(as_tuple=True)[0]
item_dataloader = EdgeDataLoader(hetero_graph, {'u_e_item': train_item_eids}, sampler, negative_sampler=Uniform(neg_sample_count), batch_size=batch_size
)这里的代码作者花了大量时间进行优化,注释和组织形式 尽量写的非常清晰,非常容易理解。
我们这里选择了 EdgeDataLoader 来进行训练数据的读入,这其实是一种分batch训练 的方法,而不是一次性把图全读入内存进行训练,而是每次选择batch的种子节点 真实边构成的pos graph 以及 种子节点和他们随机采样的全局节点组成的neg graph 读入内存参与训练,这也让大的图神经网络训练成为了可能,是 DGL图深度框架 非常优秀的实现 !!! 大赞 !
这里 EdgeDataLoader 采样算法也和 negative_sampler 与 sampler 结合使用,其中 sampler 采样了2层全部邻居作为正样本,而 negative_sampler 则是对不存在的边进行构建,起点也是种子节点,而终点则是 全局随机采样得到的 。
注意读者在里的边采样可以上一篇文章 重磅好文透彻理解,异构图上 Node 分类理论与DGL源码实战 中的节点采样对比查看,可以加深理解哦~
(2.6) 模型结构定义与 损失函数说明
三个类的方法定义,和节点分类任务有差异的地方,可以看看~
@ 欢迎关注微信公众号:算法全栈之路# Define a Heterograph Conv model
class Model(nn.Module):def __init__(self, graph, hidden_feat_dim, out_feat_dim):super().__init__()self.rgcn = EntityClassify(graph,hidden_feat_dim,out_feat_dim)self.pred = HeteroDotProductPredictor()def forward(self, h, pos_g, neg_g, blocks, etype):h = self.rgcn(h, blocks)return self.pred(pos_g, h, etype), self.pred(neg_g, h, etype)class MarginLoss(nn.Module):def forward(self, pos_score, neg_score):# 求损失的平均值 , view 改变tensor 的形状# 1- pos_score + neg_score ,应该是 -pos 符号越大变成越小 +neg_score 越小越好return (1 - pos_score + neg_score.view(pos_score.shape[0], -1)).clamp(min=0).mean()class HeteroDotProductPredictor(nn.Module):def forward(self, graph, h, etype):# 在计算之外更新h,保存为全局可用# h contains the node representations for each edge type computed from node_clf_hetero.pywith graph.local_scope():graph.ndata['h'] = h # assigns 'h' of all node types in one shotgraph.apply_edges(fn.u_dot_v('h', 'h', 'score'), etype=etype)return graph.edges[etype].data['score']这里的三个类函数 Model、MarginLoss、HeteroDotProductPredictor 均是非常重要的。
首先是 model , 我们可以看到 这里的model 分别引入了 EntityClassify 和 HeteroDotProductPredictor ,这两个函数分别定义了 模型的结构与损失 。EntityClassify 和 上一文 介绍的一模一样,这里不在赘述了。
接着是 MarginLoss ,可以看到 MarginLoss 就是我们前文讲过的基于 同源性假设 设计的损失,HeteroDotProductPredictor 则是基于两端节点信息 计算边是否存在 的函数,可以 从同构图推断到异构图 中去,和 GraphSage与DGL实现同构图 Link 预测,通俗易懂好文强推 中一样,本文也不在进行赘述 了。
(2.7) 模型训练超参与单epoch训练
代码是表达程序员思想的最好语言,直接看代码吧!
@ 欢迎关注微信公众号:算法全栈之路# in_feats = hetero_graph.nodes['user'].data['feature'].shape[1]
hidden_feat_dim = n_hetero_features
out_feat_dim = n_hetero_featuresembed_layer = RelGraphEmbed(hetero_graph, hidden_feat_dim)
all_node_embed = embed_layer()model = Model(hetero_graph, hidden_feat_dim, out_feat_dim)
# 优化模型所有参数,主要是weight以及输入的embeding参数
all_params = itertools.chain(model.parameters(), embed_layer.parameters())
optimizer = torch.optim.Adam(all_params, lr=0.01, weight_decay=0)loss_func = MarginLoss()def train_etype_one_epoch(etype, spec_dataloader):losses = []# input nodes 为 采样的subgraph中的所有的节点的集合for input_nodes, pos_g, neg_g, blocks in tqdm.tqdm(spec_dataloader):emb = extract_embed(all_node_embed, input_nodes)pos_score, neg_score = model(emb, pos_g, neg_g, blocks, etype)loss = loss_func(pos_score, neg_score)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()print('{:s} Epoch {:d} | Loss {:.4f}'.format(etype, epoch, sum(losses) / len(losses)))这里我们定义了模型结构,损失采用的是 上文定义的 MarginLoss , 这里需要注意的是 spec_dataloader 返回值,这里是 边采样 ,返回和节点采样的dataloader是 不一样的。
其他的代码非常容易理解,有问题欢迎去公众号联系讨论~
(2.8) 模型多种节点训练
@ 欢迎关注微信公众号:算法全栈之路# 开始train 模型
for epoch in range(1):print("start epoch:", epoch)model.train()train_etype_one_epoch('u_e_ip', ip_dataloader)train_etype_one_epoch('u_e_item', item_dataloader)从代码中我们可以知道:
对于异构图,其实我们也是以 各种类型的节点作为种子节点, 然后进行图上的负边采样,分别进行训练然后更新整个模型结构 的。
(2.7) 模型保存与节点Embeding导出 (和上文相同)
@ 欢迎关注微信公众号:算法全栈之路# 图数据和模型保存
save_graphs("graph.bin", [hetero_graph])
torch.save(model.state_dict(), "model.bin")# 每个结点的embeding,自己初始化,因为参与了训练,这个就是最后每个结点输出的embeding
print("node_embed:", all_node_embed['user'][0])# 模型预估的结果,最后应该使用 inference,这里得到的是logit
# 注意,这里传入 all_node_embed,选择0,选1可能会死锁,最终程序不执行
inference_out = model.inference(hetero_graph, batch_size, 'cpu', num_workers=0, all_node_embed)
print(inference_out["user"].shape)
print(inference_out['user'][0])这里我们可以看到, 我们使用了 model.inference 接口进行模型的 节点 Embeding导出 。
这里需要注意的是: 这个地方 num_workers应该设置0 ,即为不用多线程, 不然会互锁, 导致预估任务不执行 。
这里是深坑啊,反正经过很长时间的纠结和查找,最终发现是这个原因,希望读者可以避免遇到相似的问题 ~
到这里,异构图 Link 预测 理论与DGL 源码实战 的全文就写完了。这一篇文章是为了 图系列文章 的 完整性 而写的一篇文章。相信认真看过作者文章的人,每一篇都不错过的话,到这里修改下网络对他们来说是非常容易的事情。
但是事实上,也确有同学卡在了 异构图链接预测的一些自定义函数 上,不知道如何去实现来进行 链接预测 任务,那就结合本文与上一篇文章以及以前的一篇同构图链接预测的文章一起看看吧,相信你会有很有收获的 ~
上面的代码demo 在环境没问题的情况下,全部 复制到一个python文件 里,就可以完美运行起来。本文的代码是一个 小型的商业可以用 的工程项目,希望可以对你有参考作用 ~
码字不易,觉得有收获就动动小手转载一下吧,你的支持是我写下去的最大动力 ~
更多更全更新内容 : 算法全栈之路
这篇关于异构图 Link 预测 理论与DGL 源码实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




