本文主要是介绍基于laspy的点云数据存取及基于Open3D的点云数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、基于laspy的点云数据存取
(一)激光雷达点云数据的LAS存储格式[1]
LAS(LASer)格式是一种为激光雷达点云数据的交换和存档而设计的文件格式,是一种被American Society for Photogrammetry and Remote Sensing(ASPRS)指定的开放二进制格式。LAS格式被广泛使用并被视为激光雷达数据的行业标准。
LAS文件存储的点数据的格式为LAS规范定义的点云数据记录格式之一,自LAS 1.4开始,LAS提供了11种可用点数据存储格式(0-10)。所有点数据记录在文件中必须具有相同的格式。各种提供的存储格式在某些可用数据属性字段不同,如GPS时间、RGB和NIR颜色、波包(局限在空间的某有限范围区域内的波动)等。LAS格式提供可用的11种点数据格式详见文末。

LAS 1.1-1.3文件以32位整数表示三维点X/Y/Z坐标(LAS 1.4文件改为64位)。因此,为了获得实际坐标,必须应用公共头中定义的缩放和偏移量。
LAS格式的每个点数据记录所使用的字节数是在公共头块中明确给出的,因此可以在规范定义的点数据记录格式给出的字段中添加“额外字节”的用户定义字段。在LAS 1.4规范中,以特定EVLR的形式引入了解释此类额外字节的标准化方法。

(二)LAS 1.4公共文件头规范[2]
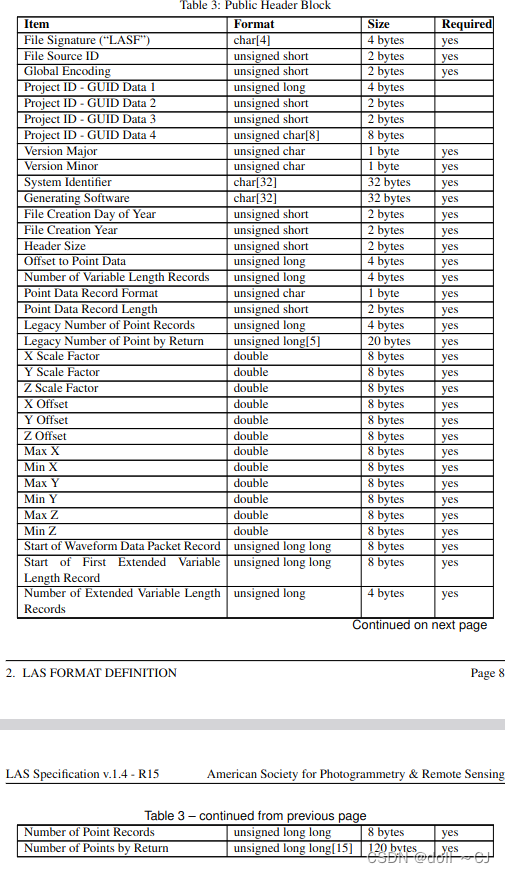
(三)基于laspy库的点云数据存取及文件头信息获取[3][7]
基于laspy库包常规的.las文件存取例程已在使用文档中有良好说明。此处,对使用文档进行一种同时存取XYZ、RGB及类别标签点云数据方法的补充。
实验代码
1、对比LiDAR360、CloudCompare以及PCM(点云魔方)的LAS数据保存(基于同一TXT文件)
依据坐标值计算公式(X/Y/Zcoordinate = X/Y/Zrecord*X/Y/Zscale+X/Y/Zoffset)和TXT记录值(288.500488 71.447800 -50.032101)对比实验结果,可以看出CloudCompare和PCM软件数据存储未改变点顺序,而LiDAR360可能改变了点的存储顺序或其他情况。
# d1-CloudCopare
# d2-LiDAR360
# d3-PCM
# d4-unknownimport laspylas = laspy.read(d~)
print(list(las.point_format.dimension_names))
print(las.header.scales)
print(las.header.offsets)
print(las.x[0],las.y[0],las.z[0])# 测试结果
# d1
['X', 'Y', 'Z', 'intensity', 'return_number', 'number_of_returns', 'scan_direction_flag', 'edge_of_flight_line', 'classification', 'synthetic', 'key_point', 'withheld', 'scan_angle_rank', 'user_data', 'point_source_id', 'red', 'green', 'blue', 'Scalar field']
# point 288.50048799999996 71.4478 -50.032101
# scale [1.e-06 1.e-06 1.e-06]
# offset [0. 0. 0.]# d2
['X', 'Y', 'Z', 'intensity', 'return_number', 'number_of_returns', 'synthetic', 'key_point', 'withheld', 'overlap', 'scanner_channel', 'scan_direction_flag', 'edge_of_flight_line', 'classification', 'user_data', 'scan_angle', 'point_source_id', 'gps_time', '79', '3']
# point -216.8319640507812 -115.86109550781251 -62.66590350854492
# scale [0.0001 0.0001 0.0001]
# offset [-288.87286405 -156.58259551 -70.20670351]# d3
['X', 'Y', 'Z', 'intensity', 'return_number', 'number_of_returns', 'scan_direction_flag', 'edge_of_flight_line', 'classification', 'synthetic', 'key_point', 'withheld', 'scan_angle_rank', 'user_data', 'point_source_id', 'gps_time', 'red', 'green', 'blue']
# point 288.500488 71.4478 -50.032101
# scale [0.001 0.001 0.001]
# offset [288.500488 71.4478 -50.032101]# d4
['X', 'Y', 'Z', 'intensity', 'return_number', 'number_of_returns', 'scan_direction_flag', 'edge_of_flight_line', 'classification', 'synthetic', 'key_point', 'withheld', 'scan_angle_rank', 'user_data', 'point_source_id', 'red', 'green', 'blue']
# point 704114.9195 2609265.6552 23.3599
# scale [0.0001 0.0001 0.0001]
# offset [ 700000. 2600000. 0.]2、以LAS格式同时保存XYZ、RGB以及类别标签Label属性值
若已读取的是LAS格式数据,便可以直接获取其文件头创建同样文件头的LAS文件。否则,需要自行创建并设置文件头。通过实验还发现,LAS版本文档(LAS_1_4_r15)与实际laspy的文件头生成具有一定差异,需要具体情况具体分析。
import numpy as np
import laspy# 创造模拟数据
XYZRGB = np.asarray([[1,1,1,2,2,2],[3,3,3,4,4,4]])
label = np.asarray([1,3])
# LAS文件存储(包含XYZ、RGB、label)
new_header = laspy.LasHeader(version="1.4",point_format=7)
new_header.scales = np.array([1.0,1.0,1.0])
new_header.offsets = np.array([0.0,0.0,0.0])
new_las = laspy.LasData(new_header)
new_las.x = XYZRGB[...,0]
new_las.y = XYZRGB[...,1]
new_las.z = XYZRGB[...,2]
new_las.red = XYZRGB[...,3]
new_las.green = XYZRGB[...,4]
new_las.blue = XYZRGB[...,5]
new_las.classification = label
# 保存LAS文件
new_las.write("Output/LAS_testDATA.las")# 测试存储结果
las = laspy.read("Output/LAS_testDATA.las")
print(list(las.point_format.dimension_names))
print(las.header.scales)
print(las.header.offsets)
print(las.header.point_count)
print(las.xyz[0],las.red[0],las.classification[0])
print(las.xyz[1],las.red[1],las.classification[1])
二、基于Open3D的点云数据可视化
基于Open3D函数o3d.visualization.draw_geometries([PCD])可视化的点云,其依据PCD.colors属性值(该属性值范围应为[0,1])附色。高阶自定义可视化具体实现代码及RGB颜色配色表详见参考资料[4][5][6]。
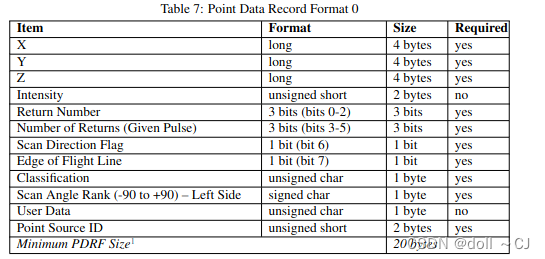
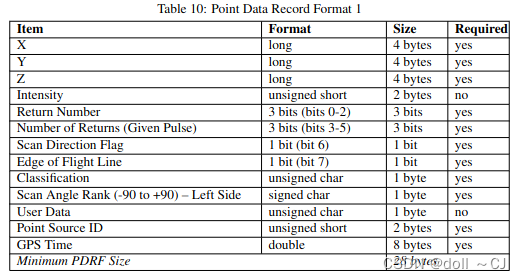
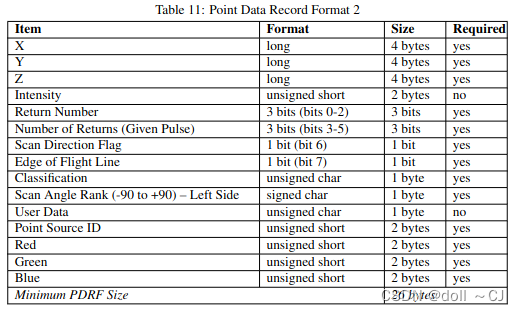
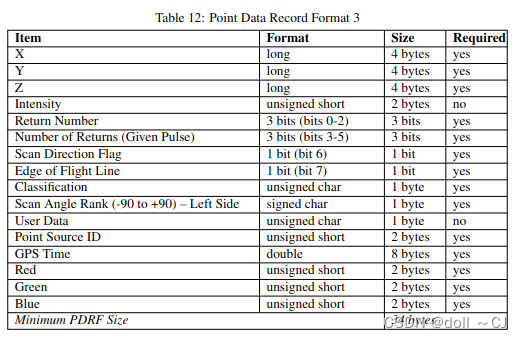
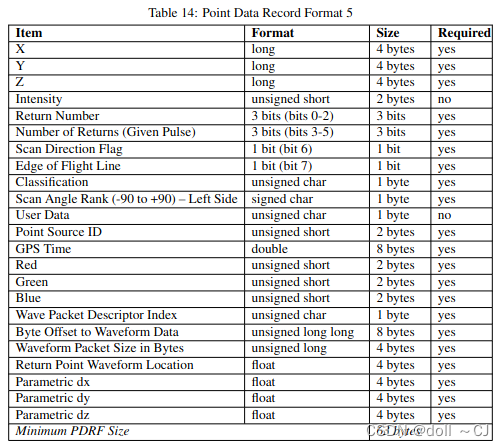
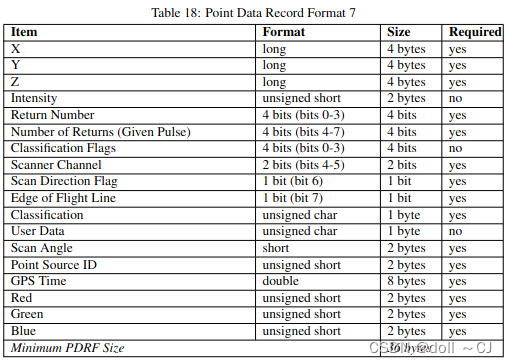
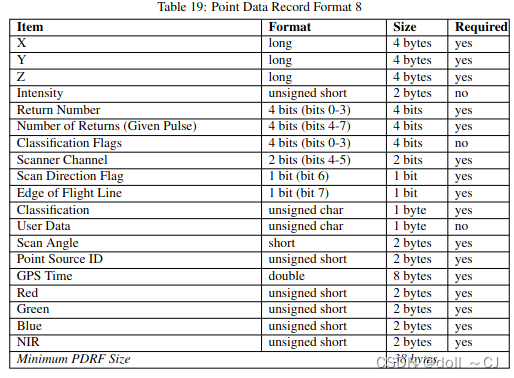
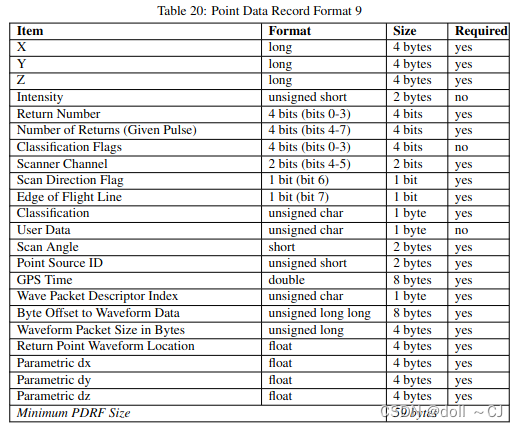
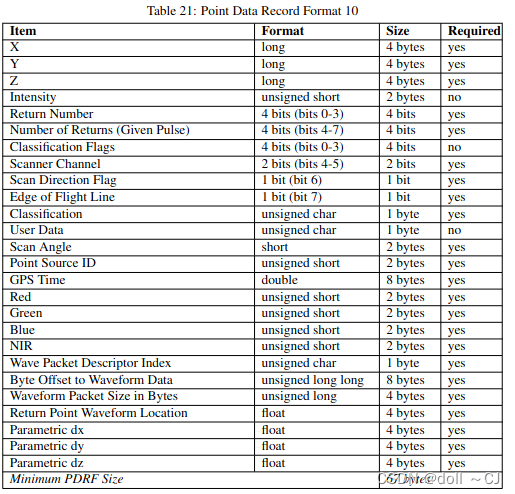
三、LAS提供的11种点数据存储格式[2]
通过对比可以得到如下信息(bit-位 / byte-字节):
1、Format 0是基础格式,其所有属性字段是其它版本的基本属性字段;
2、自Format 6以后(Format 6-10),属性字段添加Classification Flags;
3、Format 7、 Format 8、Format 10同时拥有XYZ、RGB、Classification Flags属性字段;
4、Format 6、 Format 7、Format 8、Format 9、Format 10同时拥有XYZ、Classification Flags属性字段(无RGB属性字段)。


四、ASPRS点云数据类别标签统一规范

参考资料:
[1] https://en.wikipedia.org/wiki/LAS_file_format
[2] https://www.asprs.org/wp-content/uploads/2019/07/LAS_1_4_r15.pdf
[3] Basic Manipulation — laspy 2.5.0 documentation
[4] Customized visualization - Open3D 0.18.0 documentation
[5] 【Open3d】使用open3d可视化-CSDN博客
[6] RGB颜色对照表_高级的金色rgb-CSDN博客
[7] A Complete Example — laspy 2.5.0 documentation
这篇关于基于laspy的点云数据存取及基于Open3D的点云数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




