本文主要是介绍超参寻优使用介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 实现平台:BigQuant—人工智能量化投资平台
- 可在文末前往原文一键克隆 策略进行进一步研究
超参寻优模块简介
最近,我们上线一个新的模块——超参优化模块,它可以帮助大家对我们平台上的机器学习模型进行超参数优化,让你的收益更上一层楼,接下来就让我给大家介绍下。
超参寻优理论简介
在机器学习里,我们本质上是对损失函数进行最优化的过程。过程类似下面的曲面,算法试图去寻找损失曲面的全局最小值,当然损失曲面实际中不一定是凸曲面,
可能会更加凹凸不平,存在多个局部高低点。
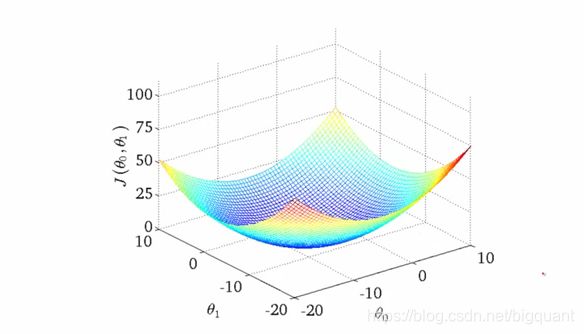
我们还是回到主题,讲述的重点在于超参数寻优的意义。当我们损失曲面给定的时候,我们寻找最优点的路径可能会有一些模型以为的超参数来确定。形象的比喻,
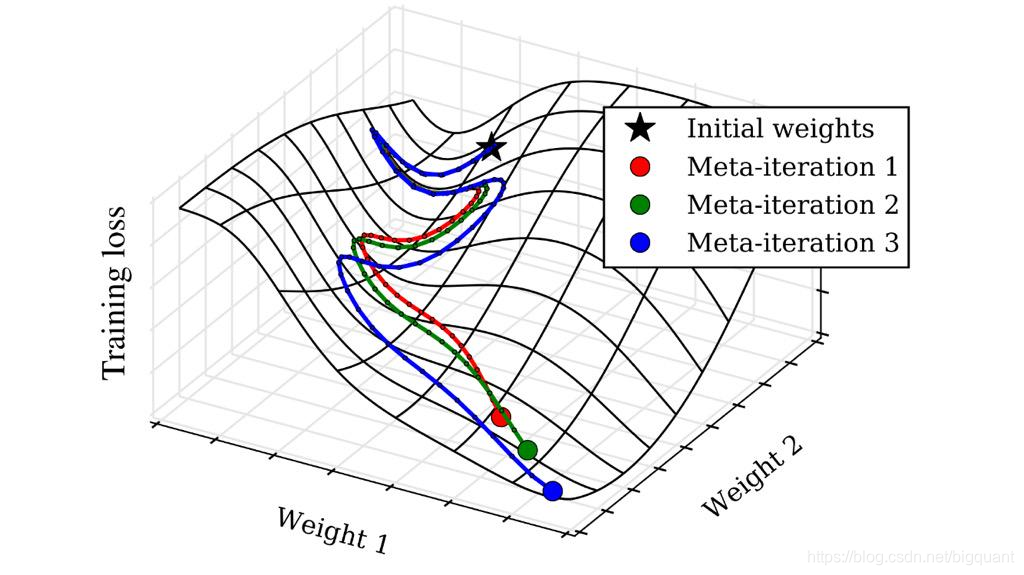
如下图,不同的超参数可能对应这一条不同的寻优路径,比如当我们控制学习率的时候,模型每一步权重更新的部长就会不一样,这样可能导致寻优路径产生根本的差异,
尤其是在高维空间下。
模块使用介绍
在介绍了超参优化的原理后,就来介绍我们提供的超参寻优模块工具。
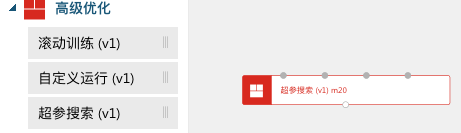
首先打开可视化策略,然后在左边的高级优化下面找到超参搜索,并把它拖进来:
单击模块后,我们能够在右边看到模块的属性,包括:
- 超参数输入
- 评分函数
- 参数搜索方法
- 搜索迭代次数
- 并行运行作业数
超参数输入
在这里构造参数搜索空间。在超参数输入里,我们只需要指定需要调优的参数名,已经参数的搜索空间就ok了,下面给出了示例:
def bigquant_run():param_grid = {}# 在这里设置需要调优的参数备选param_grid['m6.number_of_trees'] = [5, 10, 20]return param_grid
切换到代码模式,可以参考所有可以调优的参数,甚至包括算法和算法的版本都可以修改。

评分函数
评分函数是用来评价一组参数好坏的指标,下面我们给出了一个示例,以回测最终的夏普比作为评分函数:
def bigquant_run(result):score = result.get('m19').read_raw_perf()['sharpe'].tail(1)[0]return score
参数搜索算法
参数搜索算法有两个可选项:
- 网格搜索
- 随机搜索
网格搜索是指给定参数组合后,遍历所有的排列组合。随机搜索指的是每次从所有的排列组合中,随机抽出一组参数,在具有很多参数的情况下,随机搜索会更有效率。
搜索迭代次数
在随机搜索的情况下,最多迭代的次数。
并行运行作业数
指用多少个线程同时搜索所有参数空间
示例策略

源码地址:《超参寻优使用简介》
本文由BigQuant人工智能量化投资平台原创推出,版权归BigQuant所有,转载请注明出处。
这篇关于超参寻优使用介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





