本文主要是介绍stable diffusion的额外信息融入方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
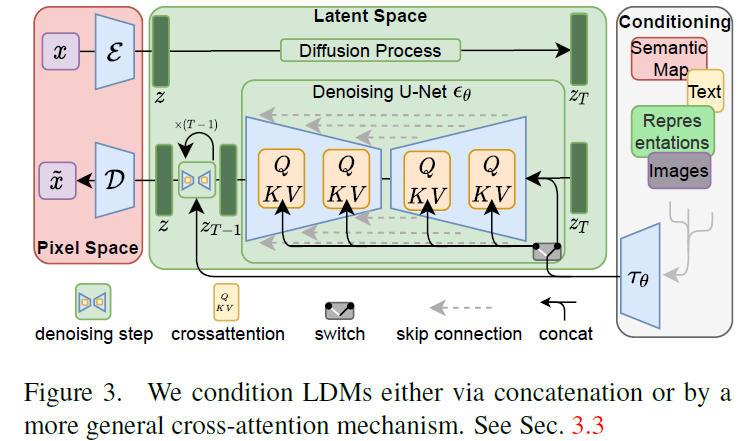
conditioning怎么往sd中添加,一般有三种,一种是直接和latent拼一下,另外很多是在unet结构Spatialtransformers上加,和文本特征一样,通过cross-attention往unet上加,这里还需要注意一点,在文本嵌入时,q是可学习的,k和v都是文本embedding。第三种就是类似controlnet这种,adapter设计。
1.sd img2img
sd的img2img的图像输入是通过VAE将图像转成image latent和latent一起拼的,将512x512的图转成64x64.
init_latent = sd_model.get_first_stage_encoding(sd_model.encode_first_stage(image))
image_conditioning = img2img_image_conditioning(image, init_latent, image_mask)1.ip-adapter

通过解耦cross-attention的方式,clip提取图像特征,文本输入一个crossattention,图像输入一个cross-attention。
3.controlnet
stable diffusion使用和vq-gan相似的预处理方法,将512x512图像转成64x64的潜在图像,controlnet将image-based condition(就是从图像中获取线框图)转成64x64,我们使用4个4x4核和2x2strides的卷积层(后接relu,通常数分别是16,32,64,128,Guassian weights)将image-space condition转成特征图。

4.powerpaint
输入由latent+masked_image+mask concat组合,text侧还是clip编码之后送入unet进行cross-attention。

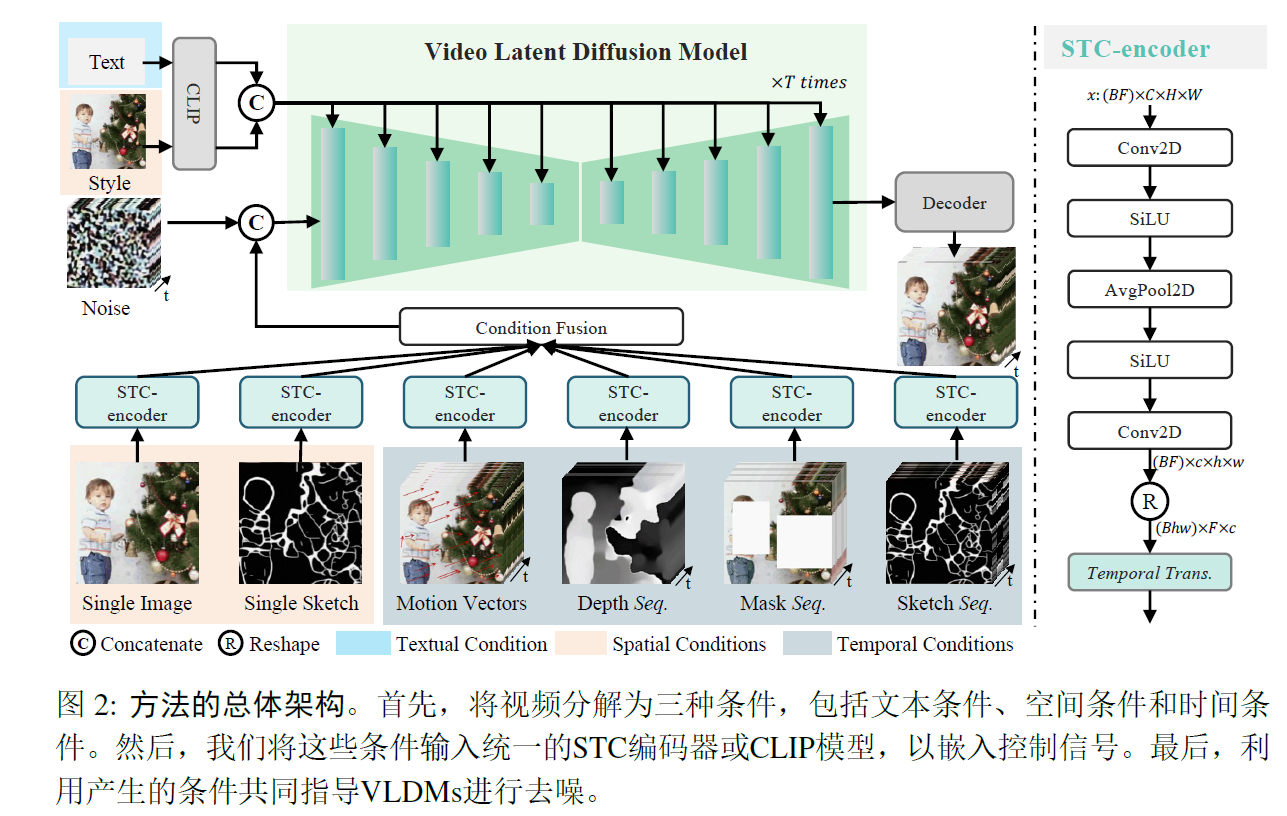
5.VideoComposer
这篇关于stable diffusion的额外信息融入方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




