本文主要是介绍DiffusionMat:Alpha Matting as sequential refinement learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.introduction

DiffusionMat的基本思想是未知区域的抠图可以逐步改进,并从每一次的迭代的反馈中受益,纠正和细化结果。
2.related works
Segdiff、BitDiffusion、DiffusionDet、
3.Approach
通过一种新颖的校正策略将trimap引导转化为精确的alpha matte。
3.1 Proceure
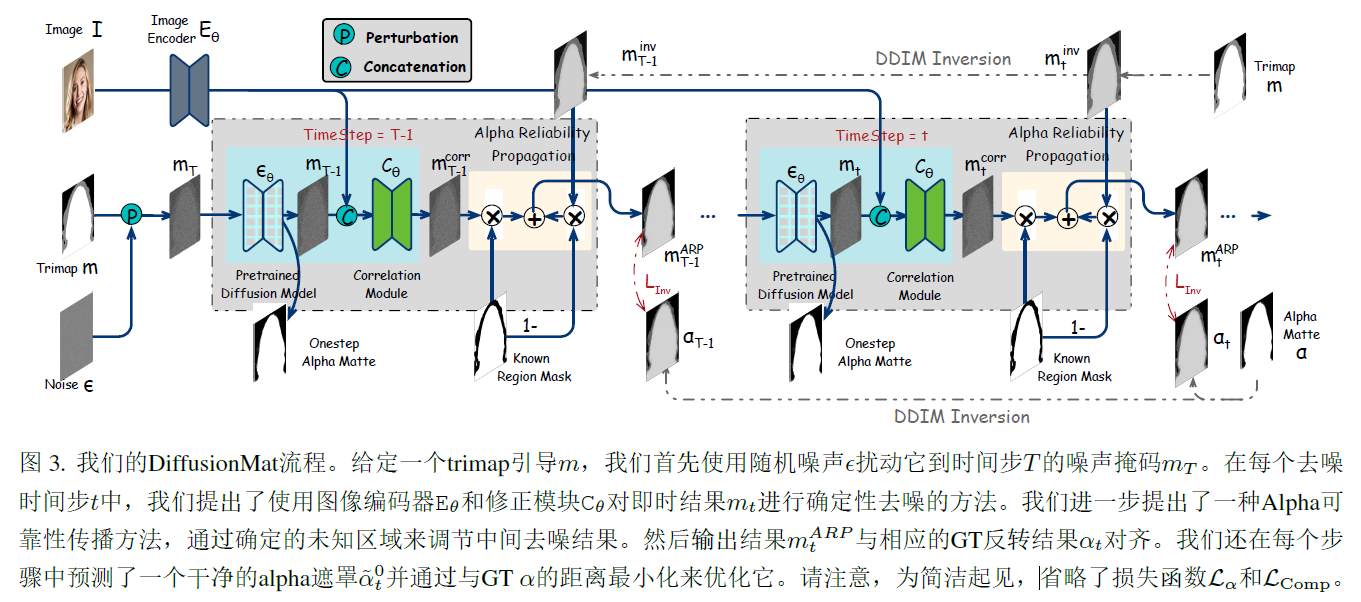
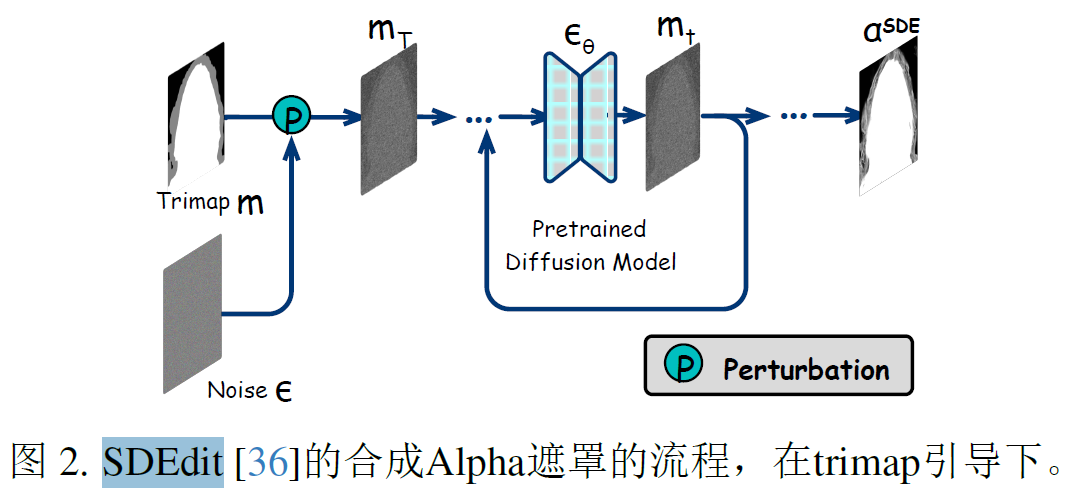
给定输入图像I以及trimap guidance m,我们的目标是推导出相应的alpha,与现有的一次性预测方法不同,引入了一种顺序细化学习策略,将有噪声的trimap转化为清晰的alpha。trimap到alpha的转换可以视为条件图像生成过程,SDEdit为此生成提供了一个简单的流程,通过随机微分方程的迭代去噪来合成给定导向下的输出图像。SDEdit从trimap guidance m开始最初使用随机噪声扰动创建时间步T处的有噪声掩码mT,随后这个破坏的trimap mT通过扩散模型的采样过程经历去噪的迭代,最终得到alphaSDE。
3.1.1 Deterministic Denoising
在SDEdit中,由于随机噪声带来的随机性,可以将噪声引导的trimap图像去噪为任意的alpha抠图,然而作为一项感知任务,图像抠图只有一个确定性的alpha抠图,为了获取精确的alpha,我们使用GT反转引导来纠正中间去噪结果,具体来说,给定GT alpha,通过DDIM反转将其映射到预训练的扩散模型上,并获得确定性的反转轨迹,可以纠正过程中用作监督信号。在每个去噪时间步t中,使用图像编码器Etheta和纠正模块Ctheta来纠正中间的去噪结果mt,首先使用图像编码器etheta对图像I进行编码,得到图像特征fI,随后,将fI和mt拼接起来,将这个组合输入传递给纠正模块Ctheta,生成纠正的去噪结果mtcorr,

3.1.2 Alpha reliability propagation
对所有像素学习修正是不必要的,因为trimap和alpha之间的差异只存在与未知区域,引入了Alpha Reliability Propagation(ARP)模块,通过已知区域调整中间的去噪结果。



3.1.3 loss function
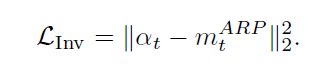
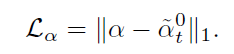
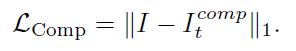

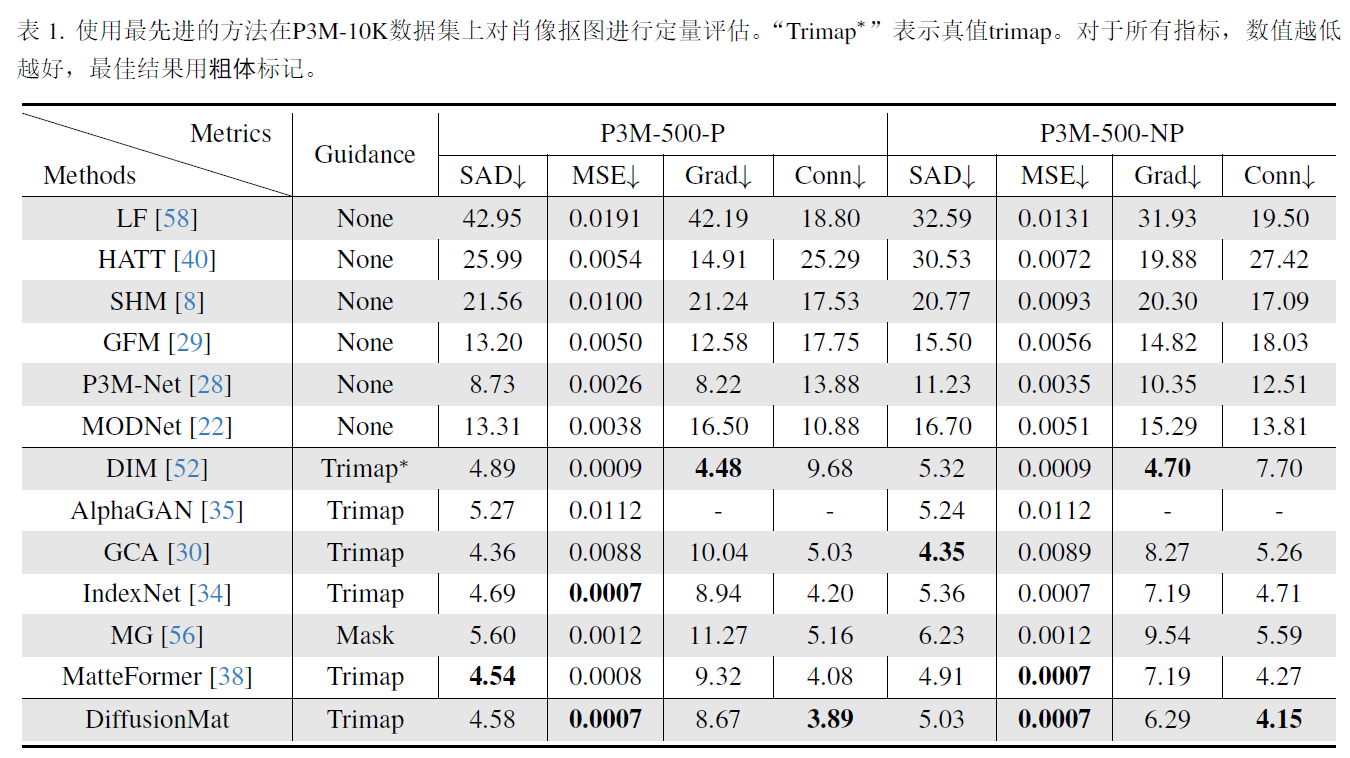
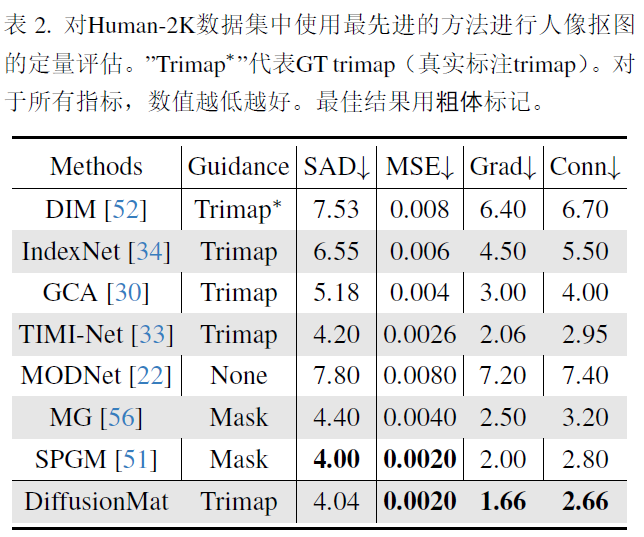
4.experiments
3090训练,unet架构作为扩散模型,去掉了unet中的att_block,swin-unet作为图像编码器,纠正网络结构和扩散模型相同,都是unet,输入图像512x512,
这篇关于DiffusionMat:Alpha Matting as sequential refinement learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![Android AnimationDrawable资源 set[translate,alpha,scale,rotate]](https://img-blog.csdn.net/20170610181346934?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc29uZ3l1bG9uZzg4ODg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)



