本文主要是介绍ElasticSearch之排序,fielddata和docvalue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
es搜索返回结果的排序默认是按照得分的高低来排的,本文来看下如何按照字段来排序,实现类似于MySQL的order by xxx的效果。
1:什么是fileddata和doc_value
参考ElasticSearch之零碎知识点 和一文带你彻底弄懂ES中的doc_values和fielddata 。
2:实例
测试数据参考这篇文章 。
- 先来看日期字段排序的查询:
POST kibana_sample_data_ecommerce/_search
{"size": 5,"query": {"match_all": {}},"sort": [{"order_date": {"order": "desc"}}]
}
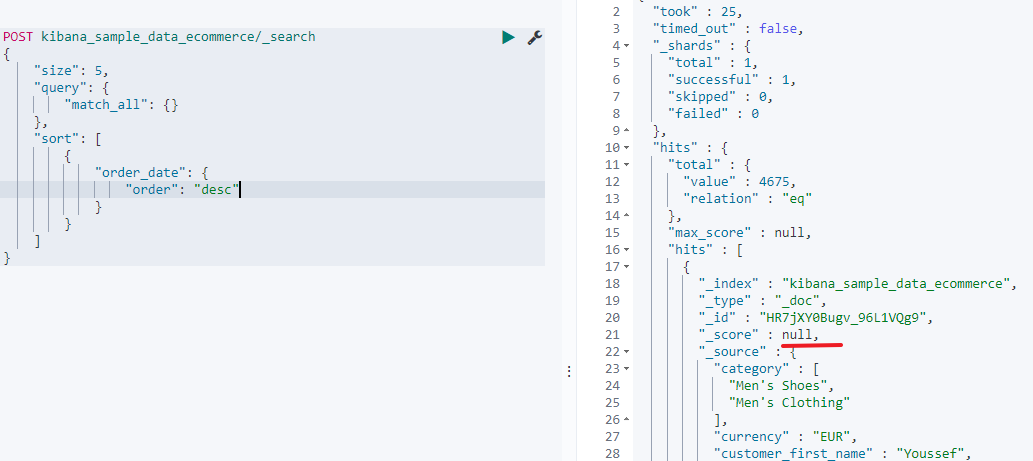
可以正常查询,但是注意此时因为不需要根据算分来排序,所以是就没有计算得分了。
- 看下多字段排序
POST kibana_sample_data_ecommerce/_search
{"size": 5,"query": {"match_all": {}},"sort": [{"order_date": {"order": "desc"},"_doc": {"order": "asc"},"_score": {"order": "desc"}}]
}
_doc 是按照文档的索引顺序排序。
_score是按照得分来排序,因此此时就要计算得分了。
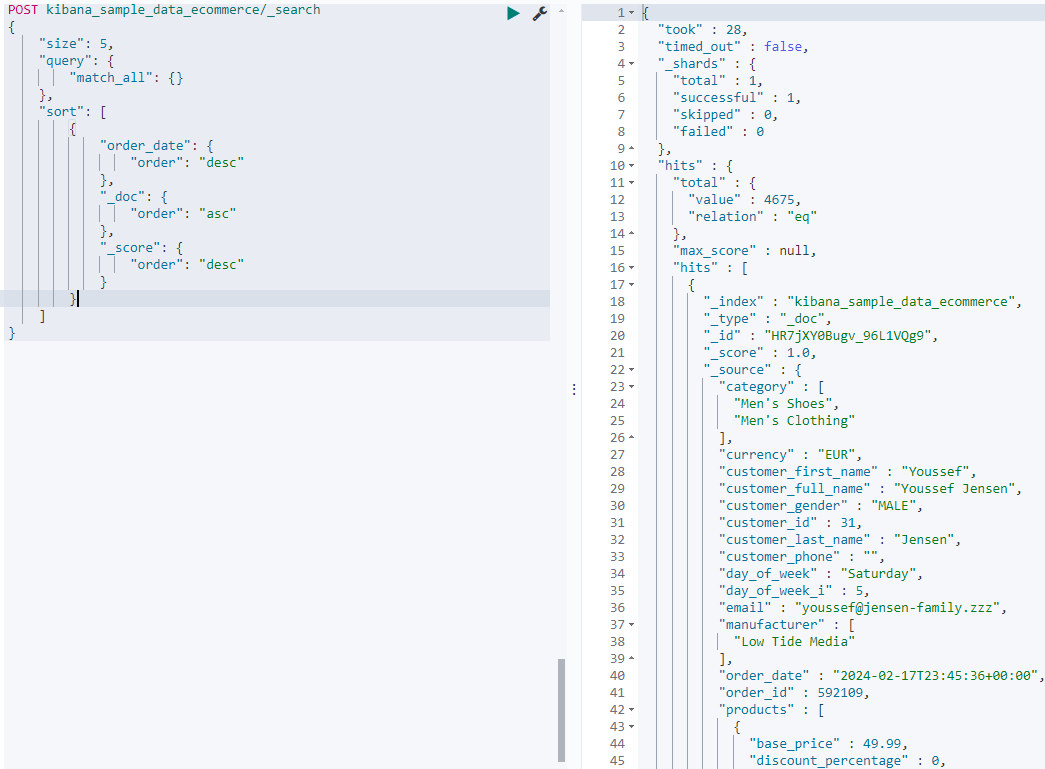
- 基于text字段的排序
POST kibana_sample_data_ecommerce/_search
{"size": 5,"query": {"match_all": {}},"sort": [{"customer_full_name": {"order": "desc"}}]
}
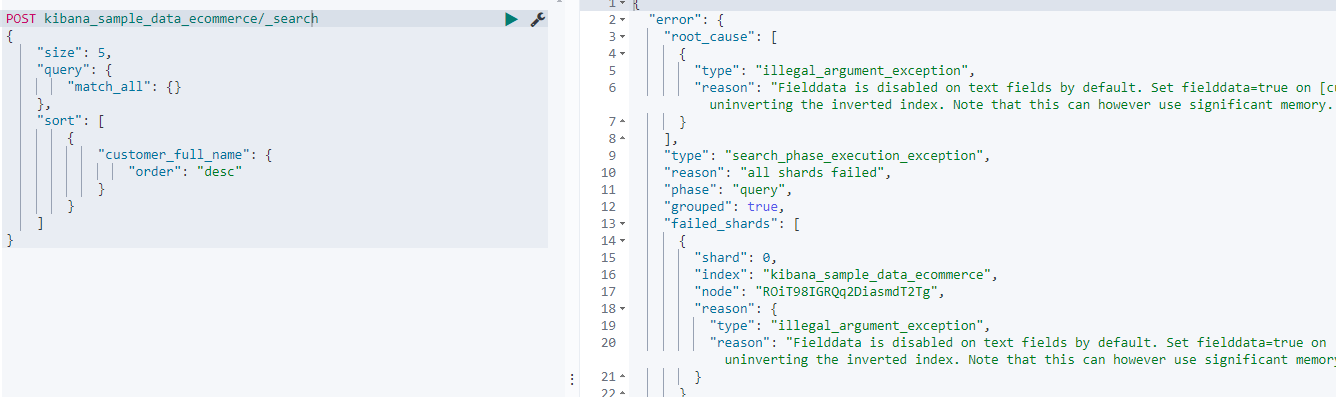
报错了,这是因为text字段类型默认是关闭fielddata的,因此想要对text类型使用排序,需要显式的在mapping中打开。
上述,日期不报错,是因为日期是默认打开doc_values的,因为在实际业务中我们按照日期排序的场景很多,类似的整形也是打开doc_values的。但text类型因为数据结构本身的限制,所以是不支持doc_values的,所以只能通过打开fielddata来完成排序需求。
- 打开text的fielddata
PUT kibana_sample_data_ecommerce/_mapping
{"properties": {"customer_full_name": {"type": "text","fielddata": true,"fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}
}
在执行上述的查询就正常了:
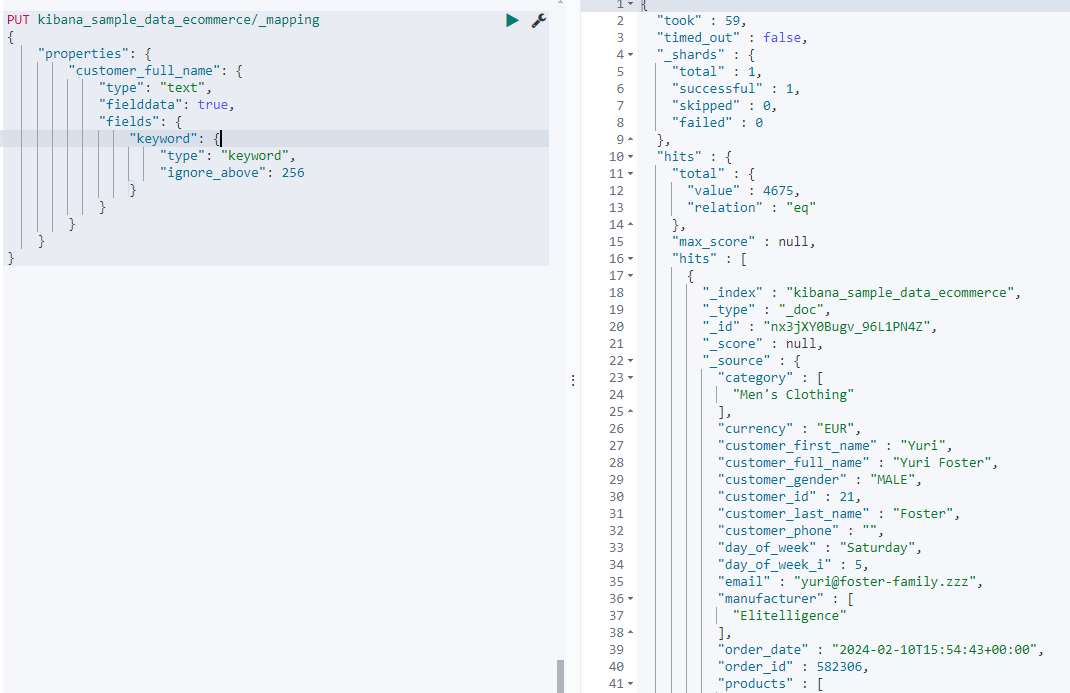
- 最佳实践
在业务中,如果是确定不需要的字段可以显式的关闭doc_values和fielddata。减少索引的速度,以及jvm heap和磁盘空间的占用。
写在后面
参考文章列表
ElasticSearch之零碎知识点 。
这篇关于ElasticSearch之排序,fielddata和docvalue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






