本文主要是介绍山海鲸可视化软件实战:如何制作一个高效的商品销售数据看板,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为一名数据分析师,我经常需要通过各种工具将数据转化为有价值的信息,为公司的决策提供支持。最近,我使用山海鲸可视化软件制作了一个商品销售数据看板,山海鲸可视化是一款可以免费可视化编辑、免费私有化部署的产品。下面,我将分享整个制作过程。
一、数据准备
首先,我需要从公司的数据仓库中提取出商品销售的相关数据。这些数据包括每个商品的销售额、销售量、退货率等关键指标。在提取数据后,我进行了必要的清洗和预处理,确保数据的准确性和一致性。
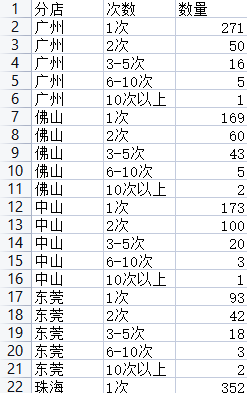
二、选择合适的组件
在山海鲸可视化软件中,有多种组件可供选择。我根据销售数据的特点和展示需求,选择了条形图、折线图、饼图和地图等组件。这些组件能够直观地展示销售数据的各个方面,如销售额的分布、销售量的变化趋势、退货率的比例以及销售数据的地理分布。

三、设计看板布局
接下来,我开始设计看板的布局。我首先确定了看板的主题和风格,然后根据数据的展示需求,合理安排了各个组件的位置和大小。通过不断的调整和优化,我最终确定了一个清晰、美观且易于理解的看板布局。

四、配置组件属性
在确定了看板布局后,我开始配置各个组件的属性。我根据数据的具体情况,调整了组件的颜色、字体、大小等属性,使得数据展示更加直观和易于理解。同时,我还利用了山海鲸可视化软件提供的交互功能,如筛选、排序等,使得用户可以根据自己的需求灵活地查看和分析数据。
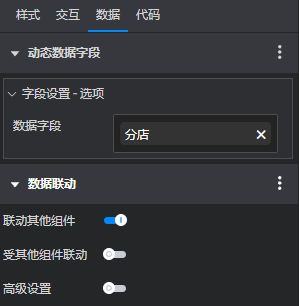
五、发布与分享
当看板制作完成后,我将其发布到了公司的内部平台上。这样,其他部门的同事就可以随时查看和分析销售数据了。同时,我还将看板的链接分享给了相关部门的主管和决策者,以便他们能够快速了解销售情况并作出相应的决策。
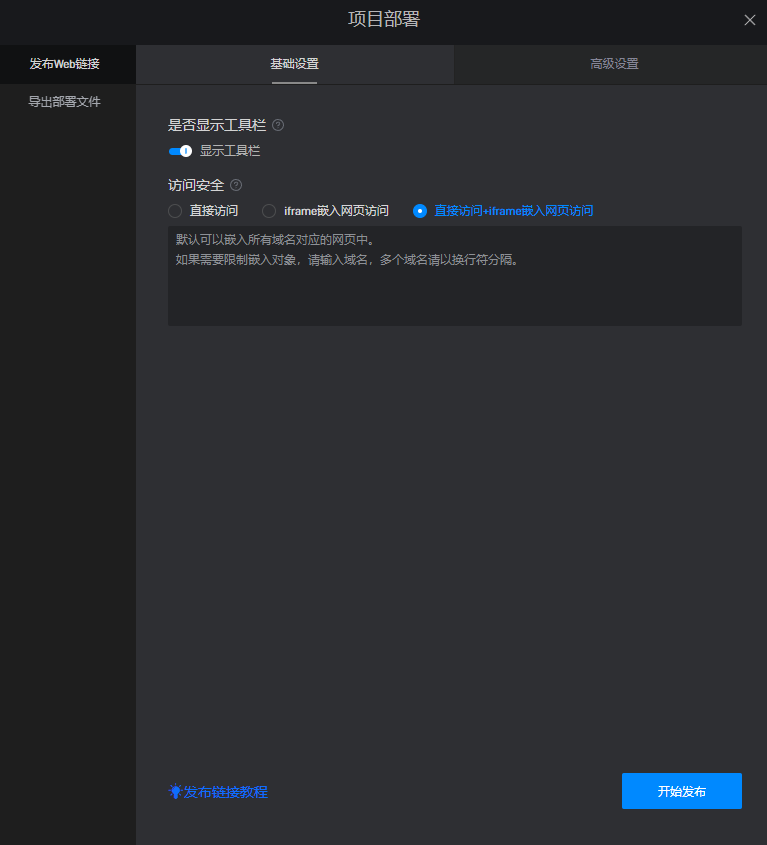
整个制作过程虽然花费了一定的时间和精力,但当看到最终呈现出的看板时,我感到非常满足。通过山海鲸可视化软件,我不仅将杂乱无章的数据转化为了有价值的信息,还为公司的决策提供了有力的支持。我相信,在未来的工作中,山海鲸可视化软件将继续成为我的得力助手。
这篇关于山海鲸可视化软件实战:如何制作一个高效的商品销售数据看板的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









