本文主要是介绍阿里云TSDB时空数据库实战(一):数据入库与导出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阿里云TSDB时空数据库实战(一):数据入库与导出
- 前言
- 一、创建时空数据库实例
- 二、安装桌面交互工具QGIS
- 三、在QGIS添加图层
- 四、数据入库
- 五、数据导出
前言
5月5号,阿里云发布了最新的时空数据库,感兴趣的同学可以之前的文章《重磅!阿里云时空数据库正式免费公测》,
或者点击下面连接登陆阿里云官网进行免费试用:
https://www.aliyun.com/product/hitsdb_spatialpre
阿里云时空数据库能够存储、管理包括时间序列以及空间地理位置相关的数据。传感器网络、移动互联网、射频识别、全球定位系统等设备时刻输出时间和空间数据,数据量增长非常迅速,这对存储和管理时空数据带来了挑战,传统数据库很难应对时空数据。阿里云时空数据库具有时空数据模型、时空索引和时空算子,完全兼容SQL及SQL/MM标准,支持时空数据同业务数据一体化存储、无缝衔接,易于集成使用。
从这篇文章开始,我们会推出一系列文章来指导大家如何用阿里云时空数据库进行实战。
第一篇主要给初次试用时空数据库一些帮助,便于把一些离线的本地文件写入时空数据库,并把时空数据库中的数据导出到本地。
一、创建时空数据库实例
第一步:首先按照页面提示购买测试实例,免费试用2个月,整个创建实例的需要耗时大约10分钟;
第二步:然后在控制台中,选择“时序时空数据库->实例详情”配置网络连接参数
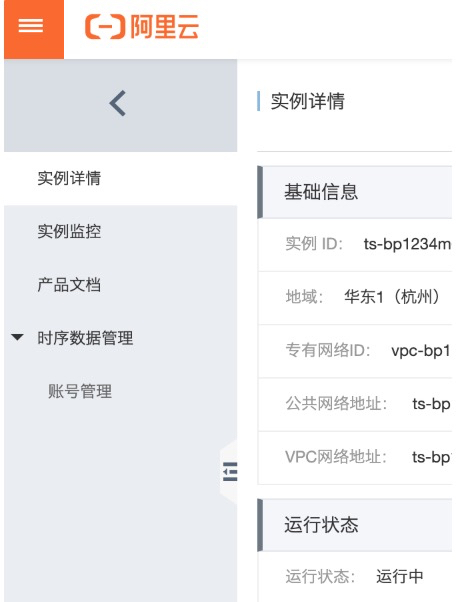
这里为了测试方便,VPN和公共网络的参数都设置成“0.0.0.0/0”
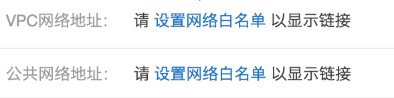
配置完之后显示如下信息

第三步:在控制台中创建账户,选择“账户管理”进入账户创建页面;
经过这三步操作,整个时空数据库的初始化工作已经完成,外部网络就可以同时空数据库交互。
二、安装桌面交互工具QGIS
根据您所用的操作系统选择对应QGIS版本,目前QGIS支持Windows、Mac和Linux,QGIS是免费开源工具,链接地址https://www.qgis.org
三、在QGIS添加图层
第一步:添加TSDB时空数据库连接:右键选择“PostGIS”
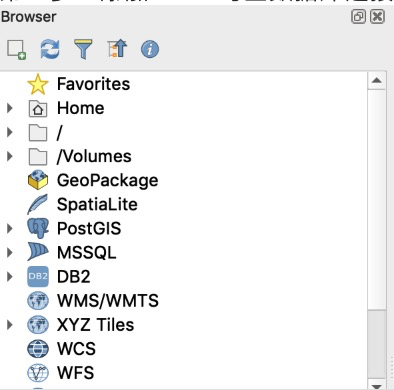
然后选择“新建”连接,在对话框中填入对应信息
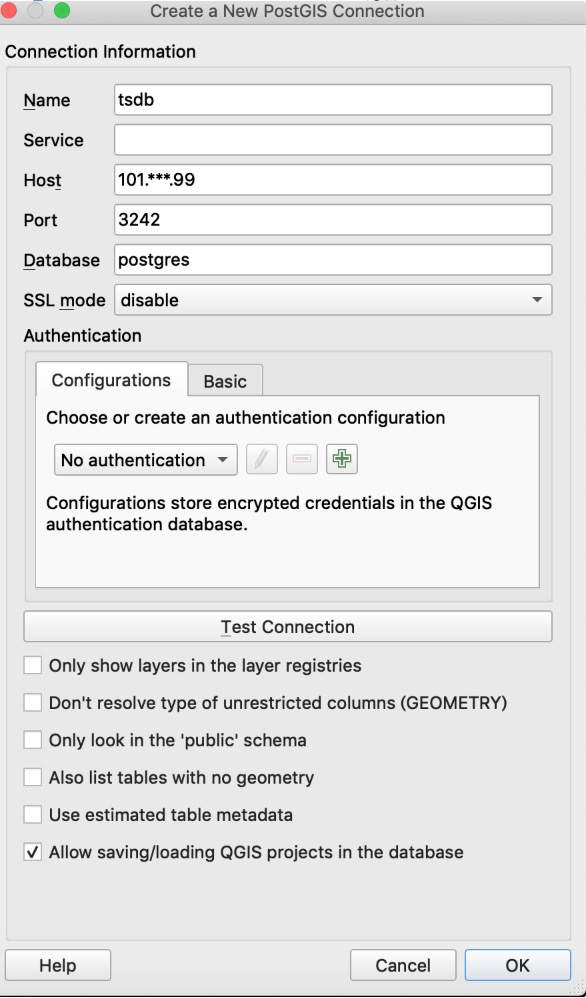
Host即为公网对应的IP,然后点击“Test Connection”,需要填写数据库用户名和密码,测试通过后,点击“OK”保存TSDB时空数据库连接。成功之后在左侧目录会看到
第二步:选择“Layer=>Add Layer=>Add Vector Layer”菜单,然后选择本地矢量文件,后缀名是.shp;这里可以一次添加多个shp文件也可以选择只添加一个。
四、数据入库
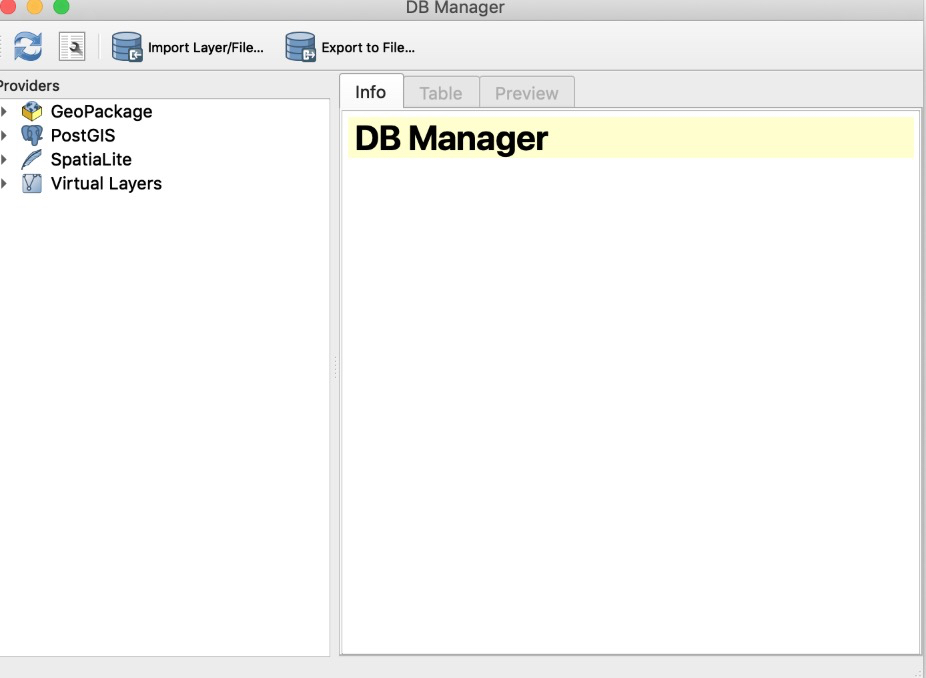
第一步:选择菜单“DataBase => DBManager”,显示如下对话框
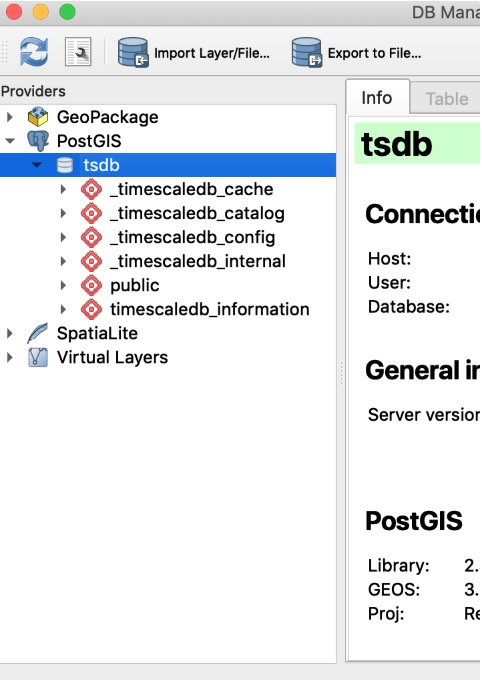
第二步:点击“PostGIS”目录,选择“tsdb”子目录。
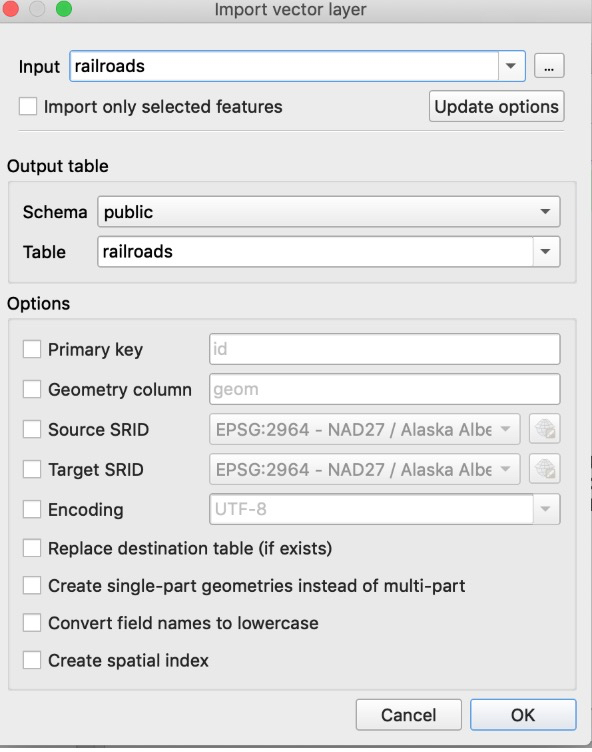
第三步:选择“Import Layer”菜单,在输入列表“Input”选择要入库的图层(上面刚添加的本地文件),然后在选择“Schema”,这里选择是“Public”,并自定义入库后的表名,如果需要创建空间索引需要勾选“Create Spatial Index”,然后点击“OK”按钮实现数据入库
五、数据导出
数据导出同导入步骤类似,不同之处是在打开数据库连接,并选择响应的待导出库如上图“tsdb”
选择“Export to File”菜单,然后选择文件需要输出的位置
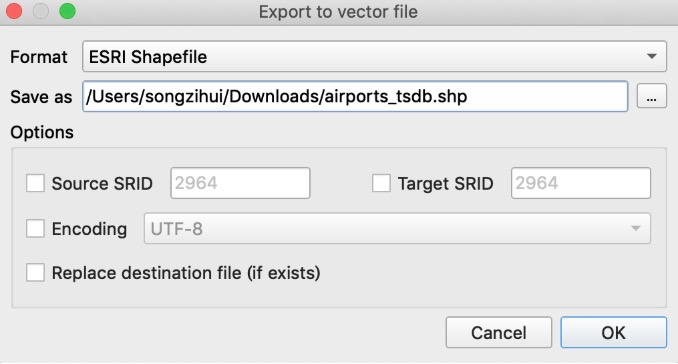
然后再点击“OK”即可。
这篇关于阿里云TSDB时空数据库实战(一):数据入库与导出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








