本文主要是介绍论文笔记What does BERT know about books, movies and music Probing BERT for Conversational Recommendation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文出发点:
- 现成的BERT模型在它们的参数中存储了多少关于推荐项目(电影,书籍,音乐)的知识
现象:BERT在NLP领域如此强劲的表现从侧面体现bert的参数里存储了 事实性知识
做了一系列探测实验探查BERT蕴含的两类知识:
- content-based:通过item的文本内容匹配item的标题(类别)
- collaborative-based:通过匹配相似item
通过三项任务:
- MLM掩码语言模型:通过完形填空的形式来做文本内容与文本流派的匹配;
- 通过下一句预测和相似度比较来探寻BERT在不fine-tune的情况下的信息检索和推荐能力。
结论:
- BERT在其参数中存储了关于书籍、电影和音乐内容的知识;
- 基于content的知识多于基于collaborative的知识;
- 在面对有对抗数据的对话数据上表现不理想
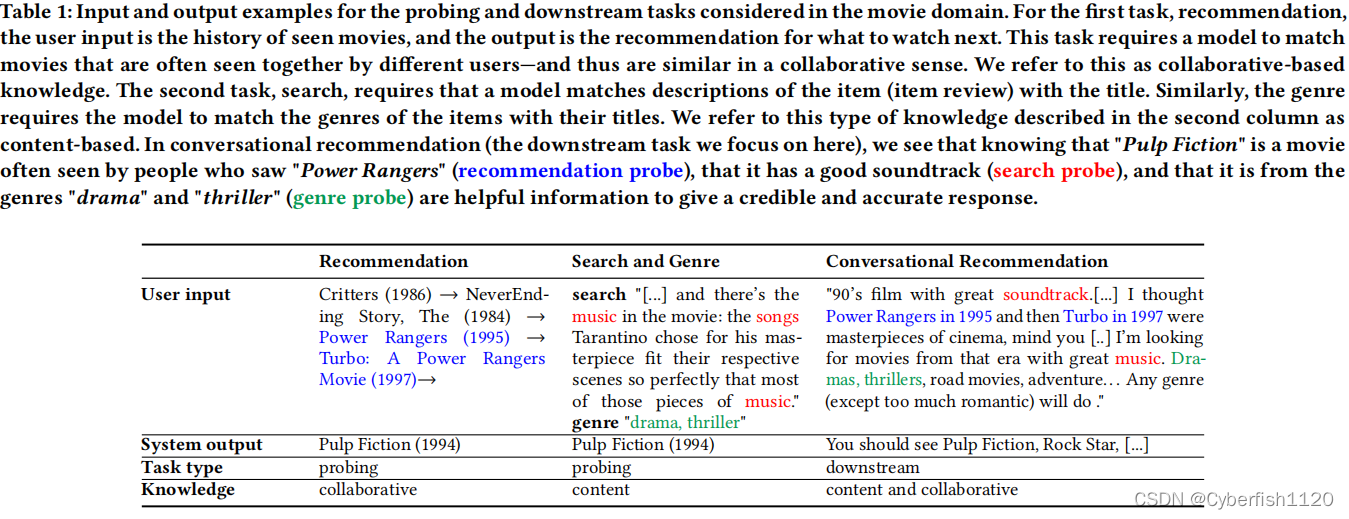
第一个任务:MLM(掩码语言模型)
目标:生成item(电影)的流派
形式:完形填空,prompt,如:Pulp Fiction is a movie of the ___ genre.
第二个任务:推荐
目标:推荐item
形式:SIM,下一句预测,prompt,如:If you liked Pulp Fiction [SEP] you will also like Reservoi Dogs的分数要比If you liked Pulp Fiction [SEP] you will also like To All the Boys I’ve Loved Before高
第三个任务:搜索
目标:搜索target item
形式:SIM和下一句预测
对于问题1:How much knowledg do off-the-shelf BERT models store in their parameters about item to recommend? 的结论:
- BERT既包含content的知识,也包含collaborative的知识。在任务一上top-5 acc为30%~50%(针对不同的domain);任务三在二选一的检索上有80%的准确率;当候选集只有两个的时候,任务二的准确率为60%。
- BERT基于content的知识多于基于collaborative的知识。
- The NSP is an important pre-training objective for the searc and recommendation probing tasks, improving the effectiveness over not using the NSP head by up to 58%(???)
- BERT对于搜索和推荐探针的有效性随着探针中候选对象数量的增加而显著下降,特别是对于基于协作的知识(即在第一个位置的回忆减少了35%)。(???)
对于问题2:*将会话推荐的额外知识注入BERT的有效方式是什么?*的结论
- 微调的BERT在区分相关响应和不相关响应方面非常有效,与下游任务的baseline相比,NDCG@10提升了36%;
- 当面对敌对产生的消极候选人推荐随机项目时,BERT的有效性显著降低(从0.81NDCG@10降至0.06);
- 在微调过程中通过多任务学习注入基于内容和基于协作的知识,可以提高会话推荐。
方法论
三种Probing tasks:genre,search,recommendation
一种fine-tuning task:对话推荐
Genre Probes(MLM)
三种Prompt形式:
- TP-NoTitle:不提供item,只提供item所在的域。如:“It is a movie of the [MASK] genre.”
- TP-Title:既提供item,又提供item所在的域。如:“Pulp Fiction is a [MASK] movie.”
- TP-TitleGenre:提供item标题,领域以及一个额外的短语“of the genre”,表明我们正在寻找项目的类型。如:“Pulp Fiction is a movie of the [MASK] genre .”
Recommendation and Search Probes(SIM和NSP)

Probe Based on Similarity (SIM)
两部分点乘:
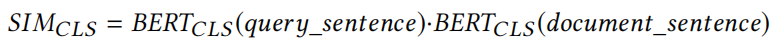
Probe Based on Next Sentence Prediction Head(NSP)
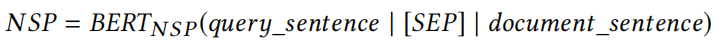
下游任务:对话推荐
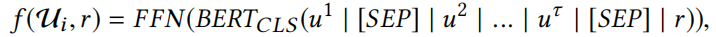
FFN是二分类线性层
实验结果

从TP-NoTitle可以看出BEET对于不同领域有学到相应的知识,比如book领域-》fantasy;movie领域-》action;music领域-》rock
TP-Title也能学到知识,按由于没有“genre”的限制,可能会对应其他相关的word;
TP-TitleGenre能增强TP-NoTitle的结果
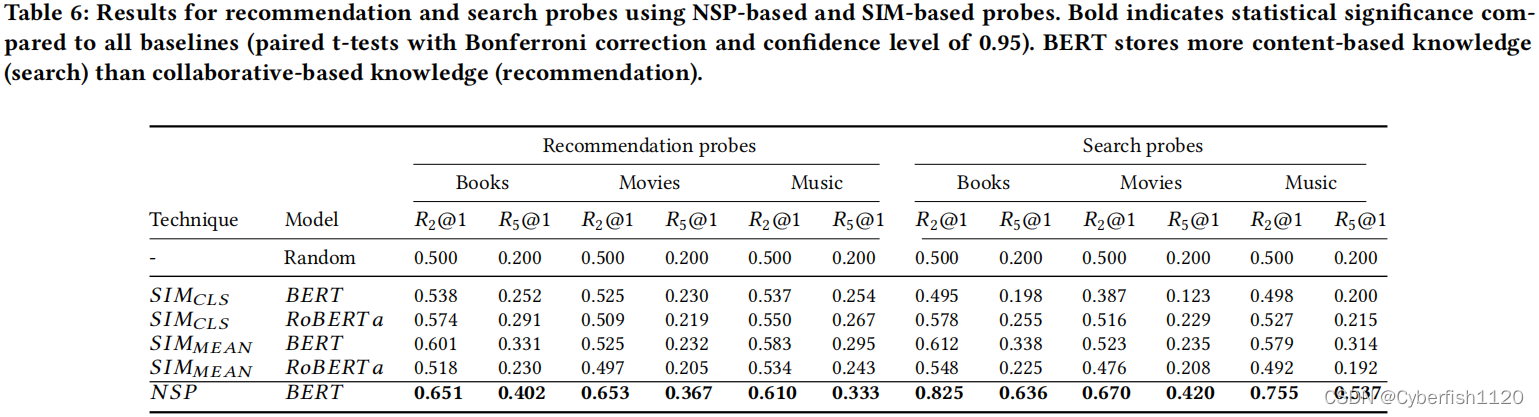
在搜索和推荐方面BERT也是有作用的,NSP的作用会比SIM大-》进而体现了BERT NSP的任务的重要性(这点与Roberta正好相反)
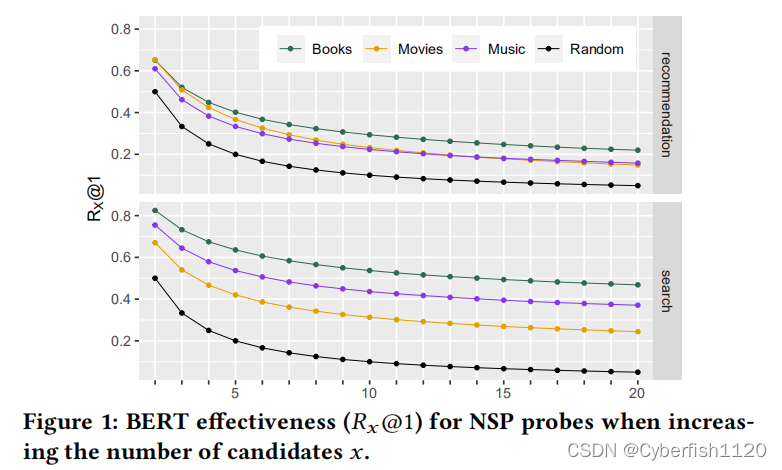
上述结果体现了BERT在候选集过大时表现不会很好
将BERT的参数知识用于对话推荐(fine-tuning、二分类检索式)
样本构造:

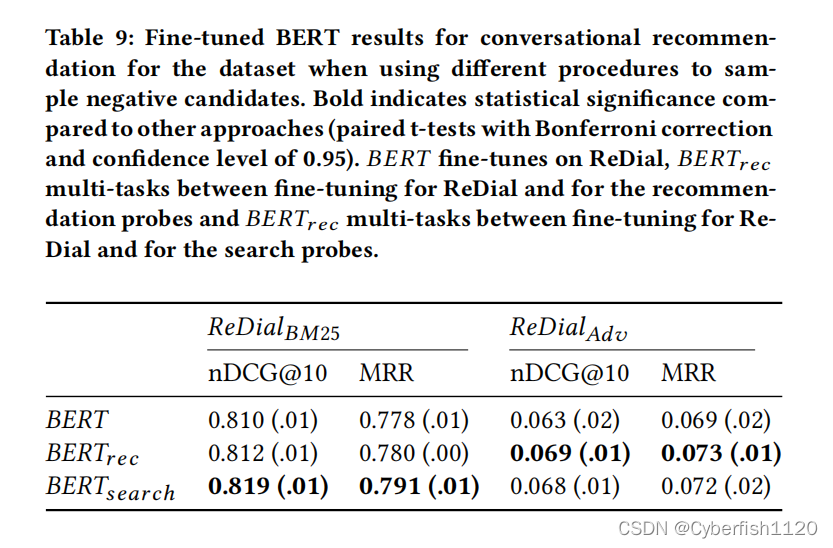
对抗性数据的失败表明,BERT不能成功地区分相关和非相关的项目,只是使用语言线索来寻找相关的答案。
这篇关于论文笔记What does BERT know about books, movies and music Probing BERT for Conversational Recommendation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






