本文主要是介绍信号处理--多分辨率单通道注意力脑电睡眠分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景
亮点
环境配置
数据准备和预处理
模型搭建和框架示意图
模型训练可视化
分类结果(SHHS数据集为例)
代码获取地址
背景
睡眠对人类来说是一个至关重要的过程,因为它影响着他们日常活动的各个方面。 研究表明,拥有良好睡眠质量的人会享有更好的健康和大脑功能。 另一方面,睡眠周期中断会导致一些睡眠障碍,例如失眠或睡眠不足。
亮点
- 多分辨率 CNN 模块,用于从不同频带中提取与低频和高频相对应的特征,并采用自适应特征重新校准来学习特征相互依赖性并增强提取特征的表示能力 。
- 时间上下文编码器,它部署了具有因果卷积的多头自注意力,以有效捕获提取特征中的时间依赖性。
- 类感知损失函数来有效地处理类不平衡,而无需引入额外的计算。
环境配置
- Pytorch 1.4
- Python 3.7
- mne 0.20.7
数据准备和预处理
- Sleep-EDF数据集

- SHHS数据集

Sleep-EDF数据预处理部分代码:
https://github.com/akaraspt/deepsleepnet
Copyright 2017 Akara Supratak and Hao Dong. All rights reserved.
'''import argparse
import glob
import math
import ntpath
import os
import shutilfrom datetime import datetimeimport numpy as np
import pandas as pdfrom mne.io import concatenate_raws, read_raw_edfimport dhedfreader# Label values
W = 0
N1 = 1
N2 = 2
N3 = 3
REM = 4
UNKNOWN = 5stage_dict = {"W": W,"N1": N1,"N2": N2,"N3": N3,"REM": REM,"UNKNOWN": UNKNOWN
}class_dict = {0: "W",1: "N1",2: "N2",3: "N3",4: "REM",5: "UNKNOWN"
}ann2label = {"Sleep stage W": 0,"Sleep stage 1": 1,"Sleep stage 2": 2,"Sleep stage 3": 3,"Sleep stage 4": 3,"Sleep stage R": 4,"Sleep stage ?": 5,"Movement time": 5
}EPOCH_SEC_SIZE = 30def main():parser = argparse.ArgumentParser()parser.add_argument("--data_dir", type=str, default="data_edf_20",help="File path to the PSG and annotation files.")parser.add_argument("--output_dir", type=str, default="data_edf_20_npz/fpzcz",help="Directory where to save numpy files outputs.")parser.add_argument("--select_ch", type=str, default="EEG Fpz-Cz",help="The selected channel")args = parser.parse_args()# Output dirif not os.path.exists(args.output_dir):os.makedirs(args.output_dir)else:shutil.rmtree(args.output_dir)os.makedirs(args.output_dir)# Select channelselect_ch = args.select_ch# Read raw and annotation EDF filespsg_fnames = glob.glob(os.path.join(args.data_dir, "*PSG.edf"))ann_fnames = glob.glob(os.path.join(args.data_dir, "*Hypnogram.edf"))psg_fnames.sort()ann_fnames.sort()psg_fnames = np.asarray(psg_fnames)ann_fnames = np.asarray(ann_fnames)SHHS数据预处理部分代码:
import os
import numpy as npimport argparse
import glob
import math
import ntpathimport shutil
import urllib
# import urllib2from datetime import datetime
import warnings
warnings.filterwarnings("ignore")import pandas as pd
from mne.io import concatenate_raws, read_raw_edf
import dhedfreader
import xml.etree.ElementTree as ET###############################
EPOCH_SEC_SIZE = 30def main():parser = argparse.ArgumentParser()parser.add_argument("--data_dir", type=str, default="/home/abc/shhs/polysomnography/edfs/shhs1",help="File path to the PSG files.")parser.add_argument("--ann_dir", type=str, default="/home/abc/shhs/polysomnography/annotations-events-profusion/shhs1",help="File path to the annotation files.")parser.add_argument("--output_dir", type=str, default="/home/abc/output_npz/shhs",help="Directory where to save numpy files outputs.")parser.add_argument("--select_ch", type=str, default="EEG C4-A1",help="The selected channel")args = parser.parse_args()if not os.path.exists(args.output_dir):os.mkdir(args.output_dir)ids = pd.read_csv("selected_shhs1_files.txt", header=None, names='a')ids = ids['a'].values.tolist()edf_fnames = [os.path.join(args.data_dir, i + ".edf") for i in ids]ann_fnames = [os.path.join(args.ann_dir, i + "-profusion.xml") for i in ids]edf_fnames.sort()ann_fnames.sort()edf_fnames = np.asarray(edf_fnames)ann_fnames = np.asarray(ann_fnames)数据加载代码:
import torch
from torch.utils.data import Dataset
import os
import numpy as npclass LoadDataset_from_numpy(Dataset):# Initialize your data, download, etc.def __init__(self, np_dataset):super(LoadDataset_from_numpy, self).__init__()# load filesX_train = np.load(np_dataset[0])["x"]y_train = np.load(np_dataset[0])["y"]for np_file in np_dataset[1:]:X_train = np.vstack((X_train, np.load(np_file)["x"]))y_train = np.append(y_train, np.load(np_file)["y"])self.len = X_train.shape[0]self.x_data = torch.from_numpy(X_train)self.y_data = torch.from_numpy(y_train).long()# Correcting the shape of input to be (Batch_size, #channels, seq_len) where #channels=1if len(self.x_data.shape) == 3:if self.x_data.shape[1] != 1:self.x_data = self.x_data.permute(0, 2, 1)else:self.x_data = self.x_data.unsqueeze(1)def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.len模型搭建和框架示意图

多分辨率CNN代码:
class MRCNN(nn.Module):def __init__(self, afr_reduced_cnn_size):super(MRCNN, self).__init__()drate = 0.5self.GELU = GELU() # for older versions of PyTorch. For new versions use nn.GELU() instead.self.features1 = nn.Sequential(nn.Conv1d(1, 64, kernel_size=50, stride=6, bias=False, padding=24),nn.BatchNorm1d(64),self.GELU,nn.MaxPool1d(kernel_size=8, stride=2, padding=4),nn.Dropout(drate),nn.Conv1d(64, 128, kernel_size=8, stride=1, bias=False, padding=4),nn.BatchNorm1d(128),self.GELU,nn.Conv1d(128, 128, kernel_size=8, stride=1, bias=False, padding=4),nn.BatchNorm1d(128),self.GELU,nn.MaxPool1d(kernel_size=4, stride=4, padding=2))self.features2 = nn.Sequential(nn.Conv1d(1, 64, kernel_size=400, stride=50, bias=False, padding=200),nn.BatchNorm1d(64),self.GELU,nn.MaxPool1d(kernel_size=4, stride=2, padding=2),nn.Dropout(drate),nn.Conv1d(64, 128, kernel_size=7, stride=1, bias=False, padding=3),nn.BatchNorm1d(128),self.GELU,nn.Conv1d(128, 128, kernel_size=7, stride=1, bias=False, padding=3),nn.BatchNorm1d(128),self.GELU,nn.MaxPool1d(kernel_size=2, stride=2, padding=1))self.dropout = nn.Dropout(drate)self.inplanes = 128self.AFR = self._make_layer(SEBasicBlock, afr_reduced_cnn_size, 1)注意力机制代码:
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool1d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1)return x * y.expand_as(x)不均衡损失函数代码:
import torch
import torch.nn as nndef weighted_CrossEntropyLoss(output, target, classes_weights, device):cr = nn.CrossEntropyLoss(weight=torch.tensor(classes_weights).to(device))return cr(output, target)模型训练可视化

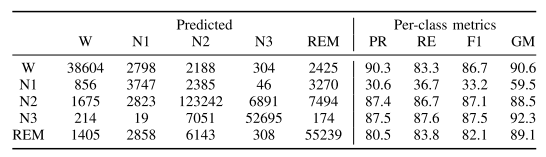
分类结果(SHHS数据集为例)
混沌矩阵+分类指标
代码获取地址
信号处理-多分辨率单通道注意力脑电睡眠分类 完整代码
这篇关于信号处理--多分辨率单通道注意力脑电睡眠分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






