本文主要是介绍『python爬虫』ip代理池使用 协采云 账密模式(保姆级图文),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 实现效果
- 实现思路
- 代码示例
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
实现效果
在官网原版demo基础上小改了一下,修正了接口错误(把2023改成2024就可以了),原版demo只能测试单个ip,我这里批量测试所有(大家也别测试太狠,浪费人家服务资源)
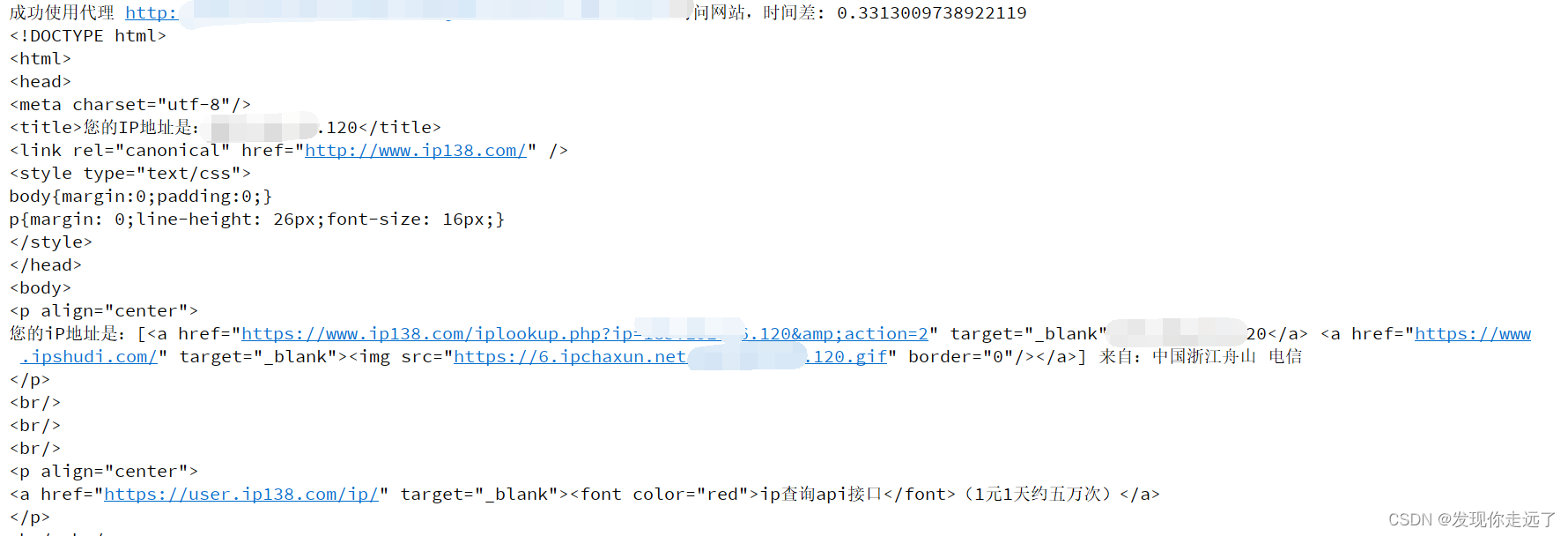
实现思路
跟客服沟通后得到测试账号.
- 拿到proxyAPI 链接
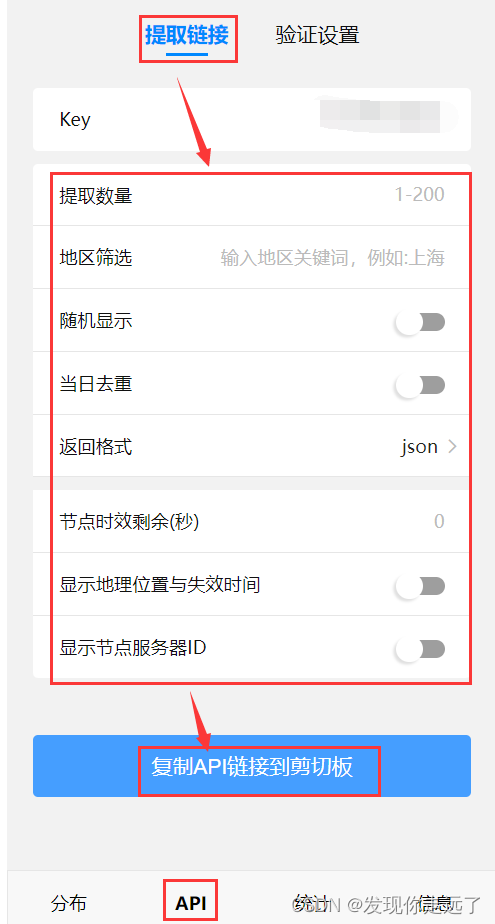
#API链接 后台获取链接地址
proxyAPI = "http://beichencsdn.user.xiecaiyun.com/api/proxies?action=getJSON&key=NP2FE94B34&count=4&word=浙江&rand=true&norepeat=false&detail=true<ime=&idshow=true"
proxyusernm = "xxxxx" #代理帐号
proxypasswd = "xxxxx" #代理密码
url='https://2024.ip138.com/'
#测试ip 接口(注意2024.2.27 官网下载的demo中 这里的接口错误的,我已经把他原本的2023改成2024了,当时测试的时候卡了我半天还以为是接口的问题测了半天```)- 根据客服说明,账密模式可以比白名单模式快30%,大部分的ip代理池都是支持api这种的,所以这里也不研究白名单了.我们拿到的r里面就是一个json数组,包含了ip信息.
r = requests.get(proxyAPI)
- ip信息组装后得到ip代理url
# 组装得到单个ip url# 单个ip的格式 http://用户名:密码@ip地址:端口proxy_url = "http://" + proxyusernm + ":" + proxypasswd + "@" + p["ip"] + ":" + "%d" % p["port"]- 测试响应时间
try:t1 = time.time()#计时开始# 使用ip代理 访问目标的ip检测网站接口response = requests.get(url, proxies={'http': proxy_url, 'https': proxy_url}, headers={"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "max-age=0","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"})t2 = time.time()#计时结束print(f"成功使用代理 {proxy_url} 访问网站,时间差: {t2 - t1}")print(response.text)#访问网页返回的源码except Exception as e:print(f"使用代理 {proxy_url} 访问网站出错:{e}")
代码示例
批量获取ip并测试可用性
import requests
import json
import time#API链接 后台获取链接地址
proxyAPI = "http://beichencsdn.user.xiecaiyun.com/api/proxies?action=getJSON&key=NP2FE94B34&count=4&word=浙江&rand=true&norepeat=false&detail=true<ime=&idshow=true"
proxyusernm = "XXXXXXXX" #代理帐号
proxypasswd = "XXXXXXXX" #代理密码
url='https://2024.ip138.com/' #测试ip 接口(注意2024.2.27 官网下载的demo中 这里的接口错误的,我已经把他原本的2023改成2024了,当时测试的时候卡了我半天还以为是接口的问题测了半天```)#获取代理 IP 地址列表
r = requests.get(proxyAPI)
if r.status_code == 200:proxy_list = json.loads(r.text).get("result", [])if proxy_list:for p in proxy_list:# 组装得到单个ip url# 单个ip的格式 http://用户名:密码@ip地址:端口proxy_url = "http://" + proxyusernm + ":" + proxypasswd + "@" + p["ip"] + ":" + "%d" % p["port"]try:t1 = time.time()#计时开始# 使用ip代理 访问目标的ip检测网站接口response = requests.get(url, proxies={'http': proxy_url, 'https': proxy_url}, headers={"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "max-age=0","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"})t2 = time.time()#计时结束print(f"成功使用代理 {proxy_url} 访问网站,时间差: {t2 - t1}")print(response.text)#访问网页返回的源码except Exception as e:print(f"使用代理 {proxy_url} 访问网站出错:{e}")else:print('获取0个代理IP')
else:print('获取代理失败')
测试单个ip(你已经知道ip和端口)同时注意ip时效性,过一会会失效.
import requests
import timeurl='https://2024.ip138.com/'
proxyaddr = "xxxxxxxxxx" #代理IP地址
proxyport = xxxxxx #代理IP端口
proxyusernm = "xxxxxxxxx" #代理帐号
proxypasswd = "xxxxxxxxxx" #代理密码
#name = input();
proxyurl="http://"+proxyusernm+":"+proxypasswd+"@"+proxyaddr+":"+"%d"%proxyportt1 = time.time()
r = requests.get(url,proxies={'http':proxyurl,'https':proxyurl},headers={"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8","Accept-Encoding":"gzip, deflate","Accept-Language":"zh-CN,zh;q=0.9","Cache-Control":"max-age=0","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"})
r.encoding='gb2312't2 = time.time()print(r.text)
print("时间差:" , (t2 - t1));下面是网上的信息,大家随便找类似的都可以,大部分的代理池调用都一样.(只实测保证本示例代码可用性,其他不保证)

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』
这篇关于『python爬虫』ip代理池使用 协采云 账密模式(保姆级图文)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


