本文主要是介绍【Power Automate】使用CSV文件向SharePoint中批量导入数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SharePoint并没有依照上传的文件内容来向一个List中批量导入数据的能力,但SharePoint倒是有一个根据Excel文件来建表顺便导入数据的能力。
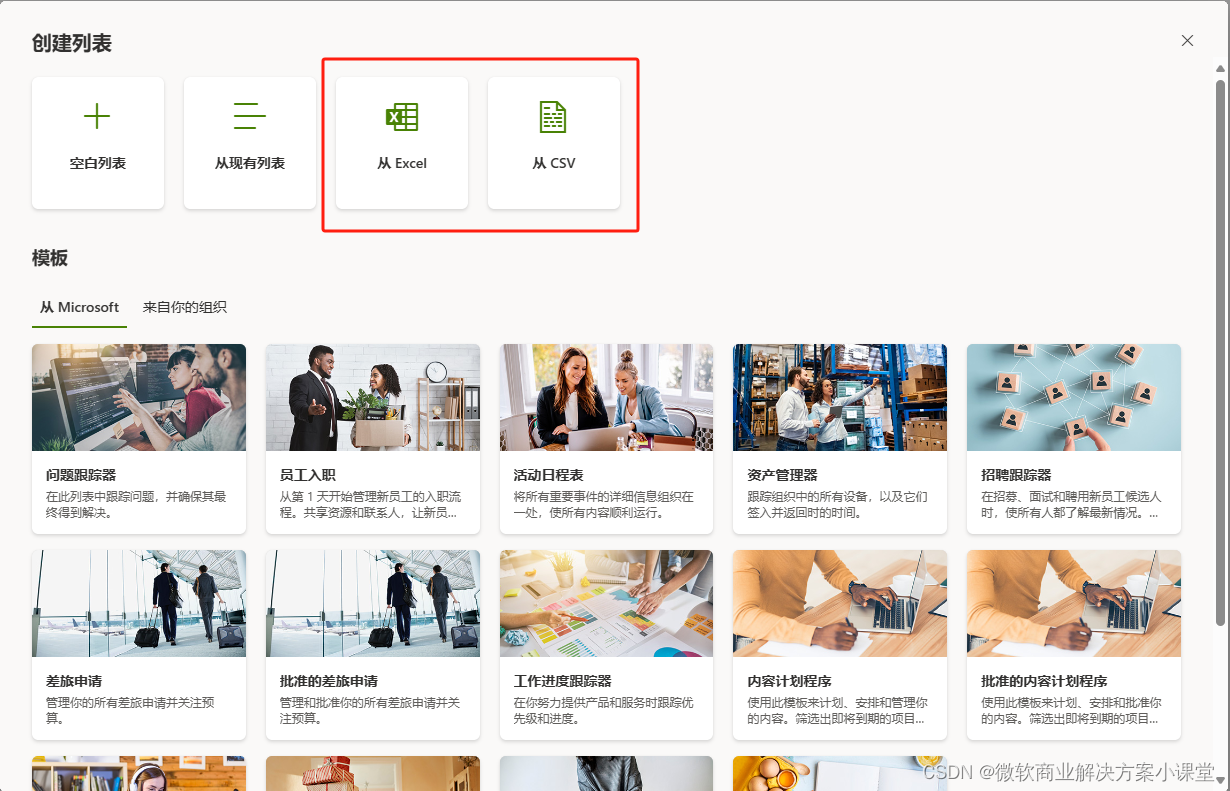
我们在建表的时候选择从Excel文件开始,SharePoint就可以在根据Excel的列建表的同时把表中数据也一块导进这个新表。
不过我们今天要分享的功能是使用csv文件将数据批量导入一个已经存在的SharePoint List。
开始之前我先给一个前提,就是我们上传的文件需要是以逗号分隔的csv文件的格式。
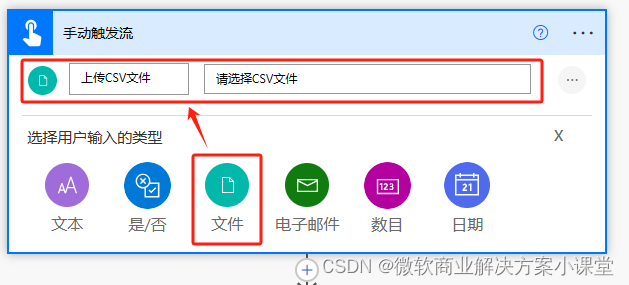
然后我们开始,我们暂时先选择手动触发流,并给触发器设置一个文件类型的参数,用来测试用,等我们把流程搭好了再换成上传文件后自动触发的触发器(如果咱们觉得自动触发不太妥,还可以换成选择文件后手动触发的触发器)。
之后我们需要获取到这个文件的内容,首先,我们把这个文件转成Base64的字符串格式。
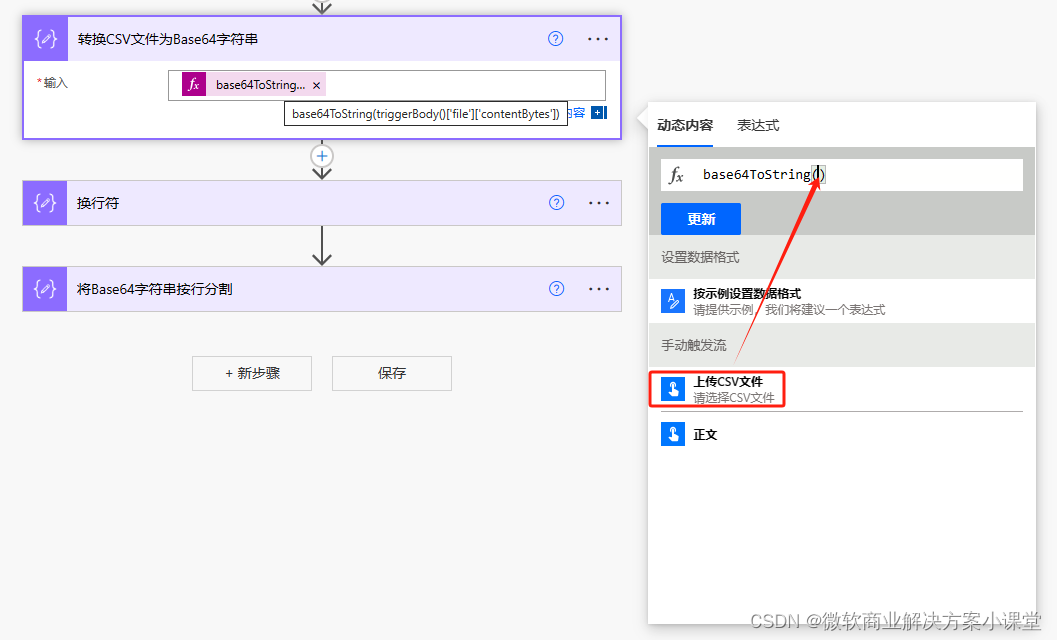
在这种格式下,整个文件的所有内容会被放到一个字符串中,就像这样。
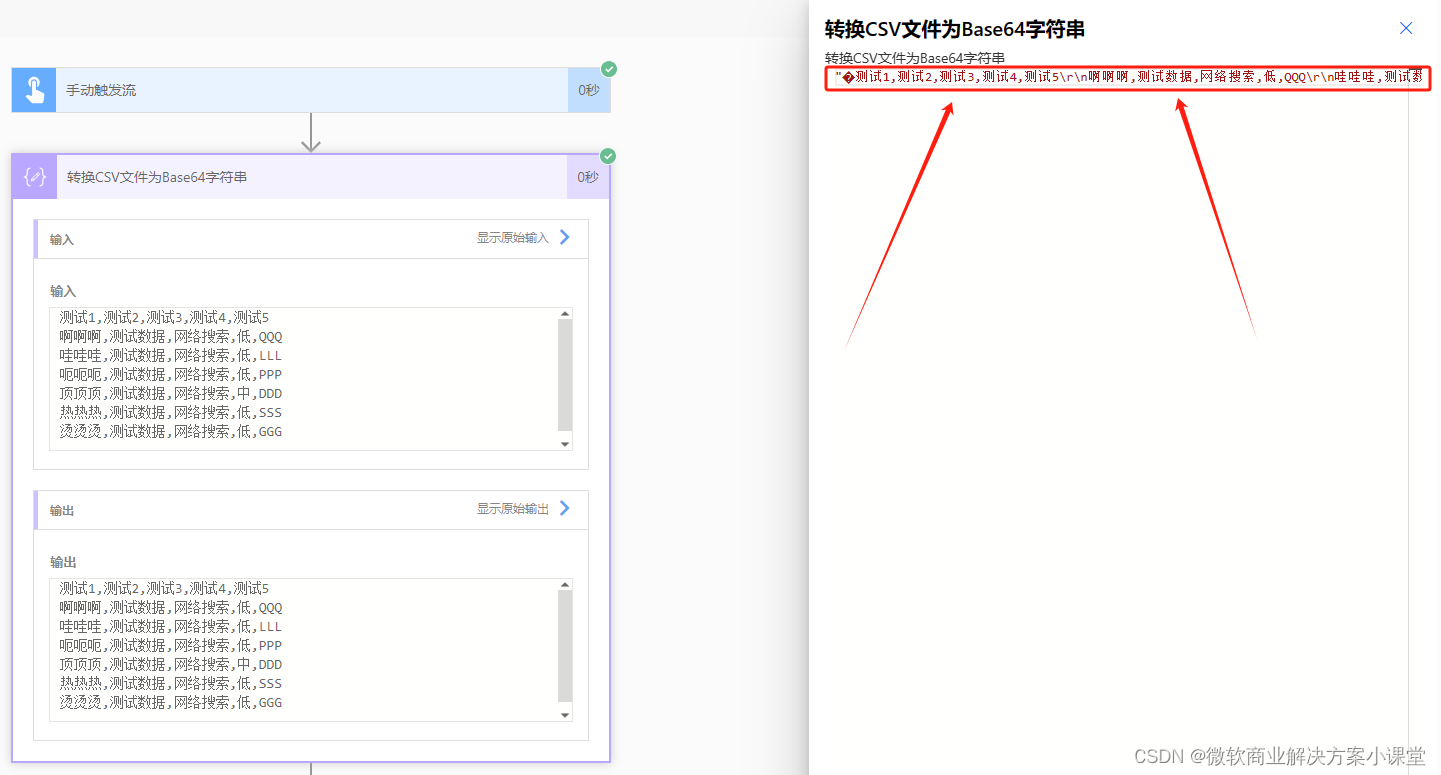
之后我们要做的事就是把每一行的数据给挑出来。
我们可以看到这个字符串中,是存在每一行的换行符的。
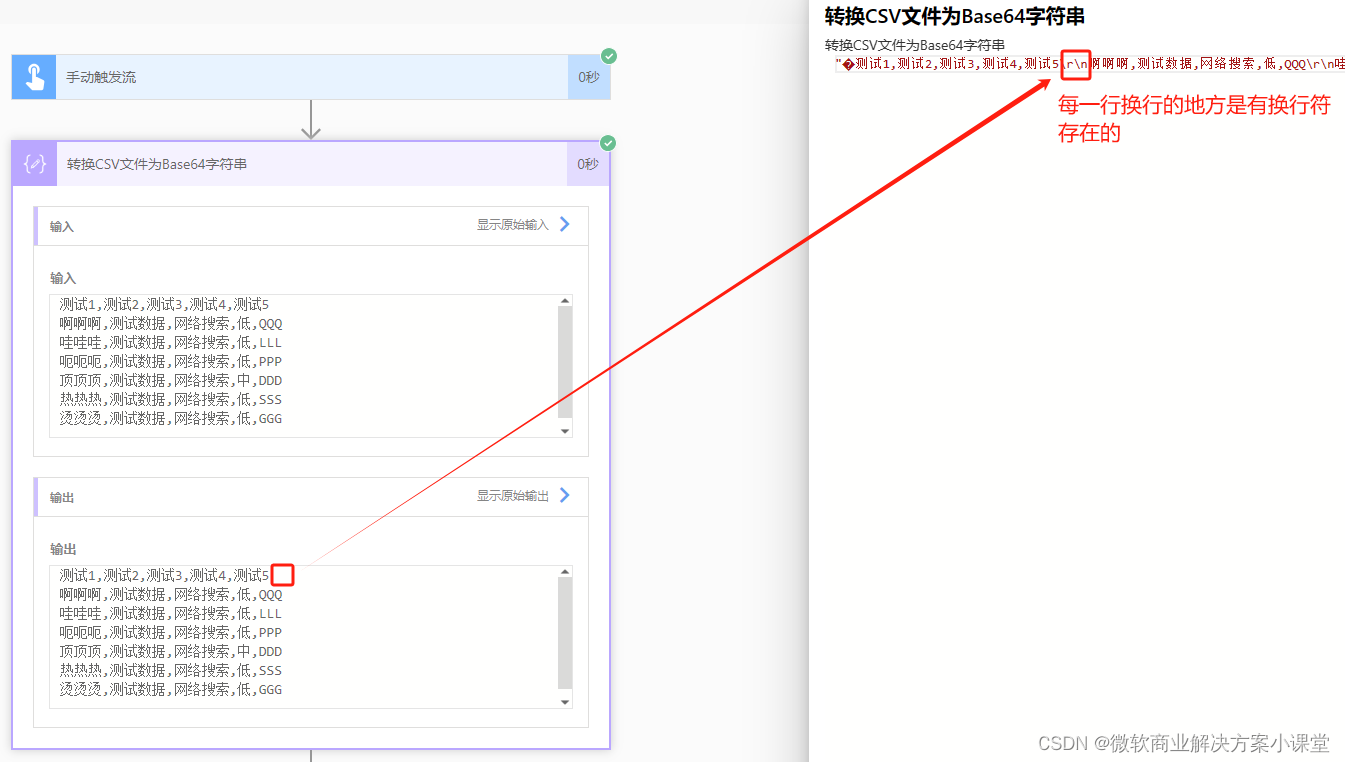
那我们按照换行符来把这个字符串给分割一下就好了。
换行符(\r\n)在Power Automate中可以这样获得。
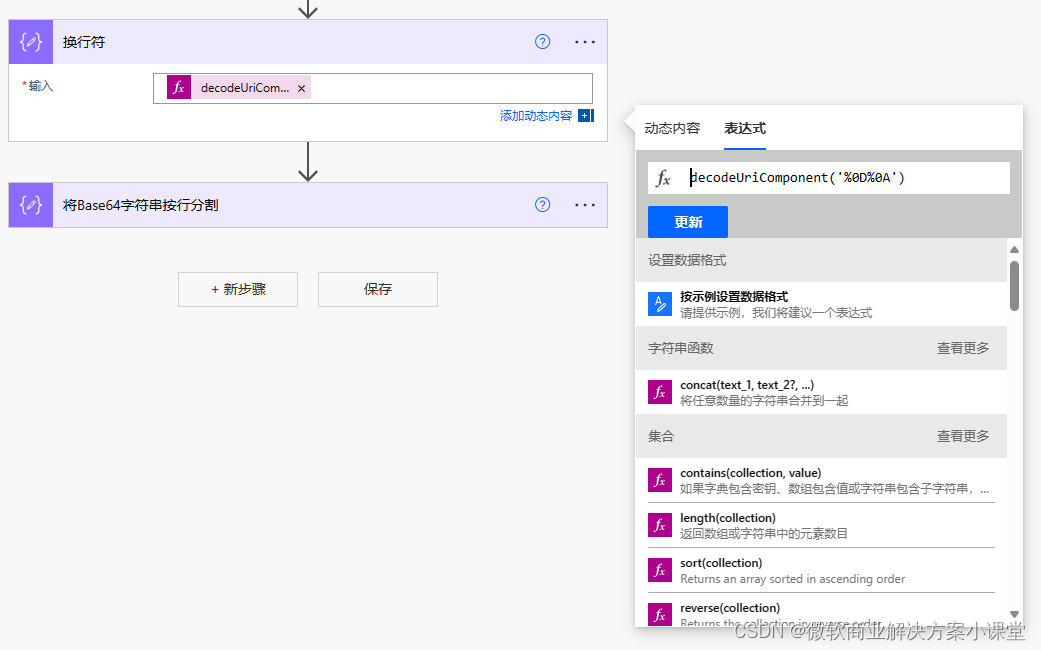
decodeUriComponent('%0D%0A')
然后我们调用split表达式进行分割。
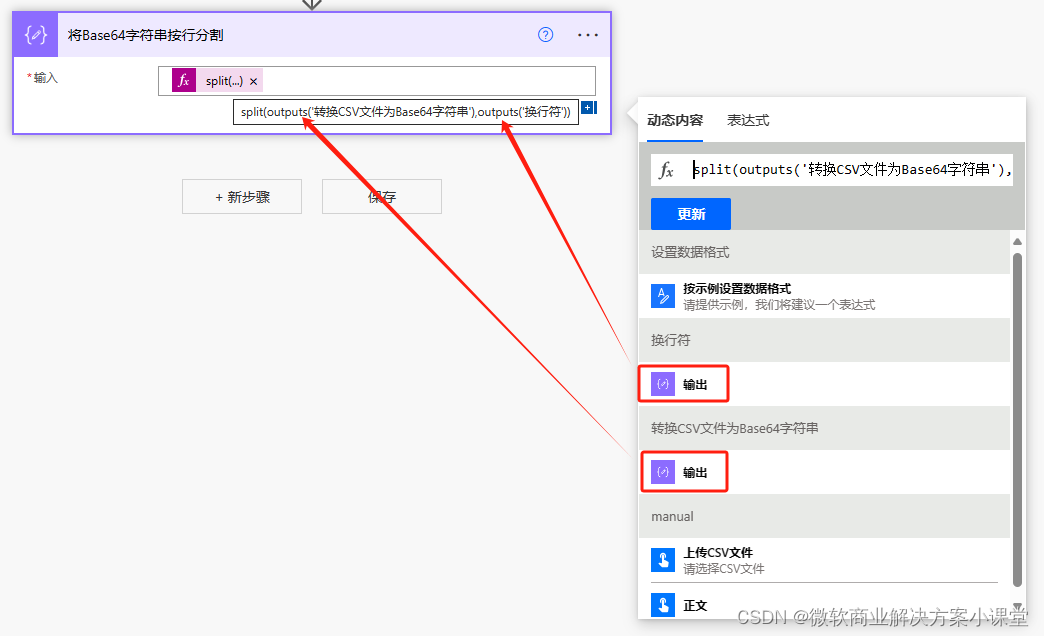
分割以后我们就能拿到一个数组,这个数组的每一个元素就是我们上传的csv文件中的每行数据。
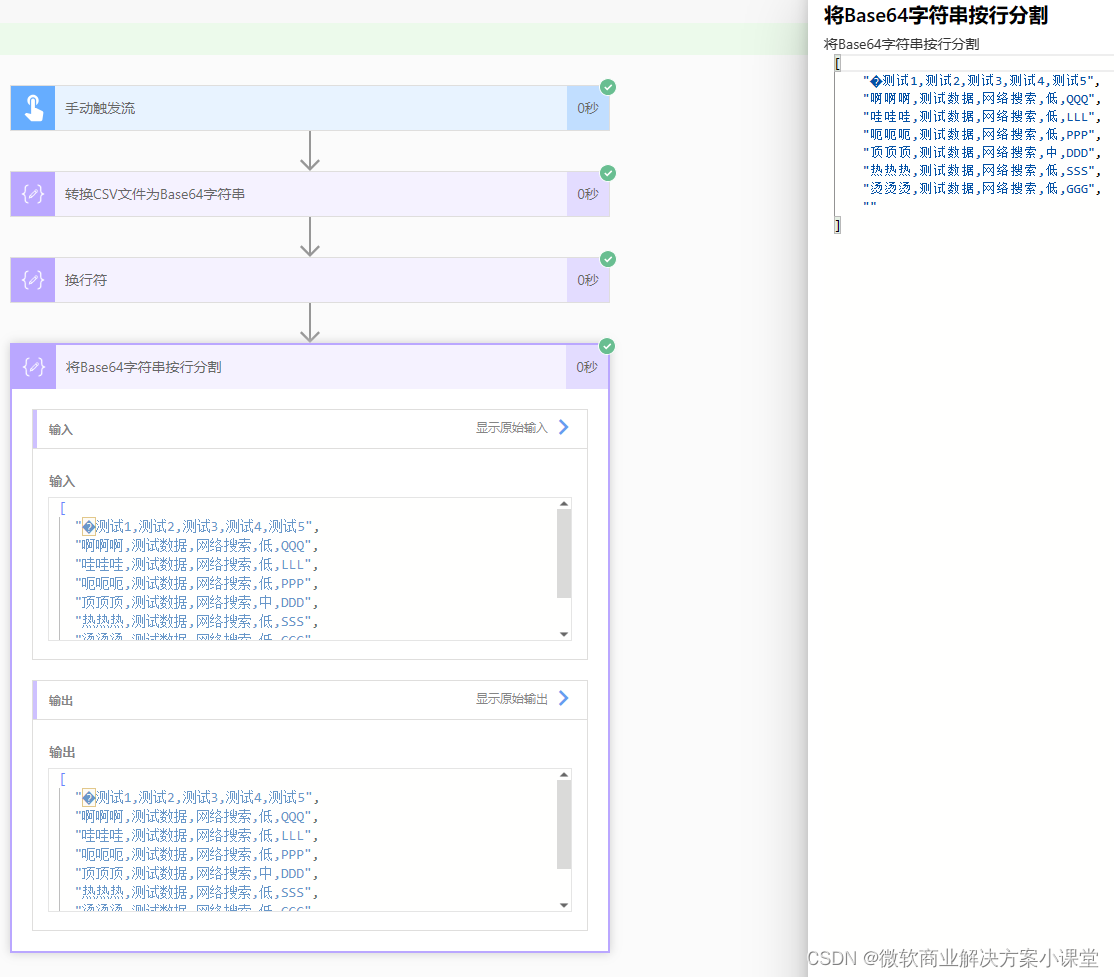
如果我们的csv文件的前几行不是有效数据,而是表头信息或是其他的提示信息,就像这样。

那我们需要剔除掉这几行数据。
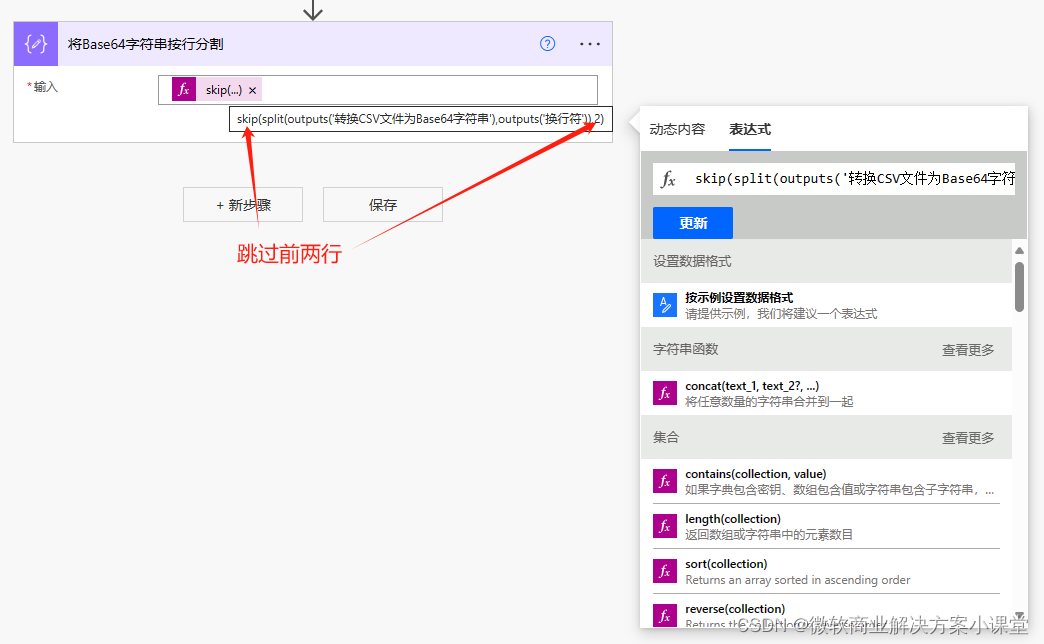
然后我们可以看到,我们那个字符串在分割成数组后,数组最后是有一个空项的,接下来我们需要剔除这个空项。
添加新节点。
筛选数组中不为空的项。
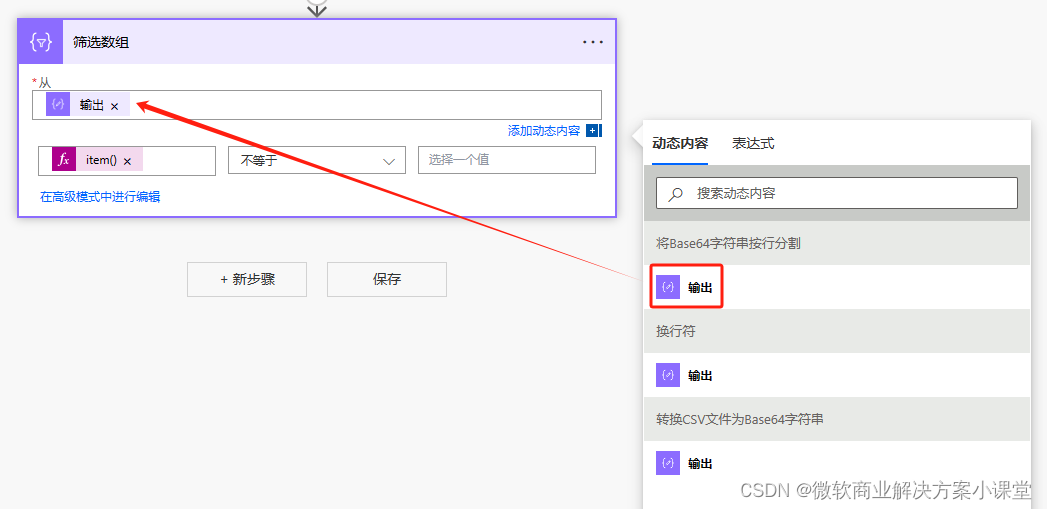
这样最后那个空项就被去掉了。
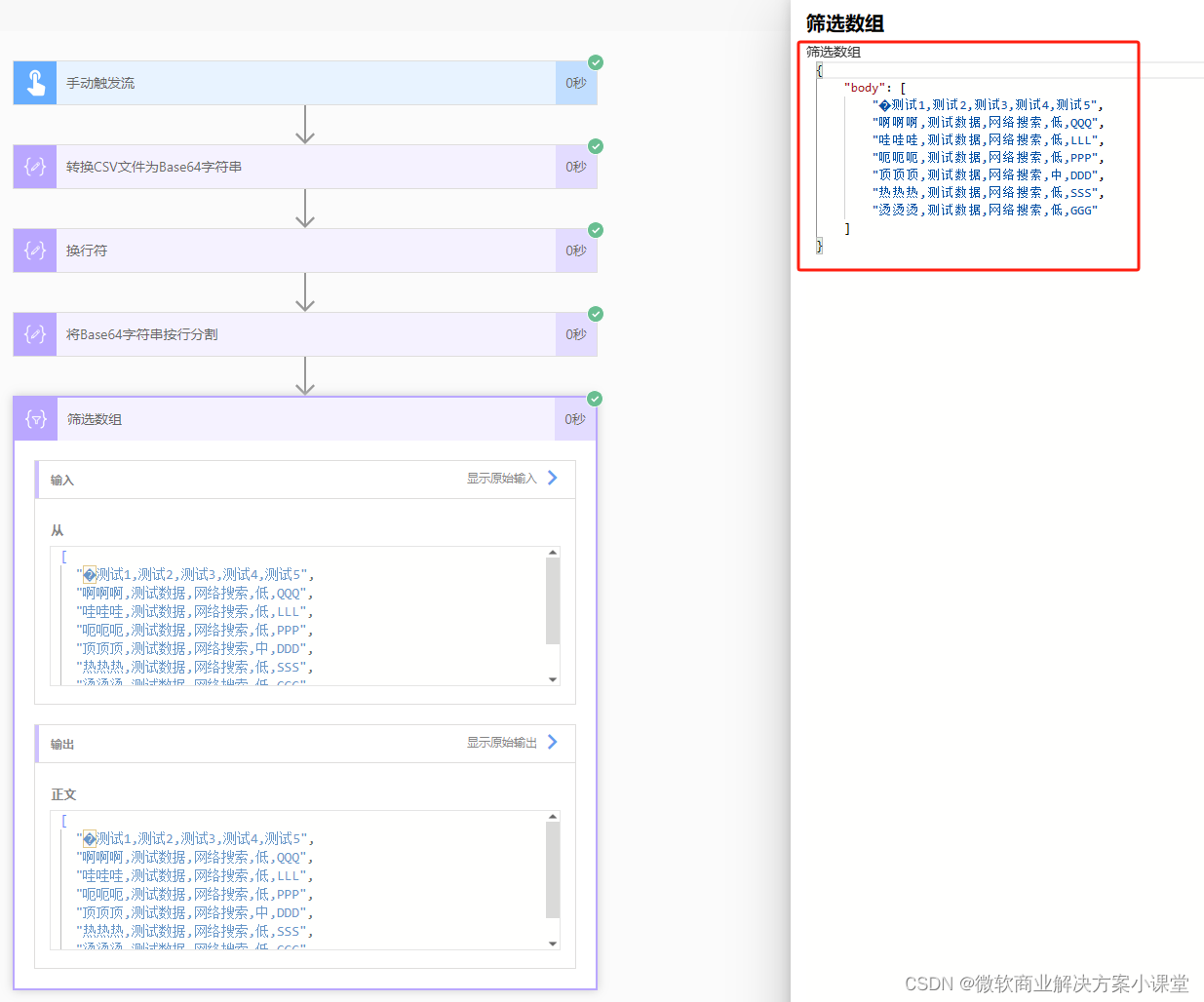
之后我们就可以着手开始把数据往SharePoint List中导了。
放一个遍历节点,遍历我们数组中的每一个元素,然后把每一个元素中对应的数据放到表的字段中即可。
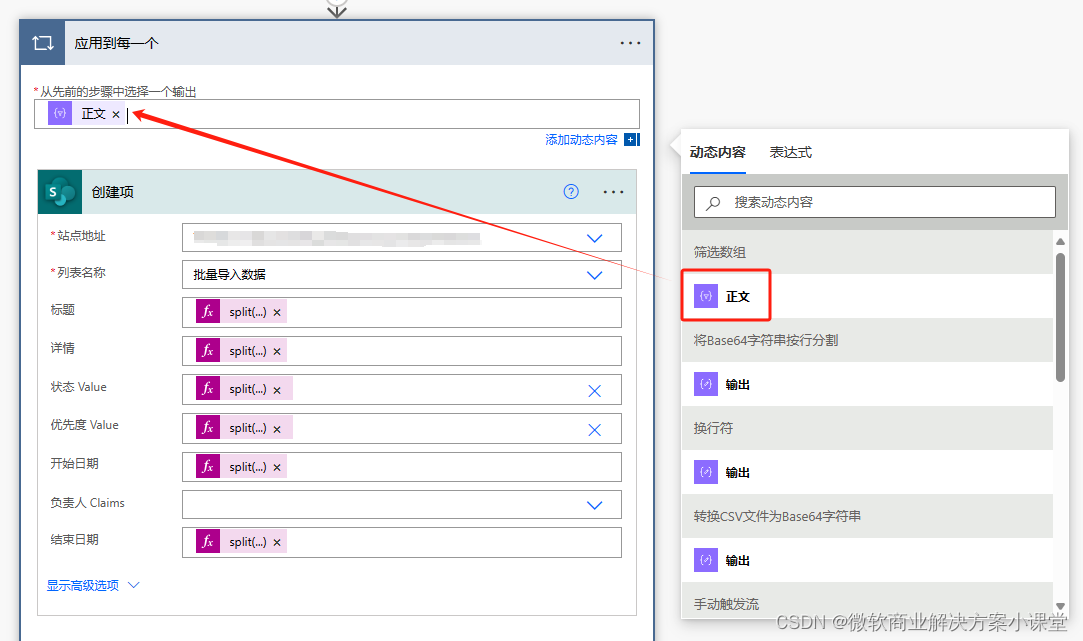
由于我们数组中的每一个元素都还是整个的字符串,所以我们还是需要切字符串,直接根据逗号的位置来切就好了,至于该取哪个下标,那就需要看我们csv表的设计了。

在我们的设计中,标题是第一列,所以在上边那张截图中,取标题的数据需要取切出来的0号下标的值。
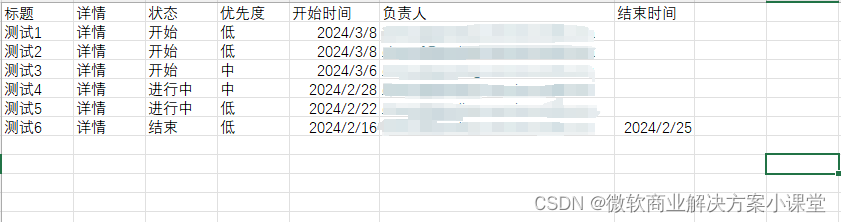
所有类型的数据都是直接取切出来的值就好了,就是人员字段有点不同,我以前也分享过,在Power Automate中,人员字段需要有这么一个前缀。
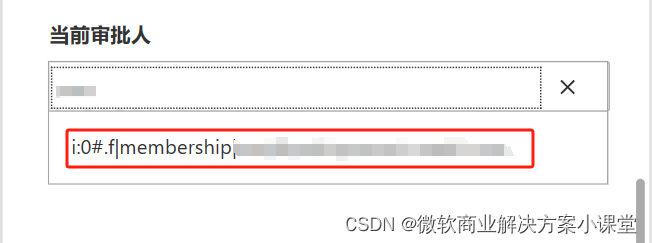
所以我们导入人员字段的时候需要这么写。
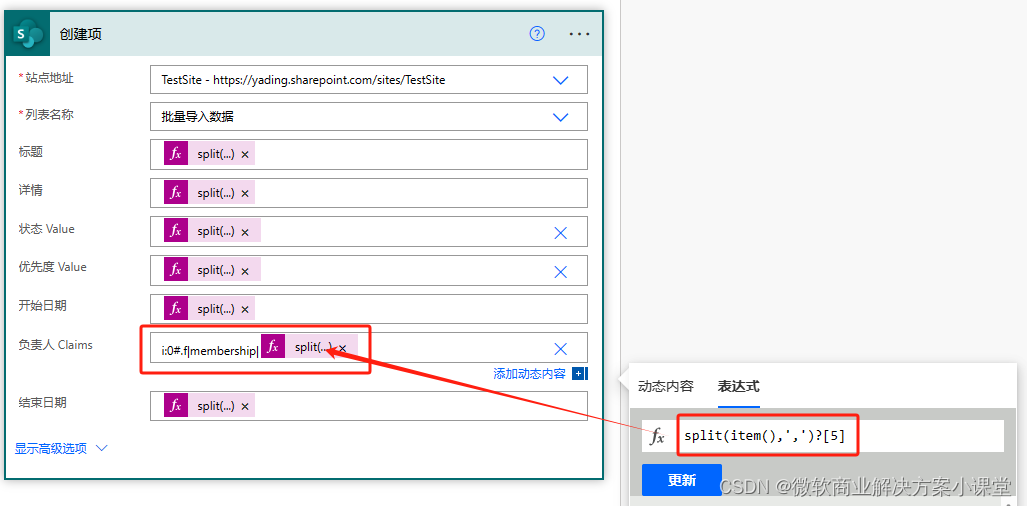
先把前缀加上,再放上我们切出来的人员邮箱地址。
当然,如果我们的人员信息在csv文件中就是按这个格式来的,那直接放上去就好。
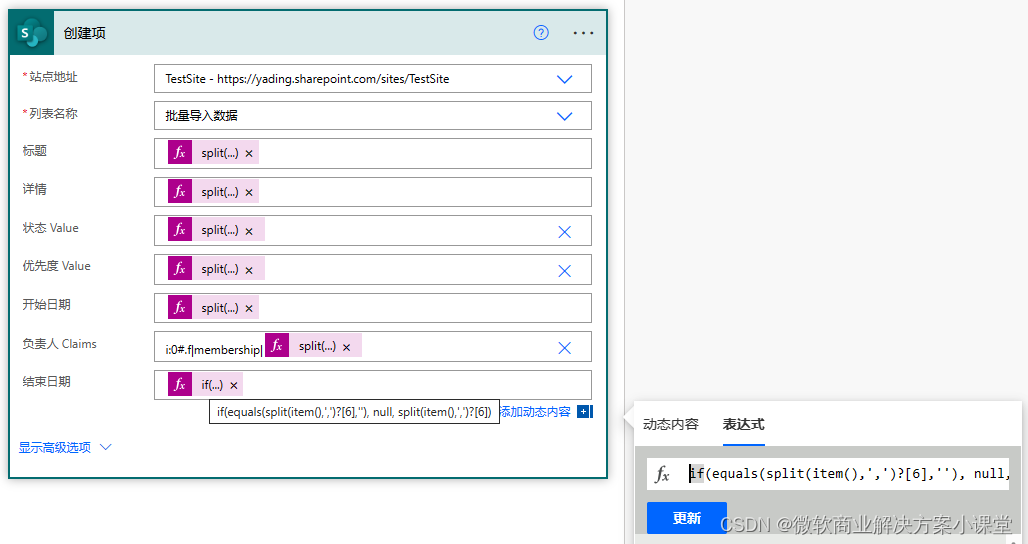
最后我们需要解决一下当数字字段、日期字段、人员字段出现空值时的处理方案,毕竟当csv文件中的这些字段没有值时,SharePoint List将会拿到一个空字符串,这将直接导致流程报数据类型不匹配。
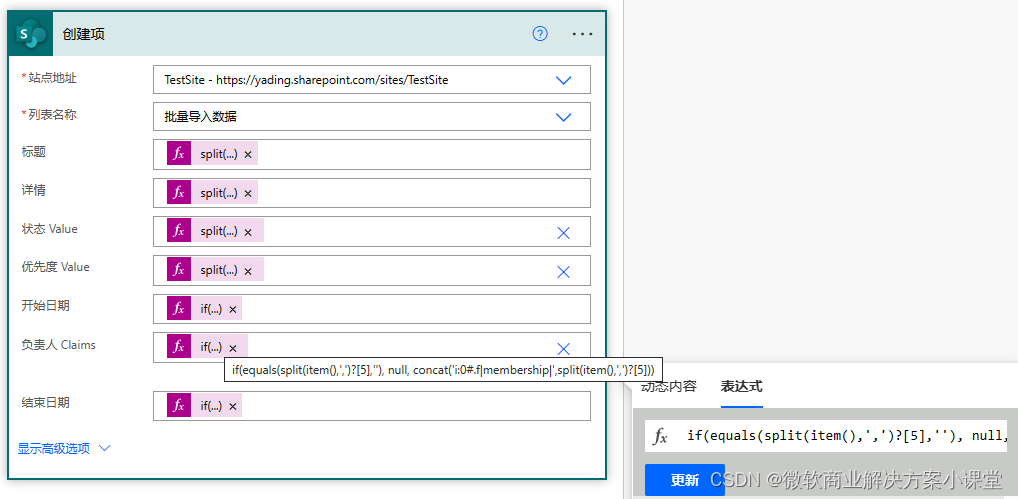
这很好办,当对应的值为空字符串时,返回一个null即可。
注意人员字段,当值不为空的时候需要使用concat表达式把前缀和人员邮箱地址连起来
做完之后就可以测试运行了。
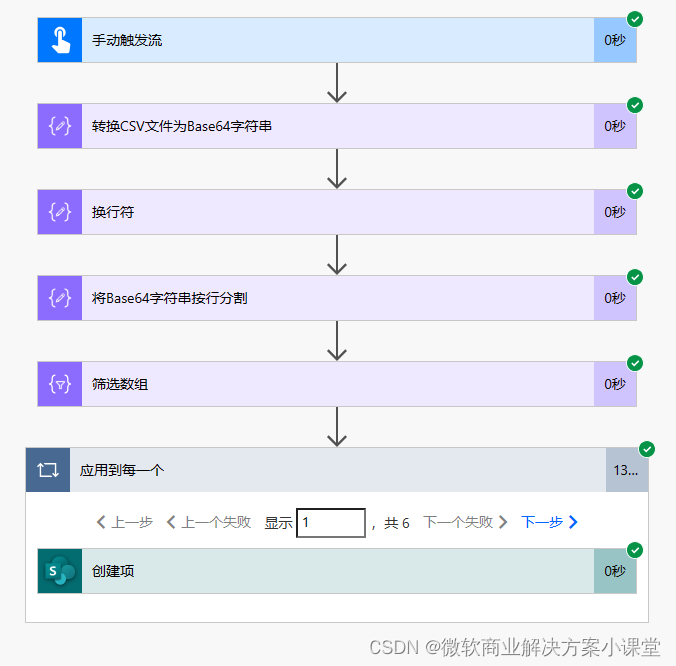
一点毛病没有。

为了加强我们这个流程对大量数据导入时的效率,我们可以把这个遍历节点的并发值拉高一点。
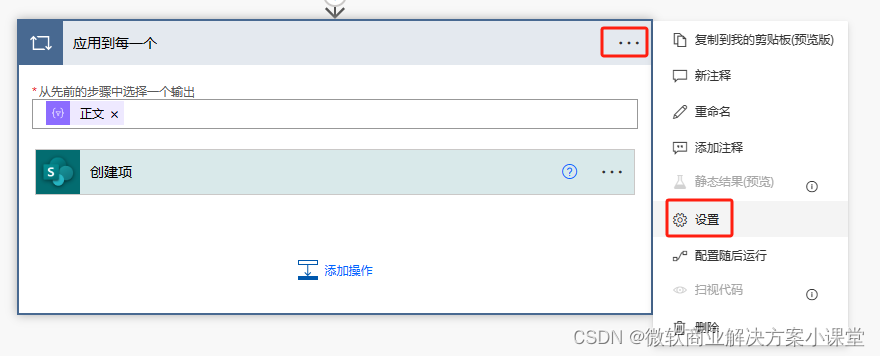
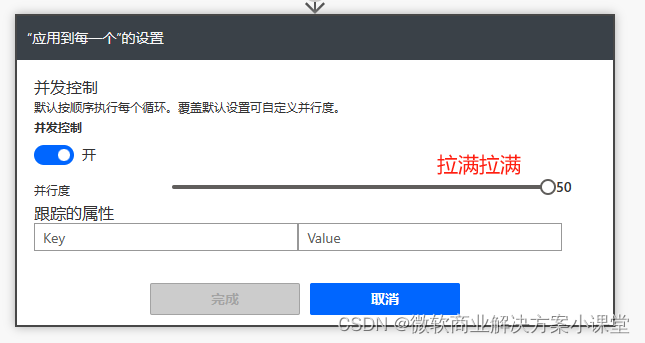
测试没问题之后我们就着手来改触发器了。
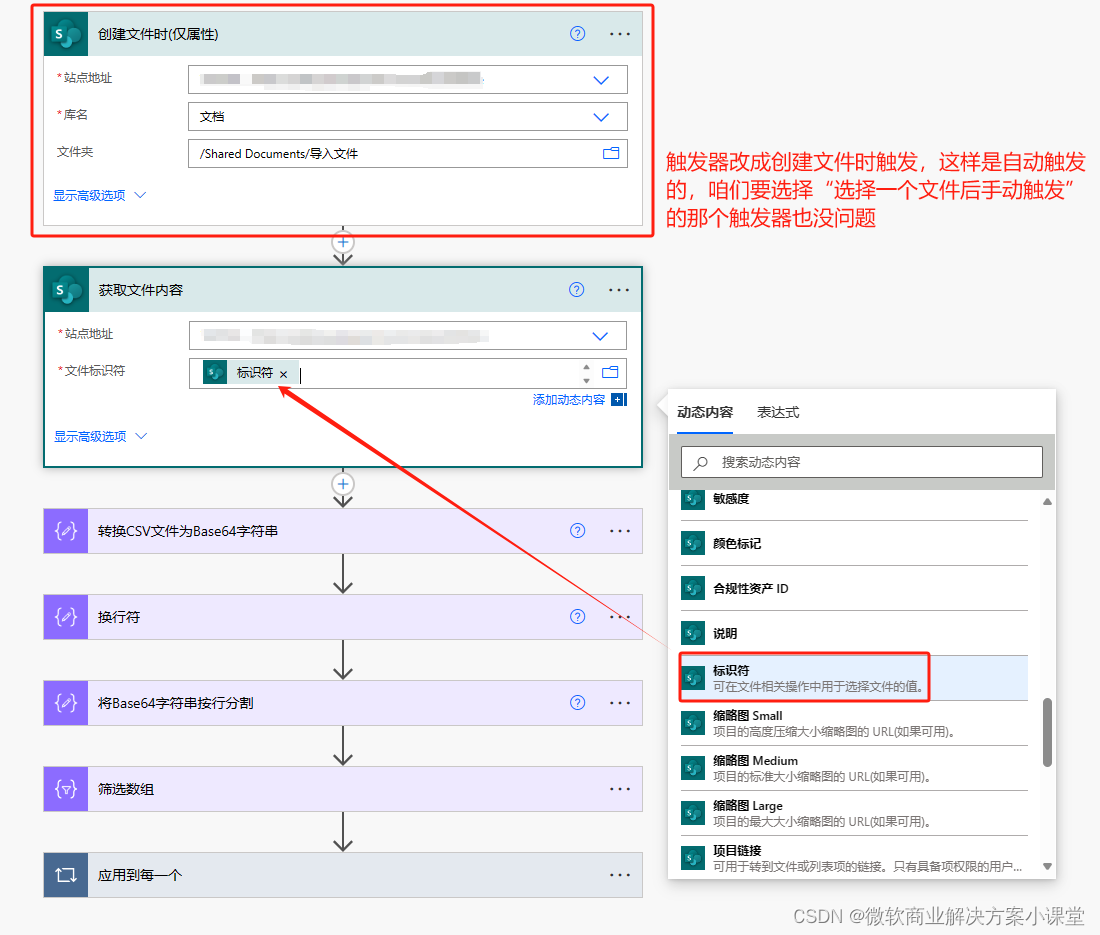
改了触发器后别忘了改这里呦。
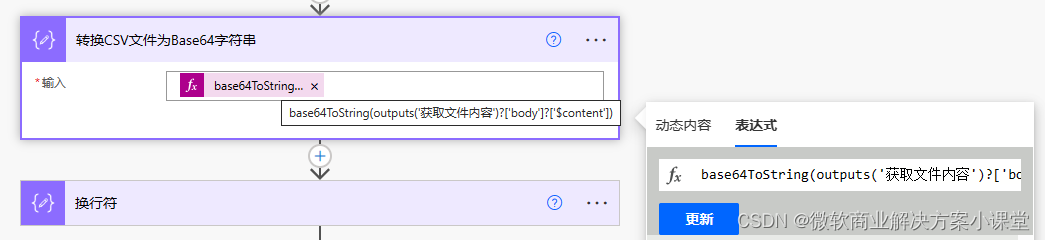
这里 ['body'] 后边要手动加一个 ?['$content'] 需要注意一下。
---
欢迎加vx交流:vAfi_FeiFei
这篇关于【Power Automate】使用CSV文件向SharePoint中批量导入数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






