本文主要是介绍第五节Hadoop学习案例——MapReduce案例(WordCount),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:本文章内容主要围绕案例展开
目录
1 需求分析
1.1 需求
1.2 数据准备
1.3 原理
2 编码操作
2.1 创建项目
2.2 创建包和类
2.2.1 创建包
2.2.2 创建类
2.2 引入jar包
2.2.1 引入MR相关jar
2.2.2 引入打包插件
2.3 拷贝官方样例
2.4 修改样例代码
2.4.1 main方法程序阅读
2.4.2 WordCountMapper
2.4.3 WordCountReduce
2.4.4 替换实现类
2.5 程序打包
2.5.1 父项目pom修改
2.5.2 打包
2.6 程序测试
2.6.1 创建目录
2.6.2 上传程序
2.6.3 分布式文件系统上传测试数据
2.6.4 执行程序
2.6.5 查看结果
提示:以下是本篇文章正文内容,下面案例可供参考
1 需求分析
1.1 需求
- 统计文件中各个单词出现的个数
1.2 数据准备
- 数据准备:hello.txt
Once when l was six years old l saw a magnificent picture in a book called True Stories from Nature, about the primeval forest.
lt was a picture of a boa constrictor in the act of swallowing an animal.
Here is a copy of the drawing: In the book it said:"Boa constrictors swallow their prey whole, without chewing it.
After that they are not able to move, and they sleep through the six months that they need for digestion."
And after some work with a coloured pencil l succeeded in making my first drawing.
My Drawing Number One.
lt iooked like this: I showed my masterpiece to the grown-ups, and asked them whether the drawing frightened them.
But they answered:"Frighten?
why should anyone be frightened by a hat?
My drawing was not a picture of a hat.
lt was a picture of a boa constrictor digesting an elephant.
But since the grown-ups were not able to understand it, I made another drawing.
l drew the inside of the boa constrictor, so that the grown-ups could see it clearly.
They always need to have things explained.

1.3 原理
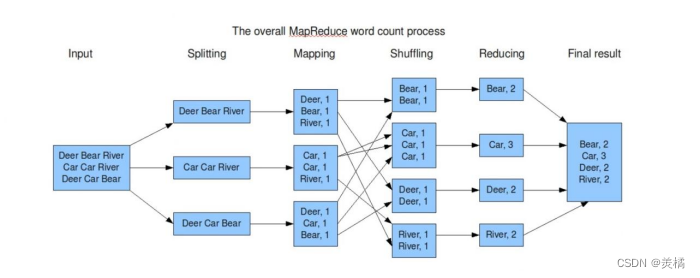
- 数据切分:把文本中的每一行进行切分。hadoop提供类实现。
- 每一行切分出来形成一个split,交给map进行处理,map会把一行数据中的单词以key-value的形式进行输出,发现一个单词就设置一个key。key是单词名称,value是1。
- map把最终的到数据经过整理以后交给不同的reduce进行处理,不同的reduce会收到不同的key-value数据。图中有些reduce收到以B开头的数据,有些reduce收到以C开头的数据。
- reduce会把收到的数据进行合并计算,输出最终的一个结果。
2 编码操作
2.1 创建项目
- 创建一个mr-demo的子模块
2.2 创建包和类
2.2.1 创建包
- 创建org.hadoop.mr包


2.2.2 创建类
- 创建WordCount类


2.2 引入jar包
2.2.1 引入MR相关jar
- 切记一定要联网,联网,联网
- 检查IDEA里面pom.xml文件是否引入正常
- 在pom.xml里面加入以下代码
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>2.9.2</version><scope>provided</scope></dependency></dependencies>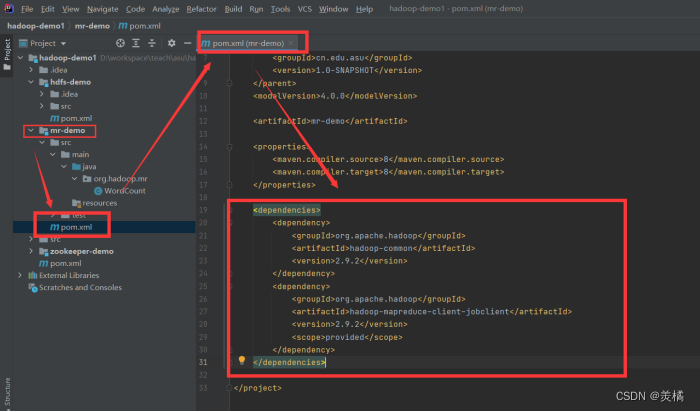
- 点击Reload一般情况下能看到正常引入相关JAR
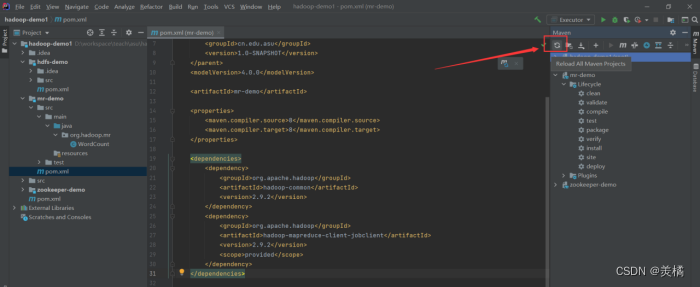
- 如果Reload不能正常引入可以尝试package
- 一定要联网下载JAR包
- 有时候能正常打包,但是代码仍然报错,重启IDEA再Reload就可以解决
- 如果报错则检查Maven的settings配置是否正确
- 如果告知具体的JAR下载不了,可以换一个网络再次尝试,也可以到仓库里面删除具体的jar包重新下载
- 可以换Maven仓库再尝试下载

新手在使用maven引入JAR包的时候非常容易出错,多尝试即可
2.2.2 引入打包插件
- 需要打包运行在集群环境
- 在pom.xml文件里面引入以下配置
build配置需放置在dependencies标签后面,但是要在project标签里面
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><configuration><archive><manifest><mainClass>org.hadoop.mr.demo.WordCount</mainClass></manifest></archive></configuration></plugin></plugins></build><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><configuration><archive><manifest><mainClass>org.hadoop.mr.FriendRecommend</mainClass></manifest></archive></configuration></plugin></plugins></build>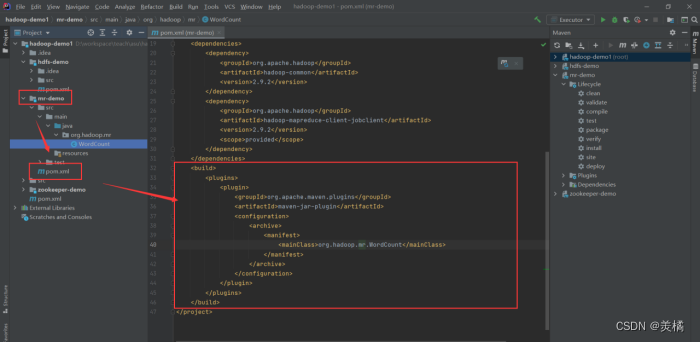
- mainClass配置需修改,并且鼠标放置在上面且按住ctrl键能连接到对应的类文件
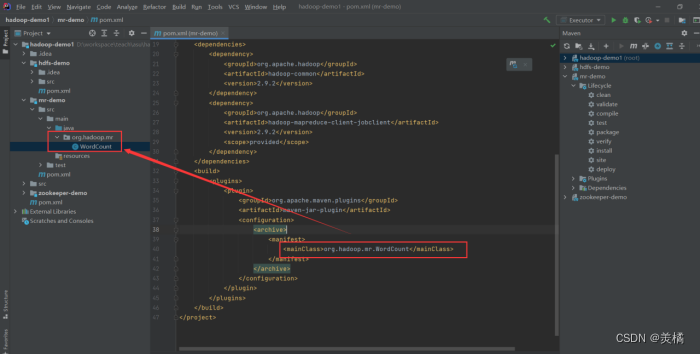
2.3 拷贝官方样例
- 官方提供了WordCount的样例,我们需要拷贝过来
- 把官方样例类里面的代码拷贝到我们创建的WordCount类中
- import代码中使用的jar包,import过程需要注意import的报名对应
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }2.4 修改样例代码
2.4.1 main方法程序阅读
- map的实现逻辑通过TokenizerMapper来实现
- reduce逻辑通过IntSumReducer来实现
- 当前TokenizerMapper和IntSumReducer是WordCount的内部类,我们为了方便理解,需要把这两个类移到外部
- TokenizerMapper和IntSumReducer类需要注释掉
public static void main(String[] args) throws Exception {//通过Configuration加装配置信息,配置信息在真正运行的虚拟机上Configuration conf = new Configuration();//解析main方法的入参,入参包含:计算时数据放在哪个目录;计算完成后结果写入哪个目录//参数不能小于2String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}//创建Job类型对象,通过Job来运行计算任务Job job = Job.getInstance(conf, "word count");//Job运行的执行类是WordCountjob.setJarByClass(WordCount.class);//计算任务的map逻辑由TokenizerMapper来完成job.setMapperClass(TokenizerMapper.class);//合并优化方法,暂时不用//job.setCombinerClass(IntSumReducer.class);//执行reduce逻辑方法是IntSumReducerjob.setReducerClass(IntSumReducer.class);//执行完成结果输出key和value分别对应的类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//处理输入数据,输入数据可以是多个目录,通过循环把输入路径添加到处理路径下for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//输出路径只有一个FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//运行Job等待完成,0成功System.exit(job.waitForCompletion(true) ? 0 : 1);}2.4.2 WordCountMapper
- 创建一个WordCountMapper类
/**
*
* WordCountMapper需要继承Hadoop提供的Mapper
* 1、Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* Mapper参数:
* KEYIN、VALUEIN-代表输入数据,KEYIN代表输入数据key类型,VALUEIN代表输入数据value类型
* KEYIN-切分的类由hadoop提供的类提供的,切分出来这个key是一个偏移量(long类型,字符位置),这个偏移量本程序用不到,使用Object类型替代
* VALUEIN-数据切分按照行切分,每行数据是一个字符串
* KEYOUT、VALUEOUT-代表输出数据,KEYOUT代表输出数据key类型,VALUEIN代表输出数据value类型
* KEYOUT-数据处理完成后,key是一个单词名称,使用Text类型
* VALUEOUT-数量
* 2、map(Object key, Text value, Context context)
* Context 上下文,代表hadoop中MapReduce中的计算环境
*
*
* 3、重写map方法
*
*
*/
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException{ //将获得的value进行切分(每行字符串),单词之间空格切分,获得一个数组 String[] words = value.toString().split(" "); //遍历数组,获得每个单词,每个单词标记为1进行输出 for (int i = 0; i < words.length; i++) { String word = words[i]; Text text = new Text(); text.set(word); context.write(text,new IntWritable(1)); } }
}2.4.3 WordCountReduce
- 创建一个WordCountReduce类
- WordCountReduce 一个单词调用一次
/**
*
* WordCountReduce需要继承Hadoop提供的Reducer
* 1、Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* Reducer参数:
* KEYIN、VALUEIN-代表输入数据,KEYIN代表输入数据key类型,VALUEIN代表输入数据value类型。此处reduce的输入是map的输出
* KEYIN- Text
* VALUEIN-IntWritable
* KEYOUT、VALUEOUT-代表输出数据,KEYOUT代表输出数据key类型,VALUEIN代表输出数据value类型
* KEYOUT-Reducer做合并,最终输出也是单词和数量,key是Text
* VALUEOUT-数量
* 2、reduce(Object key, Iterable values, Context context)
* Iterable 输入的value类型IntWritable,并且是迭代泛型参数,表示值是一个列表。收集到的数据是合并的数据。
* Context 上下文,代表hadoop中MapReduce中的计算环境
*
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//设置计数int sum = 0;//遍历values列表进行加总for (IntWritable intWritable : values) {sum = sum + intWritable.get();}//获得每个单词最终次数,进行输出context.write(key, new IntWritable(sum));}
}2.4.4 替换实现类
- WordCount类中TokenizerMapper和IntSumReducer确认注释掉
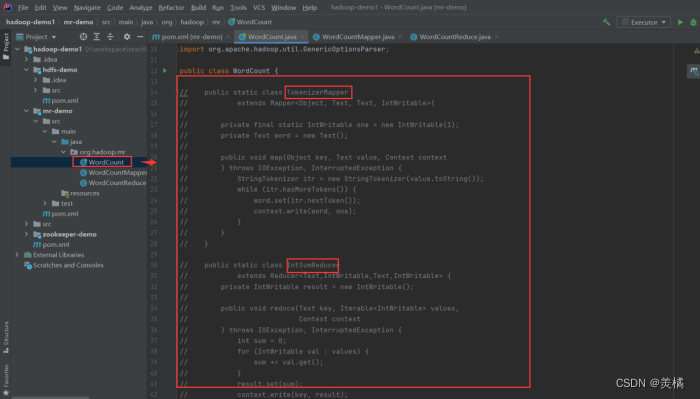
- WordCount类中main方法map和reduce实现类替换成自定义实现类
public static void main(String[] args) throws Exception {//通过Configuration加装配置信息,配置信息在真正运行的虚拟机上Configuration conf = new Configuration();//解析main方法的入参,入参包含:计算时数据放在哪个目录;计算完成后结果写入哪个目录//参数不能小于2String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}//创建Job类型对象,通过Job来运行计算任务Job job = Job.getInstance(conf, "word count");//Job运行的执行类是WordCountjob.setJarByClass(WordCount.class);//计算任务的map逻辑由WordCountMapper来完成job.setMapperClass(WordCountMapper.class);//合并优化方法,暂时不用//job.setCombinerClass(IntSumReducer.class);//执行reduce逻辑方法是WordCountReducejob.setReducerClass(WordCountReduce.class);//执行完成结果输出key和value分别对应的类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//处理输入数据,输入数据可以是多个目录,通过循环把输入路径添加到处理路径下for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//输出路径只有一个FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//运行Job等待完成,0成功System.exit(job.waitForCompletion(true) ? 0 : 1);}2.5 程序打包
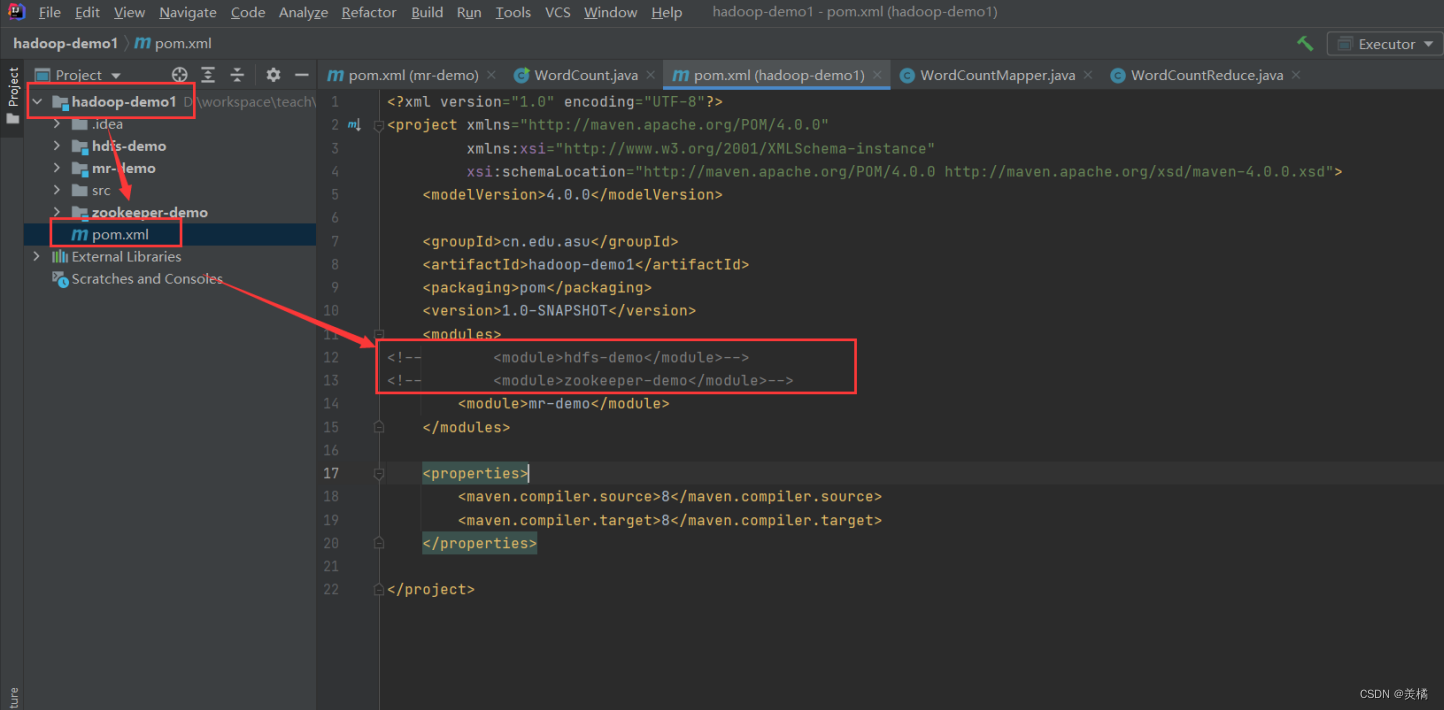
2.5.1 父项目pom修改
- 注释掉无关项目
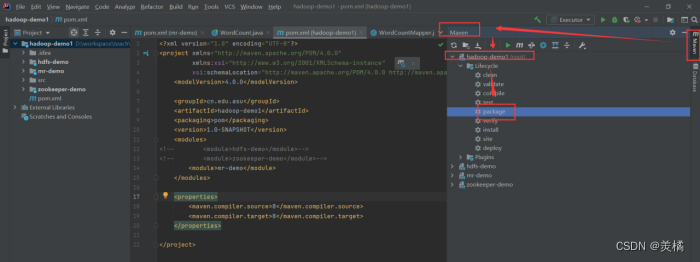
2.5.2 打包
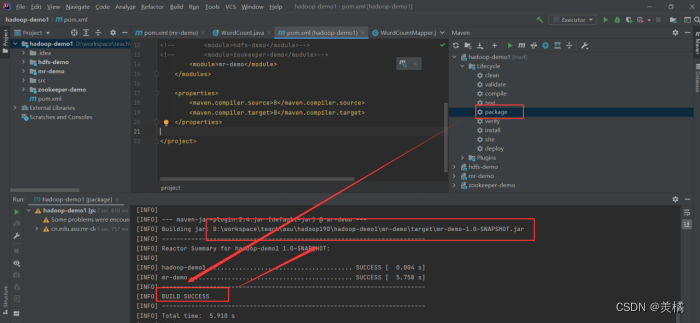
- 在父项目的maven视图下点击package进行打包
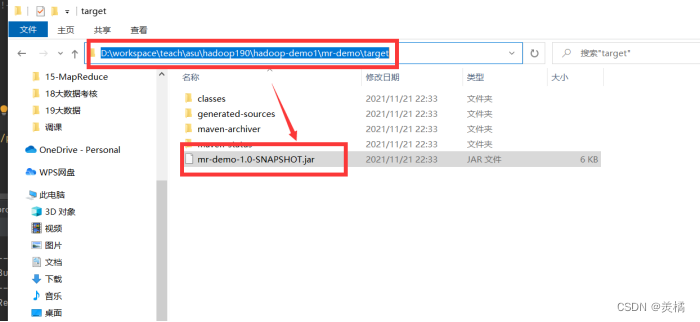
- 如果打包成功可以获得jar包
2.6 程序测试
2.6.1 创建目录
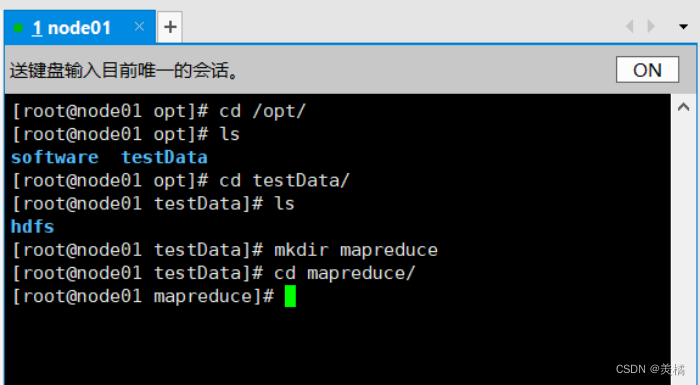
- 创建程序以及数据存放目录
cd /opt/
ls # 如果目录下没有testData目录的话自己手动创建一下即可
cd testData/
mkdir mapreduce
cd mapreduce/
2.6.2 上传程序
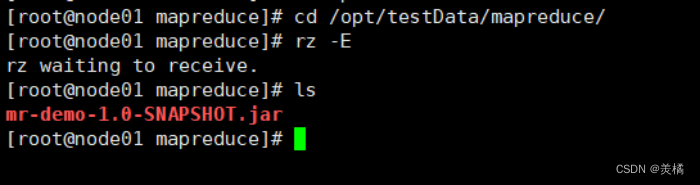
- 把程序先上传到虚拟机node01里面
cd /opt/testData/mapreduce/
rz
2.6.3 分布式文件系统上传测试数据
- 首先上传本地测试文件hello.txt到虚拟机
cd /opt/testData/mapreduce/
rz
![]()
- 确认Hadoop集群已经开启
- 此处必须开启yarn集群
start-dfs.sh
start-yarn.sh

- 分布式文件系统创建input目录并且input目录上传测试文件hello.txt
hdfs dfs -mkdir /input
hdfs dfs -put hello.txt /input
hdfs dfs -ls /input

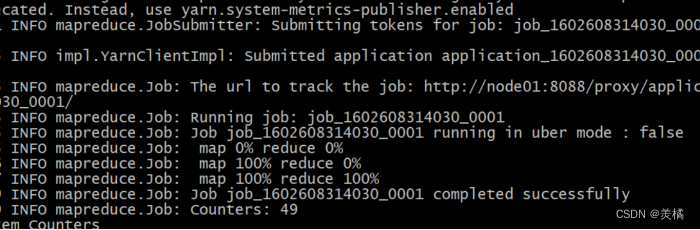
2.6.4 执行程序
hadoop jar mr-demo-0.0.1-SNAPSHOT.jar /input /output
2.6.5 查看结果
hdfs dfs -cat /output/part-r-00000

这篇关于第五节Hadoop学习案例——MapReduce案例(WordCount)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





