本文主要是介绍Linux网络隧道协议IPIP认知(基于Linux network namespace 的 IPIP 隧道通信),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
- 博文内容为 Linux 隧道通信 IPIP认知
- 内容涉及:ipip 介绍,一个 ipip 通信 Demo 以及数据帧流转分析
- 理解不足小伙伴帮忙指正
某些人和事,哪怕没有缘分,是路边的风景,可是只要看一眼,依然会让人觉得很美好。
ipip 是什么?
在 讲 ipip 之前,必须要提 tun 设备,我们用一个 例子来说明
想象一下,你和你的知己,分别住在不同的城市,你想与他进行书信往来。现在,你需要一种方式来将信件从你的城市发送到他们所在的城市。
IPIP 就像是一种邮寄方式,它允许你在信封外面再封装一层信封,将原始的信件放在里面。然后,你可以通过邮政系统将这个封装过的信封发送给你的朋友。在他们收到信封后,他们需要打开外层的信封才能看到里面的原始信件。这样,你就通过IPIP创建了一个逻辑隧道,将信件从一个城市传输到另一个城市。
而TUN就像是一种邮局,它提供了一个虚拟的邮局接口。你可以将你要发送的信件放在TUN接口中,然后通过邮局的系统将信件发送给你的朋友。当你的朋友的邮局接收到信件后,它会将信件放在他们的TUN接口中供他们查看。实际上,TUN是一种虚拟的邮局接口,它模拟了真实的邮局功能,使你能够像操作真实的邮局一样处理和转发信件。
通过结合IPIP和TUN技术,你可以将信件封装在一个外层的信封中(使用IPIP),然后通过邮局系统(使用TUN)将信件发送给你的朋友。这样,你就实现了点对点的虚拟邮寄服务,使你能够与朋友进行书信往来。
这么做的好处:
虚拟环境的连接:类似于邮寄服务可以将信件送达到不同的收件人,点对点虚拟设备可以在虚拟环境中连接不同的虚拟机、容器或者虚拟实例。这样可以实现虚拟环境之间的互通和通信,提升整体系统的协作和效率。分隔和隔离网络:点对点虚拟设备可以将不同的网络环境分隔开来,就像邮寄服务可以将不同的信件分开处理一样。这样可以确保不同网络之间的通信不会相互干扰,提高网络的可管理性和稳定性。隐私和安全性:使用点对点虚拟设备就像在信件中添加了一层额外的封封,这样可以增强隐私和安全性。类似地,点对点虚拟设备可以通过添加加密和认证机制来保护数据的机密性和完整性,确保只有授权的接收方能够访问和解封数据。
tun表示虚拟的点对点设备,工作在L3,之所以叫这个名字,是因为tun经常被用来做隧道通信(tunnel)
通过命令ip tunnel help查看IP隧道的相关操作。
liruilonger@cloudshell:~$ ip tunnel help
Usage: ip tunnel { add | change | del | show | prl | 6rd } [ NAME ][ mode { ipip | gre | sit | isatap | vti } ] [ remote ADDR ] [ local ADDR ][ [i|o]seq ] [ [i|o]key KEY ] [ [i|o]csum ][ prl-default ADDR ] [ prl-nodefault ADDR ] [ prl-delete ADDR ][ 6rd-prefix ADDR ] [ 6rd-relay_prefix ADDR ] [ 6rd-reset ][ ttl TTL ] [ tos TOS ] [ [no]pmtudisc ] [ dev PHYS_DEV ]Where: NAME := STRINGADDR := { IP_ADDRESS | any }TOS := { STRING | 00..ff | inherit | inherit/STRING | inherit/00..ff }TTL := { 1..255 | inherit }KEY := { DOTTED_QUAD | NUMBER }
liruilonger@cloudshell:~$
Linux原生支持下列5种L3隧道:
ipip:即IPv4 in IPv4, 在IPv4报文的基础上封装一个IPv4报文;GRE:即通用路由封装(Generic Routing Encapsulation),定义了在任意一种网络层协议上封装其他任意一种网络层协议的机制,适用于IPv4和IPv6sit:和ipip类似,不同的是sit用IPv4报文封装IPv6报文,即IPv6 over IPv4;ISATAP:即站内自动隧道寻址协议(Intra-Site Automatic Tunnel Addressing Protocol),与sit类似,也用于IPv6的隧道封装;VTI:即虚拟隧道接口(Virtual Tunnel Interface),是思科提出的一种IPSec隧道技术。下面我们以ipip为例,介绍Linux隧道通信的基本原理。
注:Linux L3隧道底层实现原理都基于tun设备
ipip隧道通信 Demo
应为只有一台机器,所以这里我们通过 Linux 上的两个 network namespace 来模拟两个机器节点,每个 network namespce 是一个独立的网络栈
要使用ipip隧道,首先需要内核模块ipip.ko的支持。
通过lsmod|grep ipip查看内核是否加载,若没有则用modprobe ipip加载,正常加载应该显示
liruilonger@cloudshell:~$ lsmod | grep ipip
liruilonger@cloudshell:~$ sudo modprobe ipip
liruilonger@cloudshell:~$ modprobe ipip
liruilonger@cloudshell:~$ lsmod | grep ipip
ipip 16384 0
ip_tunnel 28672 1 ipip
tunnel4 16384 1 ipip
加载ipip内核模块后,就可以创建隧道了。方法是先创建一个tun设备,然后将该tun设备绑定为一个ipip隧道。ipip隧道网络拓扑如图
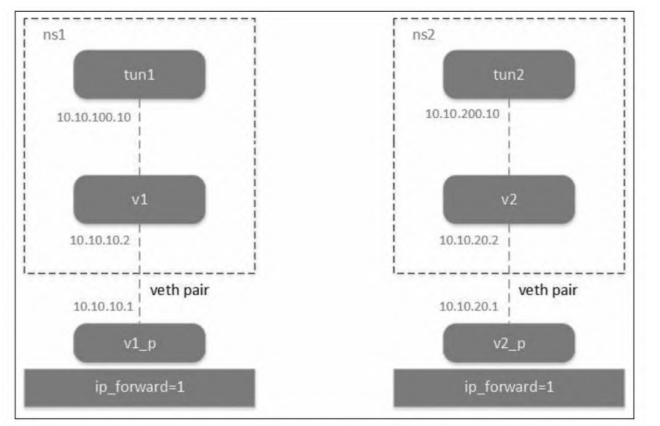
这里我们用两个 Linux network namespace 来模拟 ,创建两个网络命名空间,同时配置两个 veth pair,一端放到命名空间
liruilonger@cloudshell:~$ sudo ip netns add ns1
liruilonger@cloudshell:~$ sudo ip netns add ns2
liruilonger@cloudshell:~$ sudo ip link add v1 netns ns1 type veth peer name v1-P
liruilonger@cloudshell:~$ sudo ip link add v2 netns ns2 type veth peer name v2-P
确认创建的 veth pair
liruilonger@cloudshell:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:10:50:88:eb:09 brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:f9:2d:29:3e brd ff:ff:ff:ff:ff:ff
4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
5: v1-P@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ether 76:81:b0:33:e4:2b brd ff:ff:ff:ff:ff:ff link-netns ns1
6: v2-P@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ether aa:a6:ac:15:b1:64 brd ff:ff:ff:ff:ff:ff link-netns ns2
另一端放到 根网络命名空间,同时两个Veth-pair 配置不同网段IP启动。
liruilonger@cloudshell:~$ sudo ip addr add 10.10.10.1/24 dev v1-P
liruilonger@cloudshell:~$ sudo ip link set v1-P up
liruilonger@cloudshell:~$ sudo ip addr add 10.10.20.1/24 dev v2-P
liruilonger@cloudshell:~$ sudo ip link set v2-P up
命名空间一端的同样配置IP 并启用
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip addr add 10.10.10.2/24 dev v1
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip addr add 10.10.20.2/24 dev v2
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link set v1 up
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link set v2 up
确定设备在线
liruilonger@cloudshell:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:10:50:88:eb:09 brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:f9:2d:29:3e brd ff:ff:ff:ff:ff:ff
4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
5: v1-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000link/ether 76:81:b0:33:e4:2b brd ff:ff:ff:ff:ff:ff link-netns ns1
6: v2-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000link/ether aa:a6:ac:15:b1:64 brd ff:ff:ff:ff:ff:ff link-netns ns2
liruilonger@cloudshell:~$
调整内核参数,开启 ipv4 转发
liruilonger@cloudshell:~$ cat /proc/sys/net/ipv4/ip_forward
1
这个时候,Linux 网络命名空间中的 v1 和 v2 veth 任然不通,应为是在两个不同的网段。
liruilonger@cloudshell:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
查看路由信息,没有通向 10.10.20.0/24网段的路由
所以我们在 ns1 里面配置一条路由,通向 10.10.20.0 的访问路由到 10.10.10.1 网关,实际上是 veth pair 的另一端。
liruilonger@cloudshell:~$ sudo ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1
再查看路由表
liruilonger@cloudshell:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1
liruilonger@cloudshell:~$
同理,也给ns2配上通往10.10.10.0/24网段的路由。
liruilonger@cloudshell:~$ sudo ip netns exec ns2 route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.20.1
liruilonger@cloudshell:~$ sudo ip netns exec ns2 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 10.10.20.1 255.255.255.0 UG 0 0 0 v2
10.10.20.0 0.0.0.0 255.255.255.0 U 0 0 0 v2
liruilonger@cloudshell:~$
这时候我们在 ns1 和 ns2 之间做ping 测试,正常通信
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ping -c 3 10.10.20.2
PING 10.10.20.2 (10.10.20.2) 56(84) bytes of data.
64 bytes from 10.10.20.2: icmp_seq=1 ttl=63 time=0.092 ms
64 bytes from 10.10.20.2: icmp_seq=2 ttl=63 time=0.057 ms
64 bytes from 10.10.20.2: icmp_seq=3 ttl=63 time=0.053 ms--- 10.10.20.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2036ms
rtt min/avg/max/mdev = 0.053/0.067/0.092/0.017 ms
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ping -c 3 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=63 time=0.042 ms
64 bytes from 10.10.10.2: icmp_seq=2 ttl=63 time=0.052 ms
64 bytes from 10.10.10.2: icmp_seq=3 ttl=63 time=0.049 ms--- 10.10.10.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2066ms
rtt min/avg/max/mdev = 0.042/0.047/0.052/0.004 ms
liruilonger@cloudshell:~$
v1 和 v2 可以正常通信,即我们模拟了两个不在同一网段的 Linux 机器
创建tun设备,并设置为ipip隧道
- 在 ns1 上面创建 tun1 设备:
ip tunnel add tunl - 设置
隧道模式为ipip:mode ipip - 设置
隧道端点,用remote和local表示隧道外层IP:remote 10.10.20.2 local 10.10.10.2 - 隧道内层IP配置:
ip addr add 10.10.100.10 peer 10.10.200.10 dev tunl
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip tunnel add tunl mode ipip remote 10.10.20.2 local 10.10.10.2
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link set tunl up
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip addr add 10.10.100.10 peer 10.10.200.10 dev tunl
liruilonger@cloudshell:~$
原始的IP 头
- src: 10.10.100.10
- dst: 10.10.200.10
封装后的IP头
- src: 10.10.10.2 | src: 10.10.100.10
- dst: 10.10.20.2 | dst: 10.10.200.10
同样需要在 ns2 上做相同的配置
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip tunnel add tunr mode ipip remote 10.10.10.2 local 10.10.20.2
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link set tunr up
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip addr add 10.10.200.10 peer 10.10.100.10 dev tunr
liruilonger@cloudshell:~$
到这里 两个 tun 设备的 隧道就建立成功了,我们可以在其中一个命名空间对另一个命名空间的 tun 设备发起 ping 测试
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ping 10.10.200.10 -c 3
PING 10.10.200.10 (10.10.200.10) 56(84) bytes of data.
64 bytes from 10.10.200.10: icmp_seq=1 ttl=64 time=0.091 ms
64 bytes from 10.10.200.10: icmp_seq=2 ttl=64 time=0.062 ms
64 bytes from 10.10.200.10: icmp_seq=3 ttl=64 time=0.067 ms--- 10.10.200.10 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2082ms
rtt min/avg/max/mdev = 0.062/0.073/0.091/0.012 ms
liruilonger@cloudshell:~$
在看一各个命名空间对应的 链接
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
3: v1@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000link/ether 72:de:67:0b:28:e1 brd ff:ff:ff:ff:ff:ff link-netnsid 0
4: tunl@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/ipip 10.10.10.2 peer 10.10.20.2
liruilonger@cloudshell:~$
两个命名空间除了 veth-pair 对应的 veth 虚拟设备,各有个一个 tun 设备,link/ipip 中的内容表示封装后的包的两端地址,即外层IP。
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
3: v2@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000link/ether f2:dd:3c:7d:eb:50 brd ff:ff:ff:ff:ff:ff link-netnsid 0
4: tunr@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/ipip 10.10.20.2 peer 10.10.10.2
liruilonger@cloudshell:~$
ipip隧道通信数据帧流转分析
分析实验过程,ping 命令构建一个ICMP请求,ICMP报文封装在IP报文中,源和目的IP地址分别是10.10.100.10和10.10.200.10。
由于 tunl 和 tunr 不在同一个网段,所以需要查看路由表,通过ip tunnel命令建立ipip隧道后,会自动生成一条路由
liruilonger@cloudshell:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1
10.10.200.10 0.0.0.0 255.255.255.255 UH 0 0 0 tunl
liruilonger@cloudshell:~$ sudo ip netns exec ns2 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 10.10.20.1 255.255.255.0 UG 0 0 0 v2
10.10.20.0 0.0.0.0 255.255.255.0 U 0 0 0 v2
10.10.100.10 0.0.0.0 255.255.255.255 UH 0 0 0 tunr
可以看到,去往目的地 10.10.x00.10 的报文直接从 tunl\tunr 出去了。这是因为上面配置了内层IP,生成对应的路由信息
配置了 ipip 隧道端点,数据包从 tunl/tunr 出去后直接到达外层IP 对应的端点,也就是当前 network namespace 内部的 veth(v1,v2),同时会封装一层新的IP头, 即外层IP 对应的端点
之后就是 v1 和 v2 之间的通信,利用 veth pair 的特性,v1直通v1-P,Linux打开了ip_forward,它相当于一台路由器,10.10.10.0和10.10.20.0 是两条直连路由,所以直接查路由表转发,从 v1-P 转到 v2-P上,这个时候在利用 veth pair 特性,到直接到 v2
liruilonger@cloudshell:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 0a:10:50:88:eb:09 brd ff:ff:ff:ff:ff:ff link-netnsid 0inet 10.88.0.3/16 brd 10.88.255.255 scope global eth0valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:f9:2d:29:3e brd ff:ff:ff:ff:ff:ffinet 172.17.0.1/16 brd 172.17.255.255 scope global docker0valid_lft forever preferred_lft forever
4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
5: v1-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether 76:81:b0:33:e4:2b brd ff:ff:ff:ff:ff:ff link-netns ns1inet 10.10.10.1/24 scope global v1-Pvalid_lft forever preferred_lft forever
6: v2-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether aa:a6:ac:15:b1:64 brd ff:ff:ff:ff:ff:ff link-netns ns2inet 10.10.20.1/24 scope global v2-Pvalid_lft forever preferred_lft forever
liruilonger@cloudshell:~$
到达v2 之后,内核解封装数据包,发现内层IP报文的目的IP地址是10.10.200.10,根据路由,这正是自己配置的ipip隧道的tunr地址,于是将报文交给tunr设备。至此,tunl的ping请求包成功到达tunr。
ICMP 报文的传输特性,有去必有回,所以ns2上会构造ICMP响应报文,并根据以上相同步骤封装和解封装数据包,直至到达 tun1,整个ping过程完成。
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ping 10.10.100.10 -c 3
PING 10.10.100.10 (10.10.100.10) 56(84) bytes of data.
64 bytes from 10.10.100.10: icmp_seq=1 ttl=64 time=0.063 ms
64 bytes from 10.10.100.10: icmp_seq=2 ttl=64 time=0.065 ms
64 bytes from 10.10.100.10: icmp_seq=3 ttl=64 time=0.062 ms--- 10.10.100.10 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2044ms
rtt min/avg/max/mdev = 0.062/0.063/0.065/0.001 ms
liruilonger@cloudshell:~$
Linux内核原生支持5种隧道协议,它们的底层实现都采用tun设备。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 😃
《 Kubernetes 网络权威指南:基础、原理与实践》
© 2018-2024 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
这篇关于Linux网络隧道协议IPIP认知(基于Linux network namespace 的 IPIP 隧道通信)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








