本文主要是介绍top N彻底解秘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本博文内容:
1、基础Top N算法实战
2、分组Top N算法实战
3、排序算法RangePartitioner内幕解密
1、基础Top N算法实战
Top N是排序,Take是直接拿出几个元素,没排序。


新建
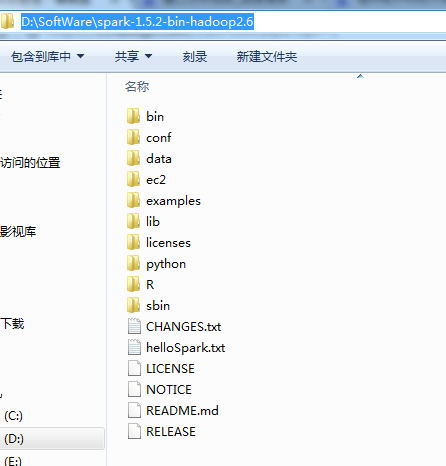


1 4 2 5 7 3 2 7 9 1 4 5

从源码,来说话,take返回的是数组,不是RDD。而colletc需要的是RDD。
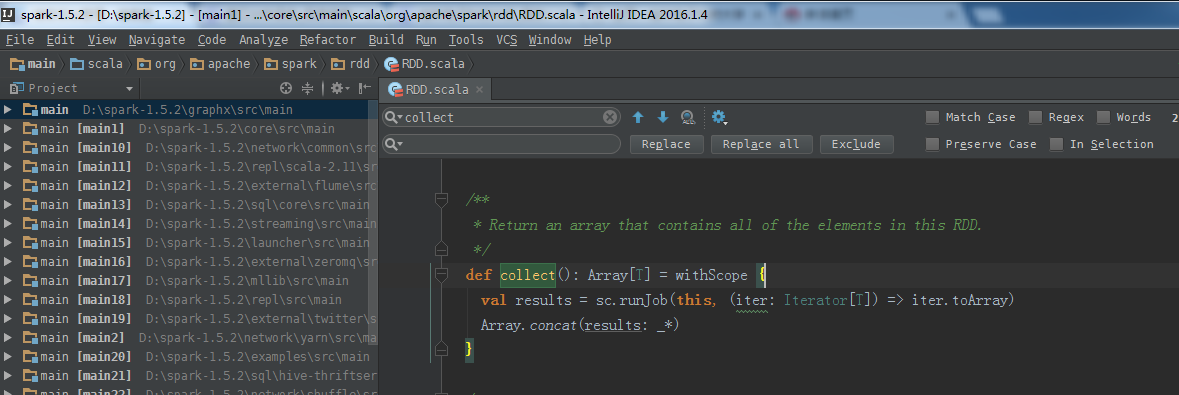
/*** Return an array that contains all of the elements in this RDD.*/ def collect(): Array[T] = withScope {val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)Array.concat(results: _*) }
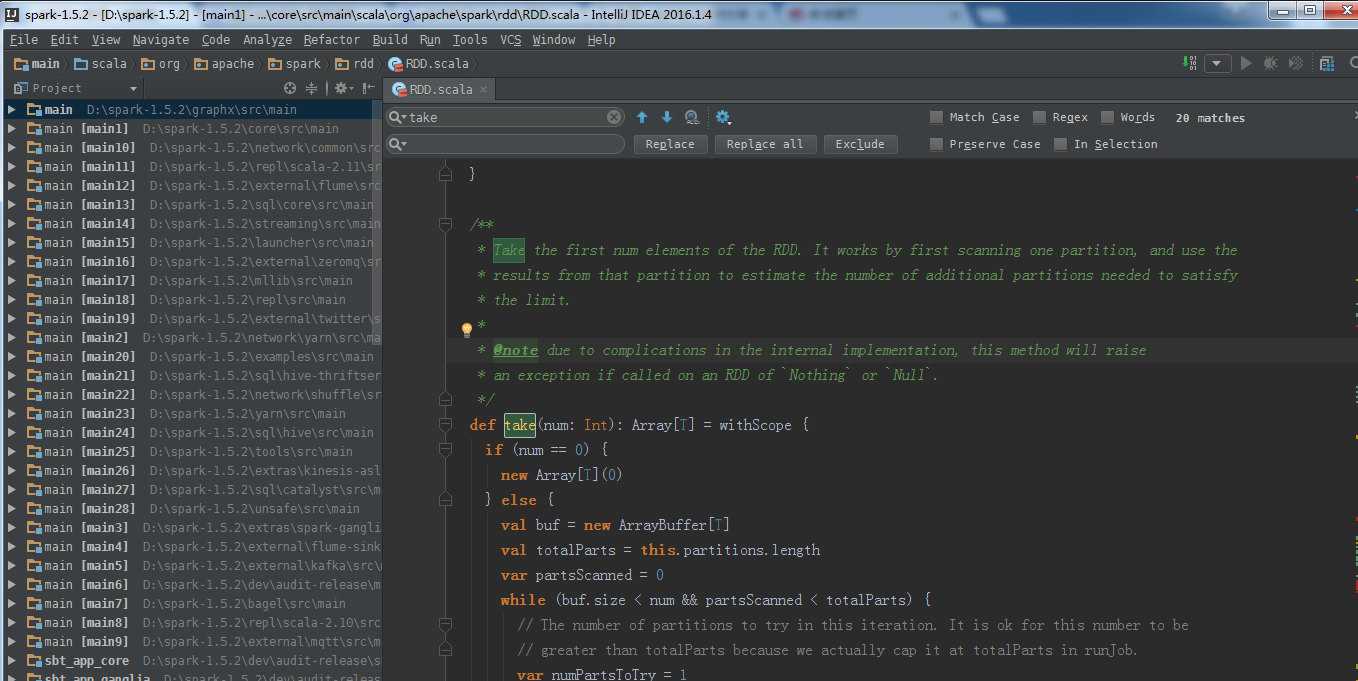
/*** Take the first num elements of the RDD. It works by first scanning one partition, and use the* results from that partition to estimate the number of additional partitions needed to satisfy* the limit.** @note due to complications in the internal implementation, this method will raise* an exception if called on an RDD of `Nothing` or `Null`.*/ def take(num: Int): Array[T] = withScope {if (num == 0) {new Array[T](0)} else {val buf = new ArrayBuffer[T]val totalParts = this.partitions.lengthvar partsScanned = 0while (buf.size < num && partsScanned < totalParts) {// The number of partitions to try in this iteration. It is ok for this number to be// greater than totalParts because we actually cap it at totalParts in runJob.var numPartsToTry = 1if (partsScanned > 0) {// If we didn't find any rows after the previous iteration, quadruple and retry.// Otherwise, interpolate the number of partitions we need to try, but overestimate// it by 50%. We also cap the estimation in the end.if (buf.size == 0) {numPartsToTry = partsScanned * 4} else {// the left side of max is >=1 whenever partsScanned >= 2numPartsToTry = Math.max((1.5 * num * partsScanned / buf.size).toInt - partsScanned, 1)numPartsToTry = Math.min(numPartsToTry, partsScanned * 4)}}val left = num - buf.sizeval p = partsScanned until math.min(partsScanned + numPartsToTry, totalParts)val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p)res.foreach(buf ++= _.take(num - buf.size))partsScanned += numPartsToTry}buf.toArray} }
则,所以,代码,如下:
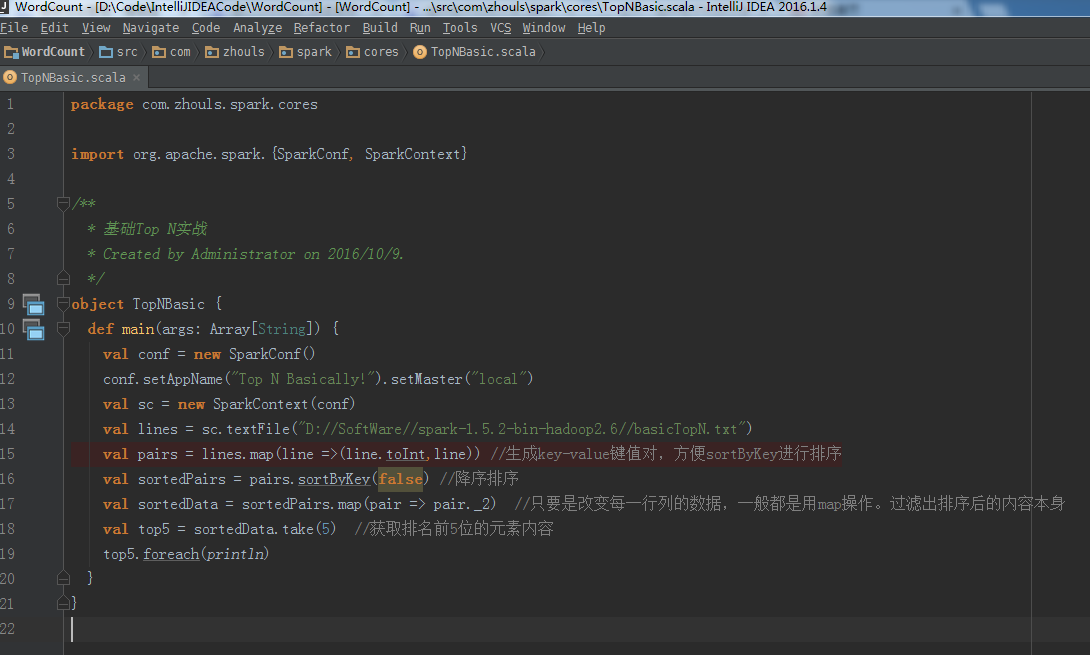
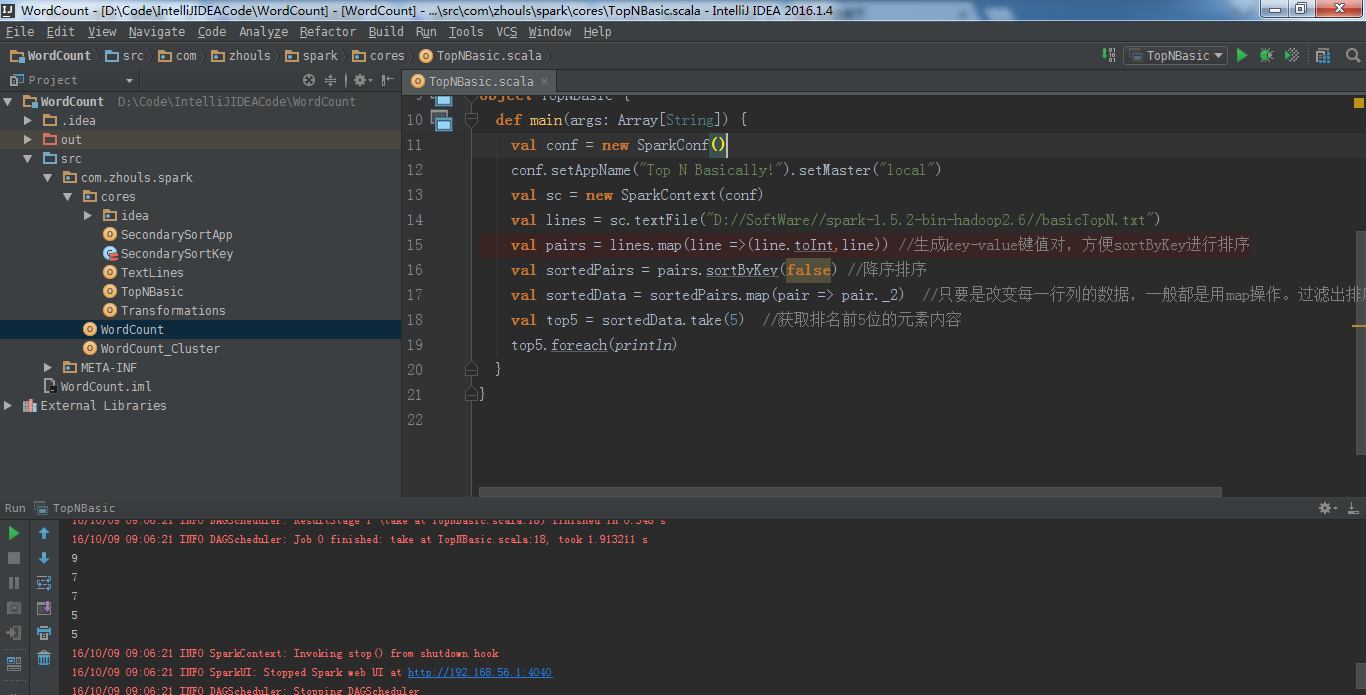
package com.zhouls.spark.coresimport org.apache.spark.{SparkConf, SparkContext}/*** 基础Top N实战* Created by Administrator on 2016/10/9.*/ object TopNBasic {def main(args: Array[String]) {val conf = new SparkConf()conf.setAppName("Top N Basically!").setMaster("local")val sc = new SparkContext(conf)val lines = sc.textFile("D://SoftWare//spark-1.5.2-bin-hadoop2.6//basicTopN.txt")val pairs = lines.map(line =>(line.toInt,line)) //生成key-value键值对,方便sortByKey进行排序val sortedPairs = pairs.sortByKey(false) //降序排序val sortedData = sortedPairs.map(pair => pair._2) //只要是改变每一行列的数据,一般都是用map操作。过滤出排序后的内容本身val top5 = sortedData.take(5) //获取排名前5位的元素内容 top5.foreach(println)} }
好的,这里,学个新知识点。
setLogLevel
看源码
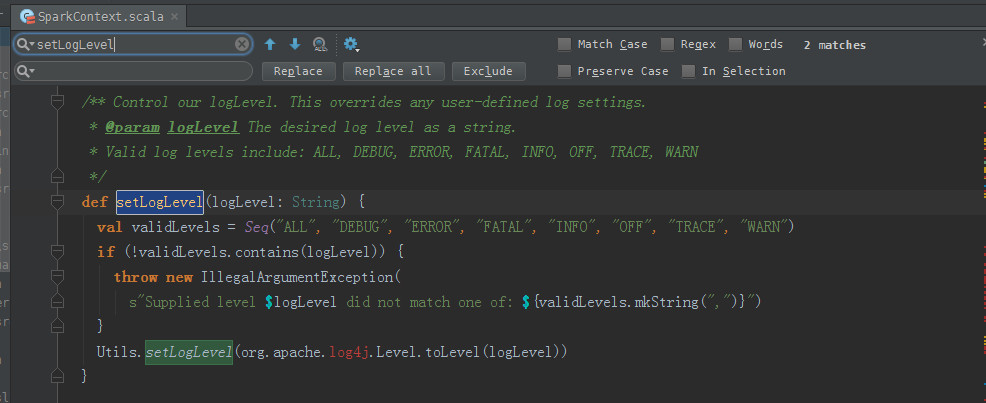
/** Control our logLevel. This overrides any user-defined log settings.* @param logLevel The desired log level as a string.* Valid log levels include: ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN*/ def setLogLevel(logLevel: String) {val validLevels = Seq("ALL", "DEBUG", "ERROR", "FATAL", "INFO", "OFF", "TRACE", "WARN")if (!validLevels.contains(logLevel)) {throw new IllegalArgumentException(s"Supplied level $logLevel did not match one of: ${validLevels.mkString(",")}")}Utils.setLogLevel(org.apache.log4j.Level.toLevel(logLevel)) }
setLogLevel("ALL")
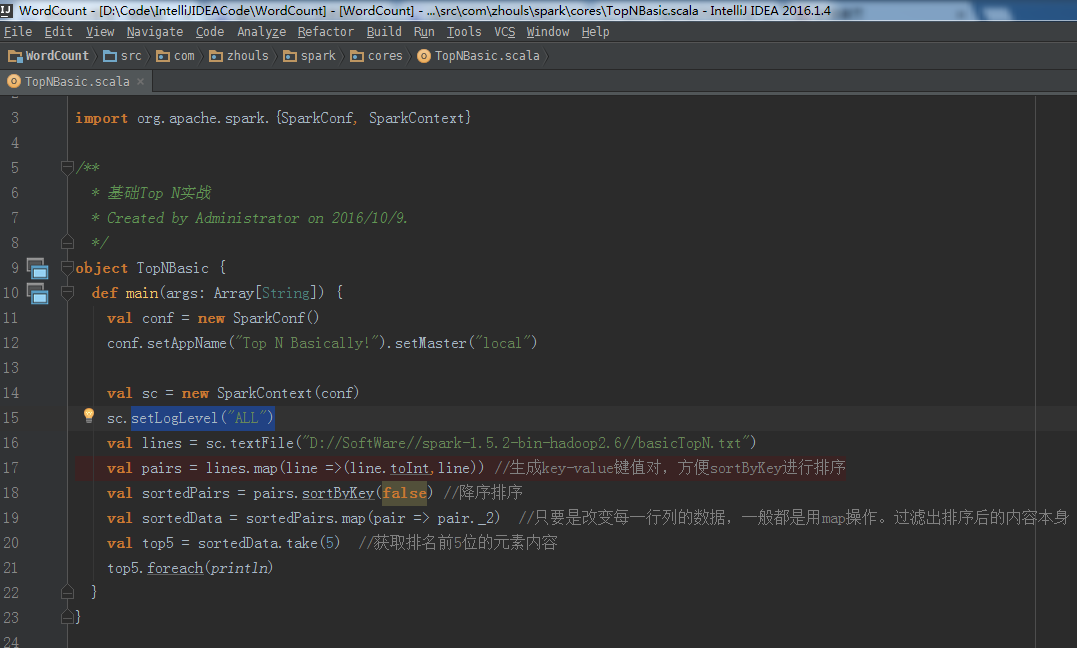
对应的打印输出信息,
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7533 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program
artitions
d size 1814.0 B, free 976.2 MB)
16/10/09 09:15:38 DEBUG AkkaRpcEnv$$anonfun$actorRef$lzycompute$1$1$$anon$1: [actor] received message AkkaMessage(UpdateBlockInfo(BlockManagerId(driver, localhost, 52833),broadcast_2_piece0,StorageLevel(false, true, false, false, 1),1814,0,0),true) from Actor[akka://sparkDriver/temp/$g]
16/10/09 09:15:38 DEBUG AkkaRpcEnv$$anonfun$actorRef$lzycompute$1$1$$anon$1: Received RPC message: AkkaMessage(UpdateBlockInfo(BlockManagerId(driver, localhost, 52833),broadcast_2_piece0,StorageLevel(false, true, false, false, 1),1814,0,0),true)
16/10/09 09:15:38 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:52833 (size: 1814.0 B, free: 976.3 MB)
16/10/09 09:15:38 DEBUG AkkaRpcEnv$$anonfun$actorRef$lzycompute$1$1$$anon$1: [actor] handled message (3.09051 ms) AkkaMessage(UpdateBlockInfo(BlockManagerId(driver, localhost, 52833),broadcast_2_piece0,StorageLevel(false, true, false, false, 1),1814,0,0),true) from Actor[akka://sparkDriver/temp/$g]
16/10/09 09:15:38 DEBUG BlockManagerMaster: Updated info of block broadcast_2_piece0
16/10/09 09:15:38 DEBUG BlockManager: Told master about block broadcast_2_piece0
16/10/09 09:15:38 DEBUG BlockManager: Put block broadcast_2_piece0 locally took 8 ms
16/10/09 09:15:38 DEBUG BlockManager: Putting block broadcast_2_piece0 without replication took 9 ms
16/10/09 09:15:38 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:861
bytes)
16/10/09 09:15:39 TRACE DAGScheduler: failed: Set()
16/10/09 09:15:39 INFO DAGScheduler: Job 0 finished: take at TopNBasic.scala:20, took 1.022280 s
9
7
7
5
5
16/10/09 09:15:39 INFO SparkContext: Invoking stop() from shutdown hook
age (5.094032 ms) AkkaMessage(StopCoordinator,false) from Actor[akka://sparkDriver/deadLetters]
16/10/09 09:15:39 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-3656d24c-bfdb-4def-b751-8d7fc84150cb
Process finished with exit code 0
setLogLevel("DEBUG")
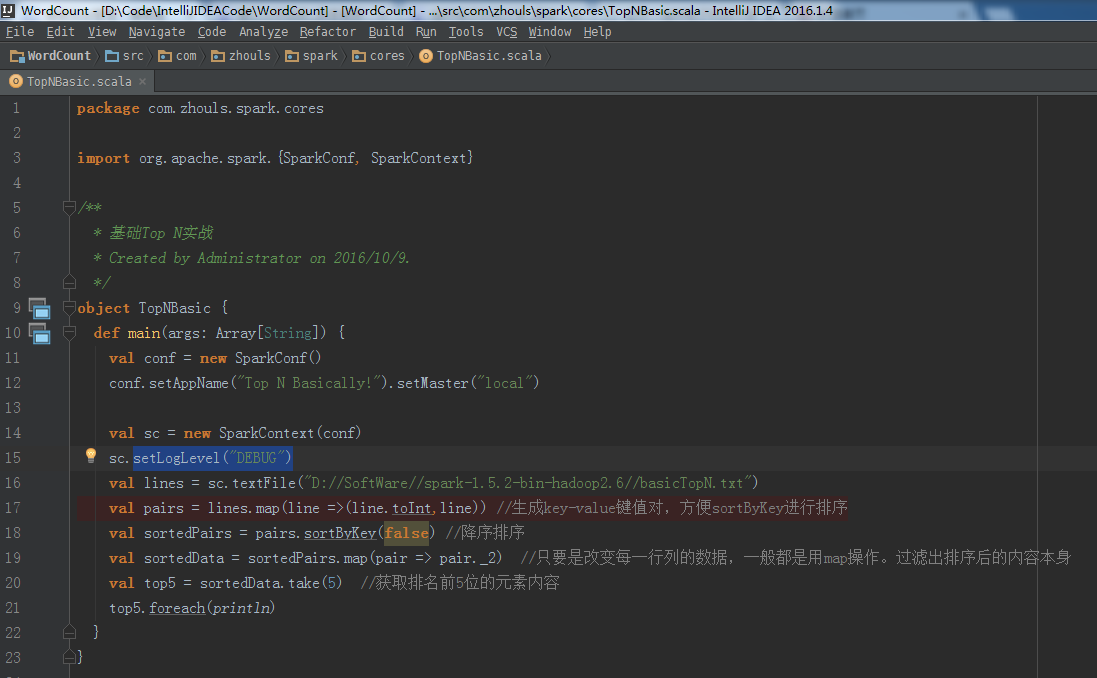
对应的,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7534 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\nashorn.jar;C:\Program fun$28
16/10/09 09:18:05 DEBUG AkkaRpcEnv$$anonfun$actorRef$lzycompute$1$1$$anon$1: [actor] handled message (2.022709 ms) AkkaMessage(StatusUpdate(1,FINISHED,java.nio.HeapByteBuffer[pos=0 lim=1185 cap=1185]),false) from Actor[akka://sparkDriver/deadLetters]
16/10/09 09:18:05 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 153 ms on localhost (1/1)
16/10/09 09:18:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/10/09 09:18:05 INFO DAGScheduler: ResultStage 1 (take at TopNBasic.scala:20) finished in 0.163 s
16/10/09 09:18:05 DEBUG DAGScheduler: After removal of stage 1, remaining stages = 1
16/10/09 09:18:05 DEBUG DAGScheduler: After removal of stage 0, remaining stages = 0
16/10/09 09:18:05 INFO DAGScheduler: Job 0 finished: take at TopNBasic.scala:20, took 0.985550 s
9
7
7
5
5
16/10/09 09:18:05 INFO SparkContext: Invoking stop() from shutdown hook
16/10/09 09:18:05 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
16/10/09 09:18:05 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-c9f238f3-9210-4f3a-a248-11f6f610163e
Process finished with exit code 0
setLogLevel("ERROR")

对应地,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7535 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\access-bridge-64.jar;C:\Program
16/10/09 09:18:43 INFO BlockManagerMasterEndpoint: Registering block manager localhost:52966 with 976.3 MB RAM, BlockManagerId(driver, localhost, 52966)
16/10/09 09:18:43 INFO BlockManagerMaster: Registered BlockManager
9
7
7
5
5
16/10/09 09:18:50 WARN QueuedThreadPool: 3 threads could not be stopped
Process finished with exit code 0
setLogLevel("FATAL")
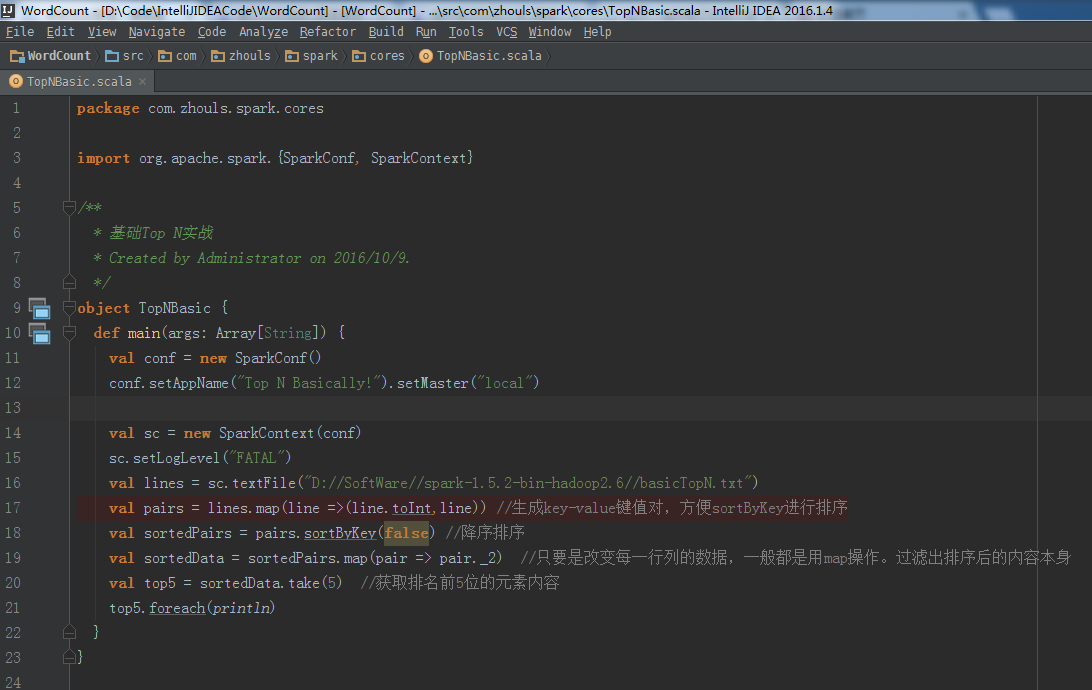
对应地,打印输出信息, 是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7536 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\access-bridge-64.jar;C:\Program
16/10/09 09:20:17 INFO BlockManagerMasterEndpoint: Registering block manager localhost:53014 with 976.3 MB RAM, BlockManagerId(driver, localhost, 53014)
16/10/09 09:20:17 INFO BlockManagerMaster: Registered BlockManager
9
7
7
5
5
Process finished with exit code 0
setLogLevel("INFO")

对应地,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7537 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\access-bridge-64.jar;C:\Program
16/10/09 09:21:17 INFO DAGScheduler: Job 0 finished: take at TopNBasic.scala:20, took 1.085930 s
9
7
7
5
5
16/10/09 09:21:17 INFO SparkContext: Invoking stop() from shutdown hook
16/10/09 09:21:17 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
16/10/09 09:21:17 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-de03b369-fec4-4785-abec-563c502d0bd7
Process finished with exit code 0
setLogLevel("OFF")
对应地,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7538 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program
16/10/09 09:22:10 INFO BlockManagerMasterEndpoint: Registering block manager localhost:53098 with 976.3 MB RAM, BlockManagerId(driver, localhost, 53098)
16/10/09 09:22:10 INFO BlockManagerMaster: Registered BlockManager
9
7
7
5
5
Process finished with exit code 0
setLogLevel("TRACE")
对应地,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7539 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_66\jre\lib\ext\access-bridge-64.jar;C:\Program
16/10/09 09:23:15 TRACE DAGScheduler: running: Set()
16/10/09 09:23:15 TRACE DAGScheduler: waiting: Set()
16/10/09 09:23:15 TRACE DAGScheduler: failed: Set()
16/10/09 09:23:15 INFO DAGScheduler: Job 0 finished: take at TopNBasic.scala:20, took 0.985096 s
9
7
7
5
5
16/10/09 09:23:15 INFO SparkContext: Invoking stop() from shutdown hook
16/10/09 09:23:15 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
16/10/09 09:23:15 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-d3604805-b6e2-4873-a8aa-10cabda4f329
Process finished with exit code 0
setLogLevel("WARN")

对应地,打印输出信息,是
"C:\Program Files\Java\jdk1.8.0_66\bin\java" -Didea.launcher.port=7532 "-Didea.launcher.bin.path=D:\SoftWare\IntelliJ IDEA\IntelliJ IDEA Community Edition 2016.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_66\jre\lib\charsets.jar;C:\Program fe80:0:0:0:0:5efe:c0a8:bf02%net11, but we couldn't find any external IP address!
9
7
7
5
5
Process finished with exit code 0
总结:基础Top N算法实战至此。
2、分组Top N算法实战
先从Java语言,来实战


写代码


Spark 100 Hadoop 65 Spark 99 Hadoop 61 Spark 195 Hadoop 60 Spark 98 Hadoop 69 Spark 91 Hadoop 64 Spark 89 Hadoop 98 Spark 88 Hadoop 99 Spark 68 Hadoop 60 Spark 79 Hadoop 97 Spark 69 Hadoop 96

package com.zhouls.spark.SparkApps.cores;import java.util.Arrays; import java.util.Iterator; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2;public class TopNGroup { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("TopNGroup").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); //其底层实际上就是Scala的SparkContext JavaRDD<String> lines = sc.textFile("D://SoftWare//spark-1.5.2-bin-hadoop2.6//groupTopN.txt");JavaPairRDD<String, Integer> pairs = lines.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID =1L ; @Override public Tuple2<String, Integer> call(String line) throws Exception {String[] splitedLine =line.split(" "); System.out.println(splitedLine[0]); return new Tuple2<String,Integer>(splitedLine[0],Integer.valueOf(splitedLine[1])); } });JavaPairRDD<String, Iterable<Integer>> groupedPairs =pairs.groupByKey();JavaPairRDD<String, Iterable<Integer>> top5=groupedPairs.mapToPair(new PairFunction<Tuple2<String,Iterable<Integer>>, String, Iterable<Integer>>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Iterable<Integer>> call(Tuple2<String, Iterable<Integer>> groupedData) throws Exception { // TODO Auto-generated method stub Integer[] top5=new Integer[5]; String groupedKey= groupedData._1; Iterator<Integer> groupedValue = groupedData._2.iterator();while(groupedValue.hasNext()){ Integer value = groupedValue.next();for (int i =0; i<5; i++){ if (top5[i] ==null) { top5[i] = value ; break; } else if (value > top5[i]) { for (int j = 4; j > i; j--){ top5[j] = top5[j-1]; } top5[i]=value; break; } }} return new Tuple2<String, Iterable<Integer>>(groupedKey,Arrays.asList(top5)); } }) ;//打印分组后的Top N top5.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { @Override public void call(Tuple2<String, Iterable<Integer>> topped) throws Exception {System.out.println("Group key :"+ topped._1);//获取Group key Iterator<Integer> toppedValue = topped._2.iterator(); //获取Group Value while (toppedValue.hasNext()){ //具体打印出每组的Top N Integer value =toppedValue.next(); System.out.println(value); } System.out.println("******************************************************88"); } });} }
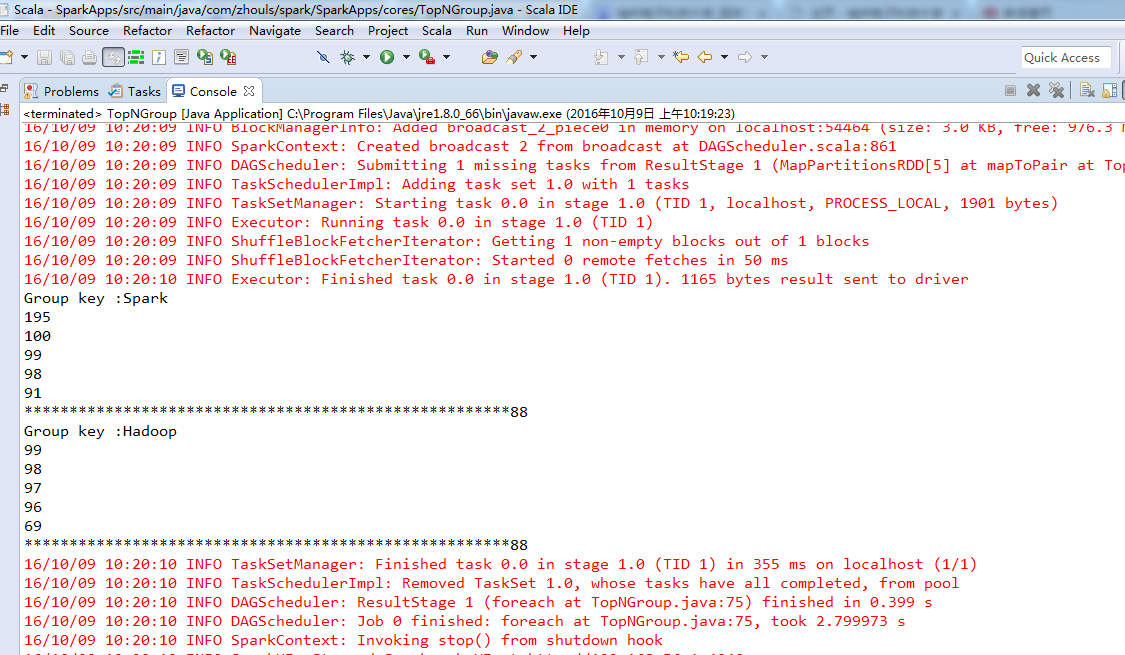
感谢下面的博主:
http://www.it610.com/article/5193051.htm
若是groupTopN.txt的内容是:
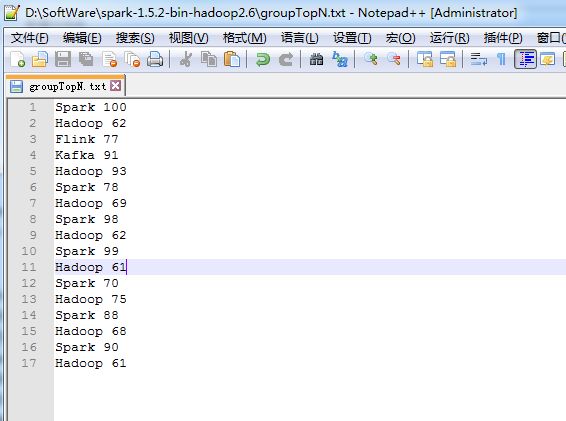
Spark 100 Hadoop 62 Flink 77 Kafka 91 Hadoop 93 Spark 78 Hadoop 69 Spark 98 Hadoop 62 Spark 99 Hadoop 61 Spark 70 Hadoop 75 Spark 88 Hadoop 68 Spark 90 Hadoop 61
则,对应地是,
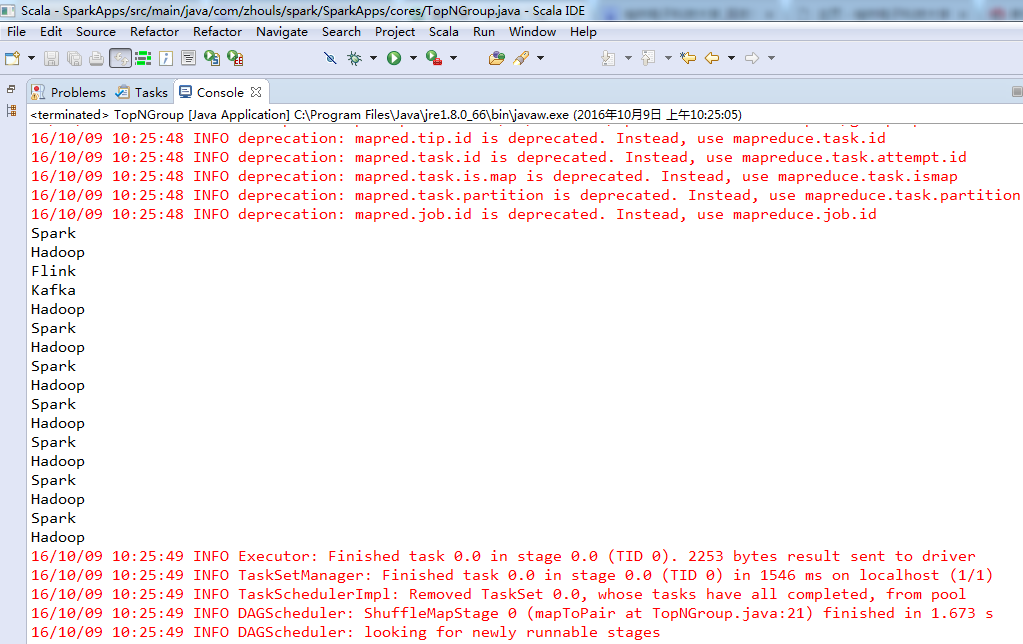
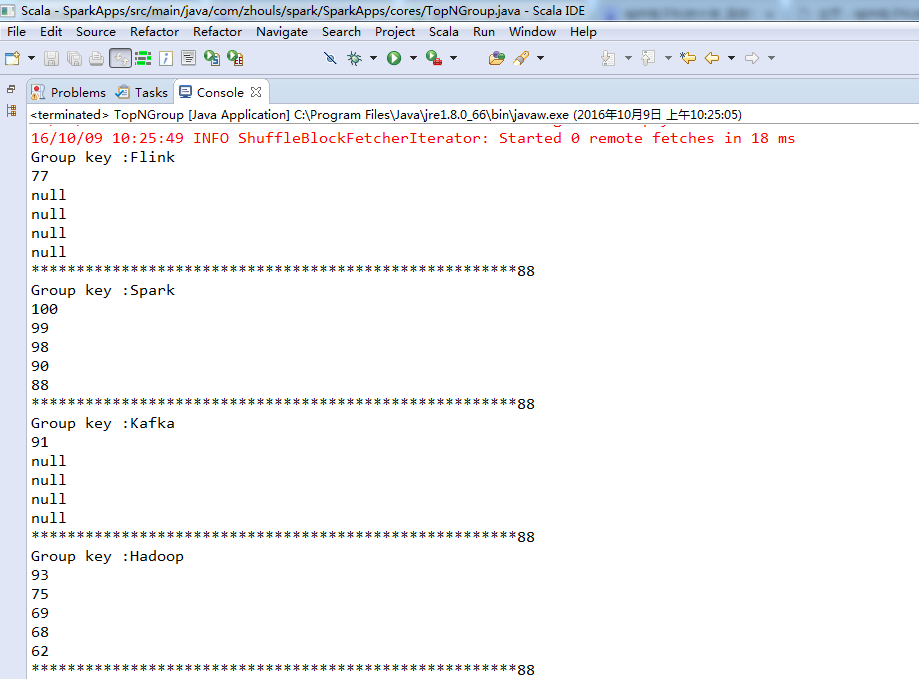
分组Top N算法实战的总结:
分组TOPN排序
1.读入每行数据 JavaRDD<String> lines
2、生成pairs K,V键值对 JavaPairRDD<String, Integer> pairs
输入一行的数据
输出的KEY值是名称,Value是分数 Iterable;
3、groupByKey按名称进行分组: JavaPairRDD<String, Iterable<Integer>> groupedPairs =pairs.groupByKey();
4、分组以后进行排序
输入groupdata,其中 KEY是名称的组名,VALUE是分数的集合
输出 KEY:分组排序以后的组名,VALUE:是排序以后的分数的集合 取5个值
JavaPairRDD<String, Iterable<Integer>> top5=groupedPairs.mapToPair(new
PairFunction<Tuple2<String,Iterable<Integer>>, String, Iterable<Integer>>() {
3、排序算法RangePartitioner内幕解密
/*** Sort the RDD by key, so that each partition contains a sorted range of the elements. Calling* `collect` or `save` on the resulting RDD will return or output an ordered list of records* (in the `save` case, they will be written to multiple `part-X` files in the filesystem, in* order of the keys).*/ // TODO: this currently doesn't work on P other than Tuple2! def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] = self.withScope {val part = new RangePartitioner(numPartitions, self, ascending)new ShuffledRDD[K, V, V](self, part).setKeyOrdering(if (ascending) ordering else ordering.reverse) }
RangePartitioner主要是依赖的RDD的数据划分成不同的范围,关键的地方是不同的范围是有序的。
RangePartitioner除了是结果有序的基石以外,最为重要的是尽量保证每个Partition中的数据量是均匀的!
Google的面试题:如何在一个不确定数据规模的范围内,进行排序。
排序的几个内容:
1、二分算法,将key值放入对于的分区
在未接触二分查找算法时,最通用的一种做法是,对数组进行遍历,跟每个元素进行比较,其时间为O(n).但二分查找算法则
更优,因为其查找时间为O(lgn),譬如数组{1, 2, 3, 4, 5, 6, 7, 8, 9},查找元素6,用二分查找的算法执行的话,
其顺序为:
1.第一步查找中间元素,即5,由于5<6,则6必然在5之后的数组元素中,那么就在{6, 7, 8, 9}中查找,
2.寻找{6, 7, 8, 9}的中位数,为7,7>6,则6应该在7左边的数组元素中,那么只剩下6,即找到了。
2、水桶抽样算法,(适合数据规模是特别大,内存容纳不下时的情况)以下乘以3的原因
乘3的原因是RDD的分区可能有数据倾斜,sampleSize是期望的样本大小,但是某些分区的数据量可能少于
sampleSize/PartitionNumber,乘以3后期望其他的分区可以多采样点数据,使得总的采样量达到或超过sampleSize。
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and a little bit.
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toInt


/** Licensed to the Apache Software Foundation (ASF) under one or more* contributor license agreements. See the NOTICE file distributed with* this work for additional information regarding copyright ownership.* The ASF licenses this file to You under the Apache License, Version 2.0* (the "License"); you may not use this file except in compliance with* the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.sparkimport java.io.{IOException, ObjectInputStream, ObjectOutputStream}import scala.collection.mutable import scala.collection.mutable.ArrayBuffer import scala.reflect.{ClassTag, classTag} import scala.util.hashing.byteswap32import org.apache.spark.rdd.{PartitionPruningRDD, RDD} import org.apache.spark.serializer.JavaSerializer import org.apache.spark.util.{CollectionsUtils, Utils} import org.apache.spark.util.random.{XORShiftRandom, SamplingUtils}/*** An object that defines how the elements in a key-value pair RDD are partitioned by key.* Maps each key to a partition ID, from 0 to `numPartitions - 1`.*/ abstract class Partitioner extends Serializable {def numPartitions: Intdef getPartition(key: Any): Int }object Partitioner {/*** Choose a partitioner to use for a cogroup-like operation between a number of RDDs.** If any of the RDDs already has a partitioner, choose that one.** Otherwise, we use a default HashPartitioner. For the number of partitions, if* spark.default.parallelism is set, then we'll use the value from SparkContext* defaultParallelism, otherwise we'll use the max number of upstream partitions.** Unless spark.default.parallelism is set, the number of partitions will be the* same as the number of partitions in the largest upstream RDD, as this should* be least likely to cause out-of-memory errors.** We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD.*/def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reversefor (r <- bySize if r.partitioner.isDefined && r.partitioner.get.numPartitions > 0) {return r.partitioner.get}if (rdd.context.conf.contains("spark.default.parallelism")) {new HashPartitioner(rdd.context.defaultParallelism)} else {new HashPartitioner(bySize.head.partitions.size)}} }/*** A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using* Java's `Object.hashCode`.** Java arrays have hashCodes that are based on the arrays' identities rather than their contents,* so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will* produce an unexpected or incorrect result.*/ class HashPartitioner(partitions: Int) extends Partitioner {require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")def numPartitions: Int = partitionsdef getPartition(key: Any): Int = key match {case null => 0case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)}override def equals(other: Any): Boolean = other match {case h: HashPartitioner =>h.numPartitions == numPartitionscase _ =>false}override def hashCode: Int = numPartitions }/*** A [[org.apache.spark.Partitioner]] that partitions sortable records by range into roughly* equal ranges. The ranges are determined by sampling the content of the RDD passed in.** Note that the actual number of partitions created by the RangePartitioner might not be the same* as the `partitions` parameter, in the case where the number of sampled records is less than* the value of `partitions`.*/ class RangePartitioner[K : Ordering : ClassTag, V](@transient partitions: Int,@transient rdd: RDD[_ <: Product2[K, V]],private var ascending: Boolean = true)extends Partitioner {// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")private var ordering = implicitly[Ordering[K]]// An array of upper bounds for the first (partitions - 1) partitionsprivate var rangeBounds: Array[K] = {if (partitions <= 1) {Array.empty} else {// This is the sample size we need to have roughly balanced output partitions, capped at 1M.val sampleSize = math.min(20.0 * partitions, 1e6)// Assume the input partitions are roughly balanced and over-sample a little bit.val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toIntval (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)if (numItems == 0L) {Array.empty} else {// If a partition contains much more than the average number of items, we re-sample from it// to ensure that enough items are collected from that partition.val fraction = math.min(sampleSize / math.max(numItems, 1L), 1.0)val candidates = ArrayBuffer.empty[(K, Float)]val imbalancedPartitions = mutable.Set.empty[Int]sketched.foreach { case (idx, n, sample) =>if (fraction * n > sampleSizePerPartition) {imbalancedPartitions += idx} else {// The weight is 1 over the sampling probability.val weight = (n.toDouble / sample.size).toFloatfor (key <- sample) {candidates += ((key, weight))}}}if (imbalancedPartitions.nonEmpty) {// Re-sample imbalanced partitions with the desired sampling probability.val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)val seed = byteswap32(-rdd.id - 1)val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()val weight = (1.0 / fraction).toFloatcandidates ++= reSampled.map(x => (x, weight))}RangePartitioner.determineBounds(candidates, partitions)}}}def numPartitions: Int = rangeBounds.length + 1private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K]def getPartition(key: Any): Int = {val k = key.asInstanceOf[K]var partition = 0if (rangeBounds.length <= 128) {// If we have less than 128 partitions naive searchwhile (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {partition += 1}} else {// Determine which binary search method to use only once.partition = binarySearch(rangeBounds, k)// binarySearch either returns the match location or -[insertion point]-1if (partition < 0) {partition = -partition-1}if (partition > rangeBounds.length) {partition = rangeBounds.length}}if (ascending) {partition} else {rangeBounds.length - partition}}override def equals(other: Any): Boolean = other match {case r: RangePartitioner[_, _] =>r.rangeBounds.sameElements(rangeBounds) && r.ascending == ascendingcase _ =>false}override def hashCode(): Int = {val prime = 31var result = 1var i = 0while (i < rangeBounds.length) {result = prime * result + rangeBounds(i).hashCodei += 1}result = prime * result + ascending.hashCoderesult}@throws(classOf[IOException])private def writeObject(out: ObjectOutputStream): Unit = Utils.tryOrIOException {val sfactory = SparkEnv.get.serializersfactory match {case js: JavaSerializer => out.defaultWriteObject()case _ =>out.writeBoolean(ascending)out.writeObject(ordering)out.writeObject(binarySearch)val ser = sfactory.newInstance()Utils.serializeViaNestedStream(out, ser) { stream =>stream.writeObject(scala.reflect.classTag[Array[K]])stream.writeObject(rangeBounds)}}}@throws(classOf[IOException])private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {val sfactory = SparkEnv.get.serializersfactory match {case js: JavaSerializer => in.defaultReadObject()case _ =>ascending = in.readBoolean()ordering = in.readObject().asInstanceOf[Ordering[K]]binarySearch = in.readObject().asInstanceOf[(Array[K], K) => Int]val ser = sfactory.newInstance()Utils.deserializeViaNestedStream(in, ser) { ds =>implicit val classTag = ds.readObject[ClassTag[Array[K]]]()rangeBounds = ds.readObject[Array[K]]()}}} }private[spark] object RangePartitioner {/*** Sketches the input RDD via reservoir sampling on each partition.** @param rdd the input RDD to sketch* @param sampleSizePerPartition max sample size per partition* @return (total number of items, an array of (partitionId, number of items, sample))*/def sketch[K : ClassTag](rdd: RDD[K],sampleSizePerPartition: Int): (Long, Array[(Int, Int, Array[K])]) = {val shift = rdd.id// val classTagK = classTag[K] // to avoid serializing the entire partitioner objectval sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>val seed = byteswap32(idx ^ (shift << 16))val (sample, n) = SamplingUtils.reservoirSampleAndCount(iter, sampleSizePerPartition, seed)Iterator((idx, n, sample))}.collect()val numItems = sketched.map(_._2.toLong).sum(numItems, sketched)}/*** Determines the bounds for range partitioning from candidates with weights indicating how many* items each represents. Usually this is 1 over the probability used to sample this candidate.** @param candidates unordered candidates with weights* @param partitions number of partitions* @return selected bounds*/def determineBounds[K : Ordering : ClassTag](candidates: ArrayBuffer[(K, Float)],partitions: Int): Array[K] = {val ordering = implicitly[Ordering[K]]val ordered = candidates.sortBy(_._1)val numCandidates = ordered.sizeval sumWeights = ordered.map(_._2.toDouble).sumval step = sumWeights / partitionsvar cumWeight = 0.0var target = stepval bounds = ArrayBuffer.empty[K]var i = 0var j = 0var previousBound = Option.empty[K]while ((i < numCandidates) && (j < partitions - 1)) {val (key, weight) = ordered(i)cumWeight += weightif (cumWeight > target) {// Skip duplicate values.if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {bounds += keytarget += stepj += 1previousBound = Some(key)}}i += 1}bounds.toArray} }
如,源码中的
水桶抽样算法,(适合数据规模是特别大,内存容纳不下时的情况)以下乘以3的原因
乘3的原因是RDD的分区可能有数据倾斜,sampleSize是期望的样本大小,但是某些分区的数据量可能少于
sampleSize/PartitionNumber,乘以3后期望其他的分区可以多采样点数据,使得总的采样量达到或超过sampleSize。
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and a little bit.
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toInt
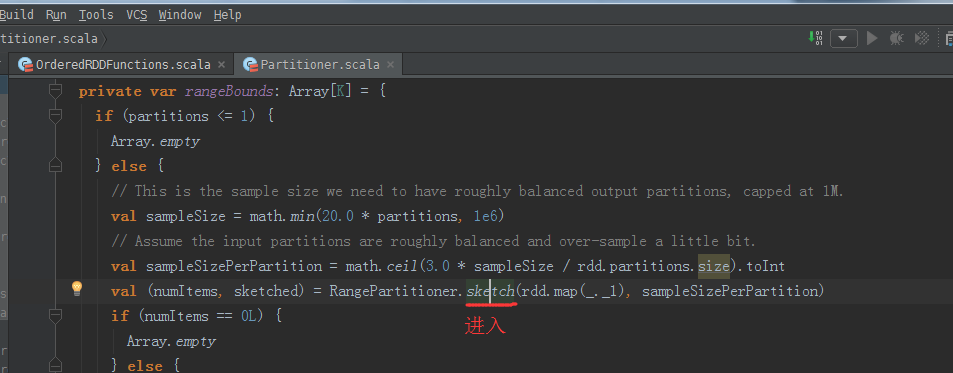
sketch源码
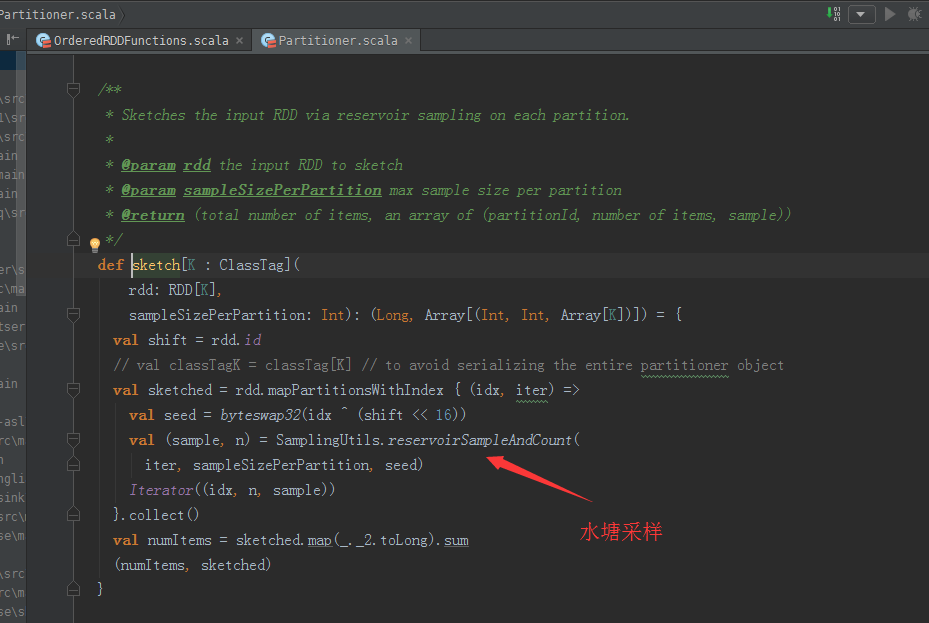
/*** Sketches the input RDD via reservoir sampling on each partition.** @param rdd the input RDD to sketch* @param sampleSizePerPartition max sample size per partition* @return (total number of items, an array of (partitionId, number of items, sample))*/ def sketch[K : ClassTag](rdd: RDD[K],sampleSizePerPartition: Int): (Long, Array[(Int, Int, Array[K])]) = {val shift = rdd.id// val classTagK = classTag[K] // to avoid serializing the entire partitioner objectval sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>val seed = byteswap32(idx ^ (shift << 16))val (sample, n) = SamplingUtils.reservoirSampleAndCount(iter, sampleSizePerPartition, seed)Iterator((idx, n, sample))}.collect()val numItems = sketched.map(_._2.toLong).sum(numItems, sketched) }
reservoirSampleAndCount源码


/*** Reservoir sampling implementation that also returns the input size.** @param input input size* @param k reservoir size* @param seed random seed* @return (samples, input size)*/ def reservoirSampleAndCount[T: ClassTag](input: Iterator[T],k: Int,seed: Long = Random.nextLong()): (Array[T], Int) = {val reservoir = new Array[T](k)// Put the first k elements in the reservoir.var i = 0while (i < k && input.hasNext) {val item = input.next()reservoir(i) = itemi += 1}// If we have consumed all the elements, return them. Otherwise do the replacement.if (i < k) {// If input size < k, trim the array to return only an array of input size.val trimReservoir = new Array[T](i)System.arraycopy(reservoir, 0, trimReservoir, 0, i)(trimReservoir, i)} else {// If input size > k, continue the sampling process.val rand = new XORShiftRandom(seed)while (input.hasNext) {val item = input.next()val replacementIndex = rand.nextInt(i)if (replacementIndex < k) {reservoir(replacementIndex) = item}i += 1}(reservoir, i)} }
getPartition源码

def getPartition(key: Any): Int = {val k = key.asInstanceOf[K]var partition = 0if (rangeBounds.length <= 128) {// If we have less than 128 partitions naive searchwhile (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {partition += 1}} else {// Determine which binary search method to use only once.partition = binarySearch(rangeBounds, k)// binarySearch either returns the match location or -[insertion point]-1if (partition < 0) {partition = -partition-1}if (partition > rangeBounds.length) {partition = rangeBounds.length}}if (ascending) {partition} else {rangeBounds.length - partition} }

二分算法,将key值放入对于的分区
在未接触二分查找算法时,最通用的一种做法是,对数组进行遍历,跟每个元素进行比较,其时间为O(n).但二分查找算法则
更优,因为其查找时间为O(lgn),譬如数组{1, 2, 3, 4, 5, 6, 7, 8, 9},查找元素6,用二分查找的算法执行的话,
其顺序为:
1.第一步查找中间元素,即5,由于5<6,则6必然在5之后的数组元素中,那么就在{6, 7, 8, 9}中查找,
2.寻找{6, 7, 8, 9}的中位数,为7,7>6,则6应该在7左边的数组元素中,那么只剩下6,即找到了。
二分算法,确定,具体key属于哪个分区,然后,之后,就可以用RangePartitioner了。
更多,见http://www.it610.com/article/5193051.htm.这篇关于top N彻底解秘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!