本文主要是介绍SpringBoot基于Spark的共享单车数据管理系统(源码+LW),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💗博主介绍:✌全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例-200套
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言
基于Spark的共享单车数据存储系统拟采用java技术和Springboot 搭建系统框架,后台使用MySQL数据库进行信息管理,设计开发的共享单车数据存储系统。通过调研和分析,系统拥有管理员和用户两个角色,主要具备个人中心、用户管理、共享单车管理、系统管理等功能模块。将纸质管理有效实现为在线管理,极大提高工作效率。
二.技术环境
jdk版本:1.8 及以上
ide工具:Eclipse或者 IDEA
数据库: mysql5.7 (必须5.7)
编程语言: Java
大数据框架:Spark
java框架:SpringBoot
maven: 3.6.1
详细技术:HTML+CSS+JAVA+SpringBoot+MYSQL+VUE+MAVEN+Spark
三.功能设计
共享单车数据存储系统综合网络空间开发设计要求。目的是将传统管理方式转换为在网上管理,完成共享单车数据存储信息管理的方便快捷、安全性高、交易规范做了保障,目标明确。共享单车数据存储系统可以将功能划分为管理员功能和用户功能。
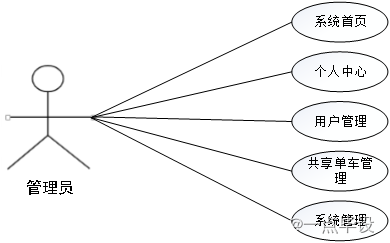
(1)管理员关键功能包含系统首页、个人中心、用户管理、共享单车管理、系统管理等等进行管理。管理员用例如下:
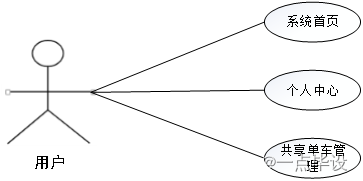
(2)用户关键功能包括系统首页、个人中心、共享单车管理等进行操作。用户用例如下:
系统总体功能结构图如下所示:

四.数据设计
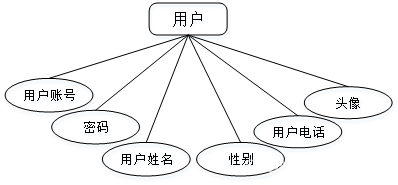
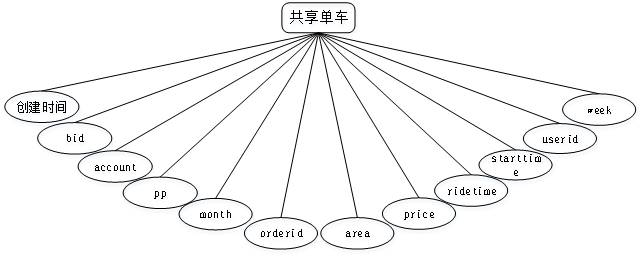
开发一个系统也需要提前设计数据库。这里的数据库是相关数据的集合,存储在一起的这些数据也是按照一定的组织方式进行的。目前,数据库能够服务于多种应用程序,则是源于它存储方式最佳,具备数据冗余率低的优势。虽然数据库为程序提供信息存储服务,但它与程序之间也可以保持较高的独立性。总而言之,数据库经历了很长一段时间的发展,从最初的不为人知,到现在的人尽皆知,其相关技术也越发成熟,同时也拥有着坚实的理论基础。本系统主要实体属性图如下所示:
五.部分效果展示
5.1系统前台实现效果
用户进入主页面,主要功能包括对系统首页、个人中心、共享单车管理等进行操作。用户主界面如图所示:

5.2系统后台管理实现效果
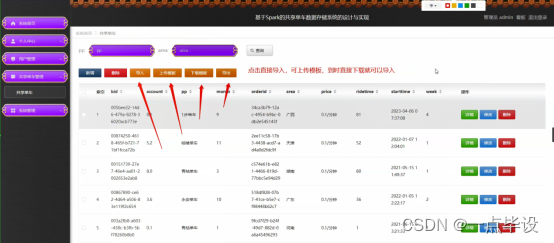
管理员点击共享单车管理。进入共享单车页面输入PP和area进行查询、导入、上传模板、下载模板、导出、新增或删除共享单车列表,并根据需要对共享单车详细信息进行详情、修改或删除操作。如图所示:
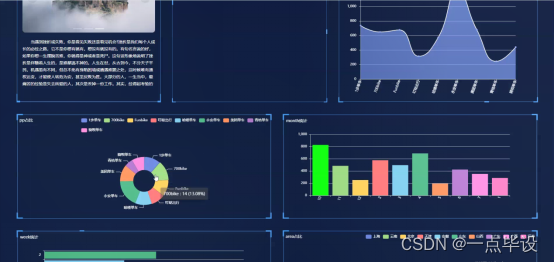
管理员点击右上角色的看板,可以查看到系统简介、共享单车总数、PP统计、PP占比、month统计、week统计、arra占比、共享单车等等实时的分析图进行可视化管理;如图所示:
六.部分功能代码
//导出Excel@RequestMapping("/importExcel")public R importExcel(@RequestParam("file") MultipartFile file){try {//获取输入流InputStream inputStream = file.getInputStream();//创建读取工作簿Workbook workbook = WorkbookFactory.create(inputStream);//获取工作表Sheet sheet = workbook.getSheetAt(0);//获取总行int rows=sheet.getPhysicalNumberOfRows();if(rows>1){//获取单元格for (int i = 1; i < rows; i++) {Row row = sheet.getRow(i);GongxiangdancheEntity gongxiangdancheEntity =new GongxiangdancheEntity();gongxiangdancheEntity.setId(new Date().getTime()+new Double(Math.floor(Math.random()*1000)).longValue());String bid = CommonUtil.getCellValue(row.getCell(0));gongxiangdancheEntity.setBid(bid);String account = CommonUtil.getCellValue(row.getCell(1));gongxiangdancheEntity.setAccount(account);String pp = CommonUtil.getCellValue(row.getCell(2));gongxiangdancheEntity.setPp(pp);String month = CommonUtil.getCellValue(row.getCell(3));gongxiangdancheEntity.setMonth(month);String orderid = CommonUtil.getCellValue(row.getCell(4));gongxiangdancheEntity.setOrderid(orderid);String area = CommonUtil.getCellValue(row.getCell(5));gongxiangdancheEntity.setArea(area);String price = CommonUtil.getCellValue(row.getCell(6));gongxiangdancheEntity.setPrice(price);String ridetime = CommonUtil.getCellValue(row.getCell(7));gongxiangdancheEntity.setRidetime(Integer.parseInt(ridetime));String starttime = CommonUtil.getCellValue(row.getCell(8));gongxiangdancheEntity.setStarttime(starttime);String userid = CommonUtil.getCellValue(row.getCell(9));gongxiangdancheEntity.setUserid(userid);String week = CommonUtil.getCellValue(row.getCell(10));gongxiangdancheEntity.setWeek(week);//想数据库中添加新对象gongxiangdancheService.insert(gongxiangdancheEntity);//方法}}inputStream.close();} catch (InvalidFormatException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return R.ok("导入成功");}/*** (按值统计)*/@RequestMapping("/value/{xColumnName}/{yColumnName}")public R value(@PathVariable("yColumnName") String yColumnName, @PathVariable("xColumnName") String xColumnName,HttpServletRequest request) {Map<String, Object> params = new HashMap<String, Object>();params.put("xColumn", xColumnName);params.put("yColumn", yColumnName);EntityWrapper<GongxiangdancheEntity> ew = new EntityWrapper<GongxiangdancheEntity>();List<Map<String, Object>> result = gongxiangdancheService.selectValue(params, ew);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");for(Map<String, Object> m : result) {for(String k : m.keySet()) {if(m.get(k) instanceof Date) {m.put(k, sdf.format((Date)m.get(k)));}}}List<Map<String, Object>> result2 = new ArrayList<Map<String,Object>>();for(Map<String, Object> m : result) {List<Tuple2<String, Object>> data = new ArrayList<>();for(String s : m.keySet()) {data.add(new Tuple2<>(s, m.get(s)));}JavaPairRDD<String, Object> originRDD = javaSparkContext.parallelizePairs(data);result2.add(originRDD.collectAsMap());}return R.ok().put("data", result2);}最后
最新计算机毕业设计选题篇-选题推荐(值得收藏)
计算机毕业设计精品项目案例-200套(值得订阅)
这篇关于SpringBoot基于Spark的共享单车数据管理系统(源码+LW)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








