本文主要是介绍小心!Springer旗下34年老刊大量撤稿中国论文,16天见刊,中国人该如何应对?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
毕业推荐
SCIE:
• 计算机类,6.5-7.0,JCR1区,中科院2区
• 2个月19天录用,6天见刊,36天检索
SCI&EI(CCF-C类)
• 算法类,2.0-3.0,JCR3区,中科院4区
• 26天录用
SCI&EI
• 大数据和智能技术类,3.0-4.0,JCR2区,中科院3/2区
• 1个月22天录用,16天见刊
SSCI(ABS一星)
• 社科类,3.0-4.0,JCR2区,中科院3区
• 13天录用,28天见刊,13天检索
避雷投稿
近期自从2024年中科院预警期刊名单发布后,来自中国的论文频繁被期刊撤稿。
2024年2月20日,Bioengineered以数据不真实为由,撤回多篇同时发布在2022年1月13日的论文。质疑内容大致围绕没有基金资助,细胞流式结果图可疑,以及可疑的免疫印记等问题。
从今年1月底至今,Bioengineered总共撤稿 54 篇,全都来自中国的医院,大学或者其他研究机构。这些论文发表于2021年年末到2022年年初的阶段。
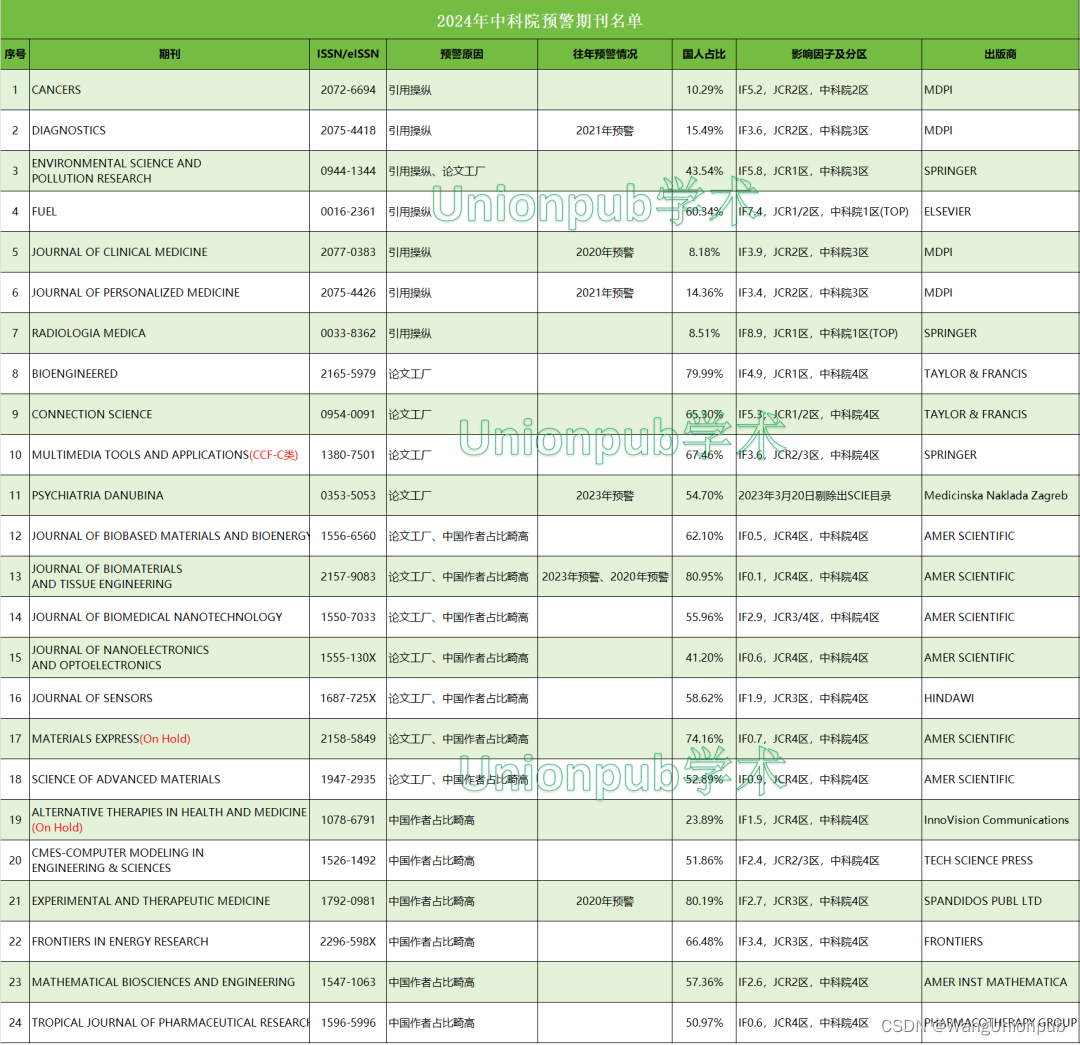
2024年中科院预警期刊名单
近期,又有一本期刊Journal of Cluster Science共撤稿38篇论文,这些被撤的论文全部来自中国的医院、医学院,以及医学、生命科学相关领域的机构。
出版商调查后发现了出版过程中系统性操纵的证据。反复出现的问题包括但不限于:引文不支持文中所述的观点、非标准用语、图表异常、伦理批准声明中的矛盾等。这些问题暴露出这些论文的背后可能存在有“论文工厂”。
期刊简介
Journal of Cluster Science

数据库收录时间:1990年
出版社:Springer
ISSN:1040-7278
eISSN:1572-8862
影响因子:2.8
期刊分区:JCR2区,中科院4区
检索情况:SCIE&Scopus
自引率:0.00%
预警情况:无中科院预警记录
期刊官网:https://www.springer.com/10876
投稿网址:https://mc.manuscriptcentral.com/jocl
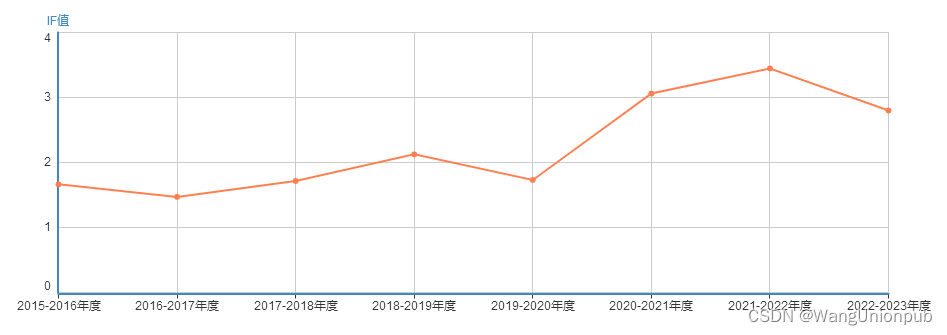
影响因子
近几年稳步上升,质量较稳定
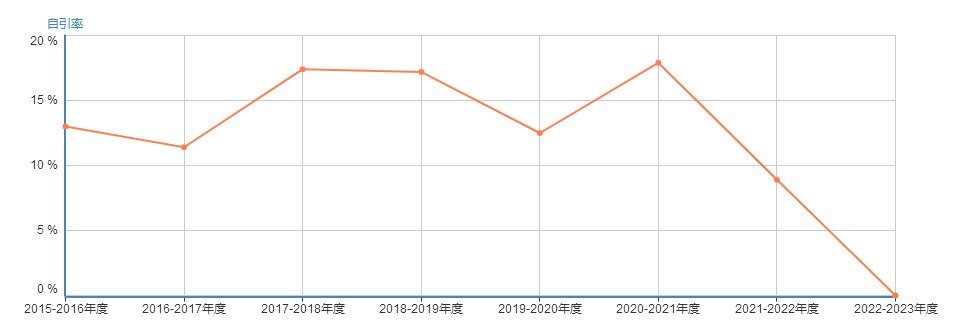
自引率
自引率一直在10%-17%左右,2020-2021年度达到17.9%的历史新,2023年降为0
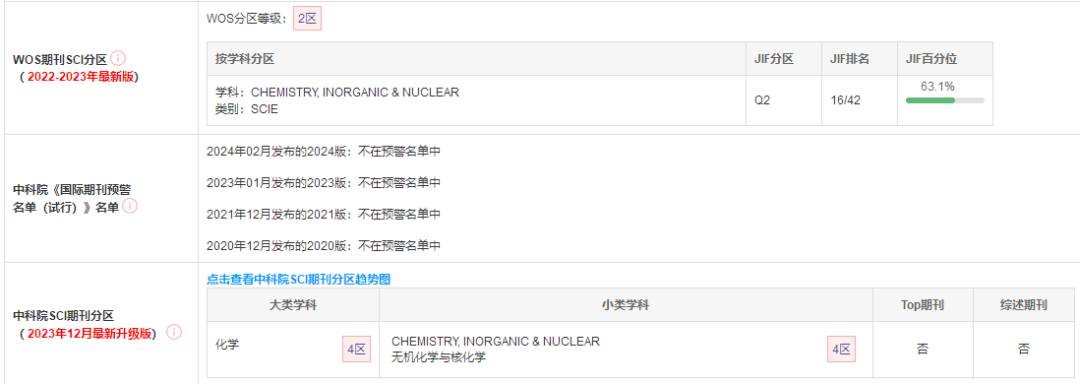
期刊分区
中科院分区:2022年大类为化学4区,小类为无机化学与核化学4区,非Top期刊,非综述期刊。
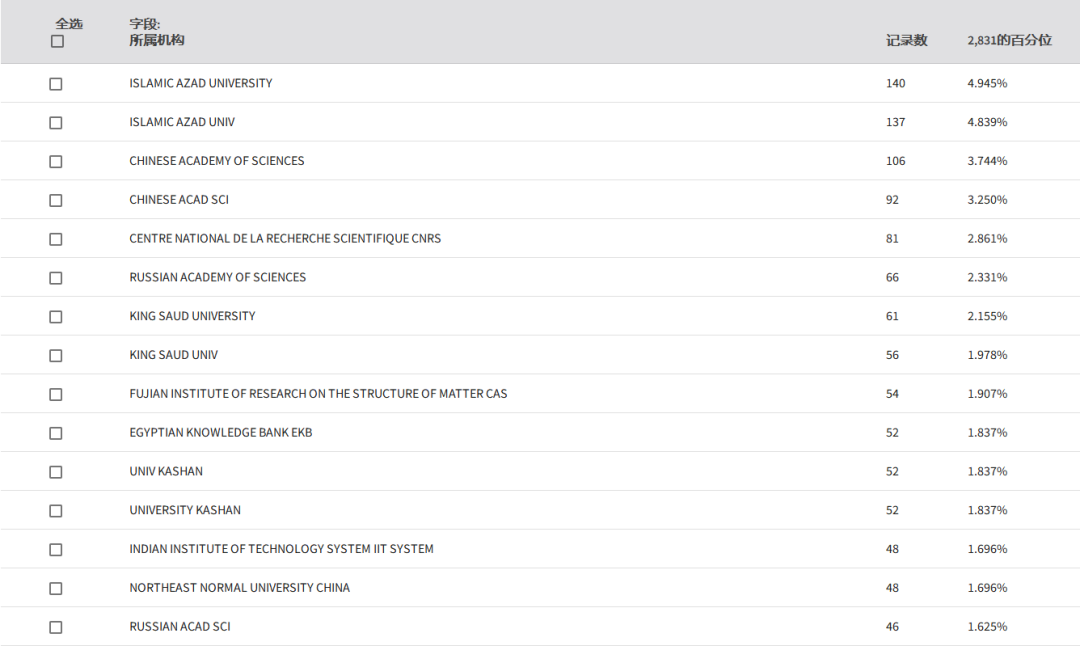
发文机构
发文排名前三的机构为伊斯兰阿扎德大学、中国科学院、国家科学研究中心CNRS
国人占比
国人占比34.264%,排名第一,稍显偏高

发文量
近几年发文量100-200篇左右,发文稳定无激增情况

审稿速度
总体来说审稿速度较快,周期正常
3个月3天录用,16天见刊

3个月3天录用,54天见刊

3个月2天录用,45天见刊

征稿领域
有关化学、材料、生物及其相关技术的研究
总结
综合以上情况来看,期刊目前虽然未被中科院预警名单收录,但存在一定被科睿唯安标记为“On Hold”的风险。各位老师投稿前请谨慎。
小心!Springer旗下34年老刊大量撤稿中国论文,16天见刊,中国人该如何应对?
• 本文素材来源:Pubpeer、科学人Scientist、IAMSET学术服务等
• 文中仅代表作者观点,转载仅出于传播更多资讯之目的。若侵犯了您的合法权益,敬请告知我们更正或删除
• 更多科研干货、期刊最新动态、期刊匹配、避雷选刊,可移步公众号“Unionpub学术”
这篇关于小心!Springer旗下34年老刊大量撤稿中国论文,16天见刊,中国人该如何应对?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








