本文主要是介绍ENVI必须会教程—Sentinel-2数据的读取与波段组合加载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验2:读取Sentinel-2影像
目的:了解Sentinel-2影像读取方法,熟悉各波段及组合
过程:
①读取数据:在标题栏选择“文件”选项,点击“打开为”,选择“光学传感器”,由于哨兵2号数据为欧空局提供,鼠标定位至“European Space Agency”,选择“Sentinel-2”,打开数据文件夹,选择“S2B—”开头的文件夹,即为本次实验需要读取的“Sentinel-2”数据,选择“MTD_MSIL1C.xml”文件,打开。
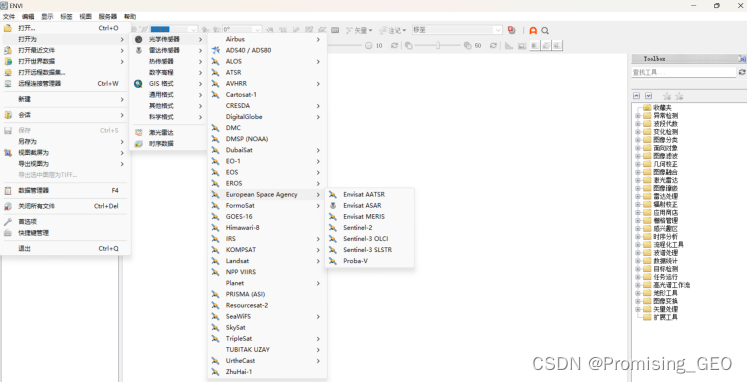
图1
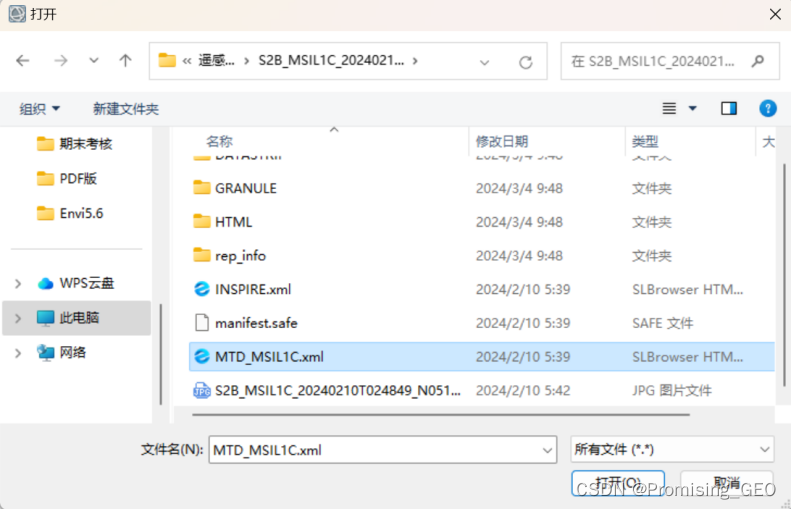
图2
②查看影像的波段信息,选择标题栏的“文件”,点击文件管理器,打开管理窗口,可以查看数据覆盖的波段信息。
③单波段数据加载:选择其中的某个波段,此处选择SWIR2波段,即B12,点击“加载到新视图→加载”,查看单波段影像。
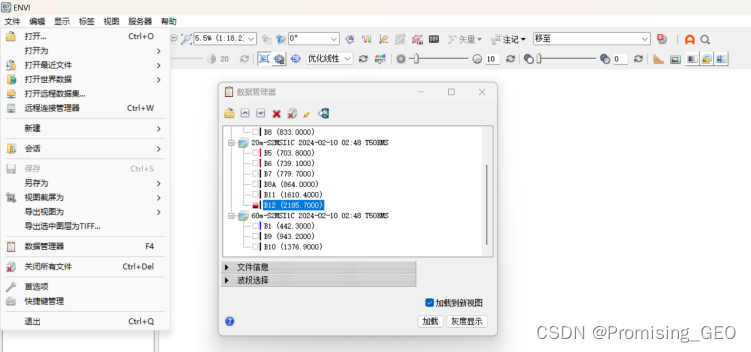
图3
④波段组合数据加载:操作与步骤③类似,进入数据管理器后,选择多个波段进行组合加载即可,此处选择空间分辨率同为10m的B8、B4、B3数据。
结果:
①自然加载:读取Sentinel-2数据,图1显示了ENVI5.6中加载结果,为B4、B3、B2组合形成的自然真彩色影像。从真彩色影像中,可以发现影像覆盖的区域有多个湖泊的水体覆盖(蓝绿色),白色反映了地表的建筑。

图1
②波段查看:图二显示了Sentinel-2数据覆盖的波段,共计13个主要波段(实际上还有3个QA质量波段),需要注意的是,同一时间的不同波段映射的地表空间分辨率是不同的,可分为10m、20m、60m三类。

图2
③单波段数据:图2加载为Sentinel-2的B12数据,即SWIR2映射的地表信息。检测植被在该波段的反射率变化,能够反映植被的健康状况,同时某些SWIR波段对某些矿产有较高的吸收能力,可以用于矿产资源勘探。此外,该波段还可以与其他波段进行组合,用于获取不同的地物信息。
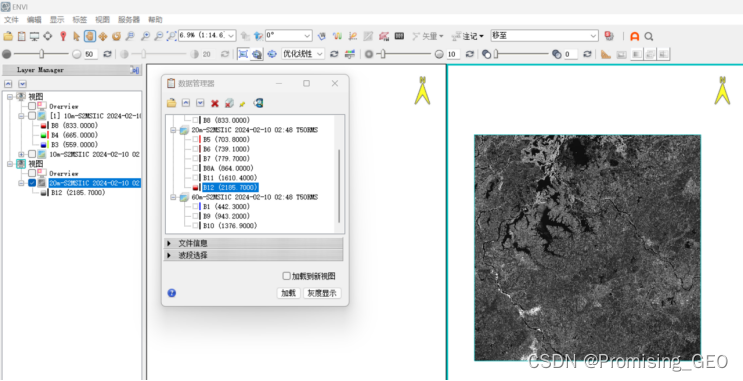
图3
④波段组合:图3中的右影像显示的为B8、B3、B4即近红外波段、红光波段、绿光波段的组合形成的标准假彩色影像。从两张图像的对比来看,相比于真彩色影像,标准假彩色影像可以用来监测植被的健康状况,如下图的大面积红色覆盖区反映在原真彩色影像为深绿色覆盖区域,代表植被分布的密集区域,而颜色偏白的区域则往往代表城市和建筑用地区

图4
问题1:在进行Sentinel-2任意波段组合时,加载影像出错。
出错提示:输入的波段行列号不一致、不支持用行列号不一致的波段生成RGB波段。
问题追溯:农业组合波段常用B11、B8、B2,通过查阅数据管理器,推测是由于B8与B2波段的空间分辨率是10m,而B11波段的空间分辨率是20m,这导致了不同的波段,其像素代表的地面区域不一样,因此波段之间无法合成正常的RGB影像。
解决方法:通过查阅资料,该问题可以通过波段的重采样予以解决,将三个波段重采样,选择合适的插值算法后,统一空间分辨率后可以得到正常的波段组合影像。
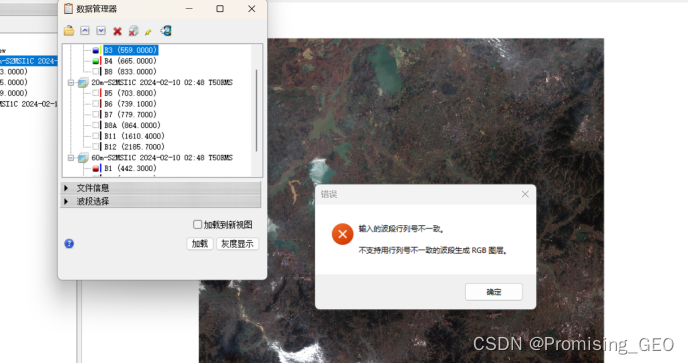
图1
好啦,关于Sentinel-2数据在ENVI中的读取与波段加载的分享到这里就结束了,如果对你有帮助,不要忘记了给小编点赞哦!
这篇关于ENVI必须会教程—Sentinel-2数据的读取与波段组合加载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







