本文主要是介绍Carbondata编译适配Spark3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
当前carbondata版本2.3.1-rc1中项目源码适配的spark版本最高为3.1,我们需要进行spark3.3版本的编译适配。
原始编译
linux系统下载源码后,安装maven3.6.3,然后执行:
mvn -DskipTests -Pspark-3.1 clean package
会遇到一些网络问题,命令不变继续尝试编译即可:
例如:[INFO] Apache CarbonData :: Flink … FAILURE [09:57 min]
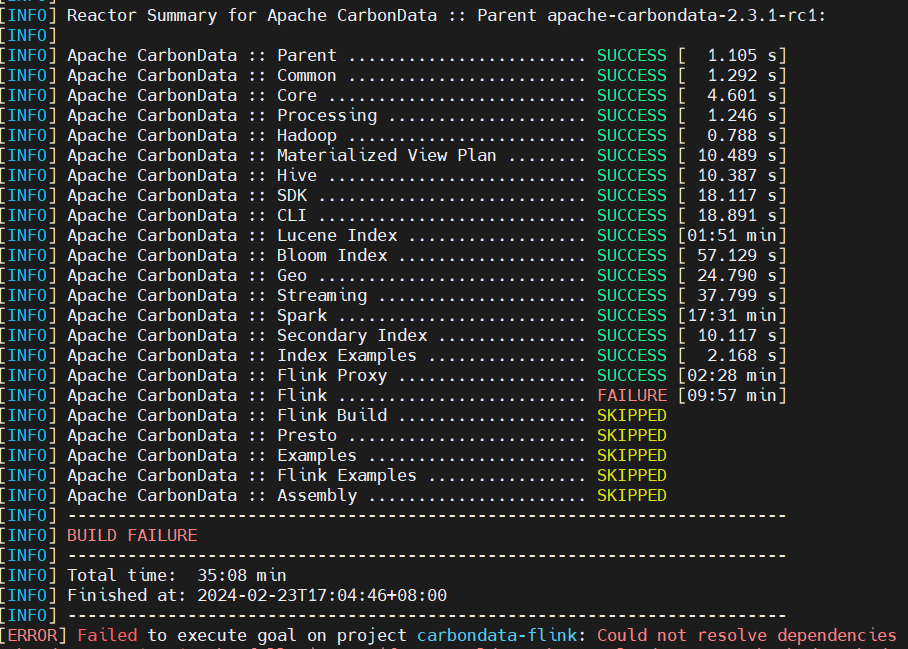
使用上述命令可编译成功。
适配Spark3.3
unzip carbondata-parent-apache-carbondata-2.3.1-rc1-source-release.zip
mv carbondata-parent-apache-carbondata-2.3.1-rc1 carbondata-spark33
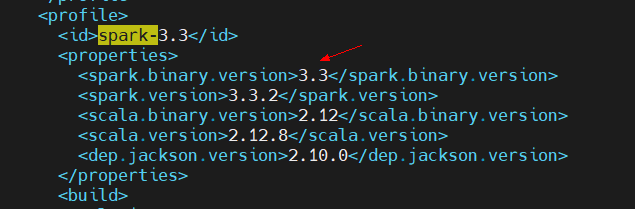
cd carbondata-spark33/ # 编辑一下根目录的pom文件,<profile>模块的spark-3.1复制一份修改为spark3.3
继续编译,果不其然报错了很多内容:
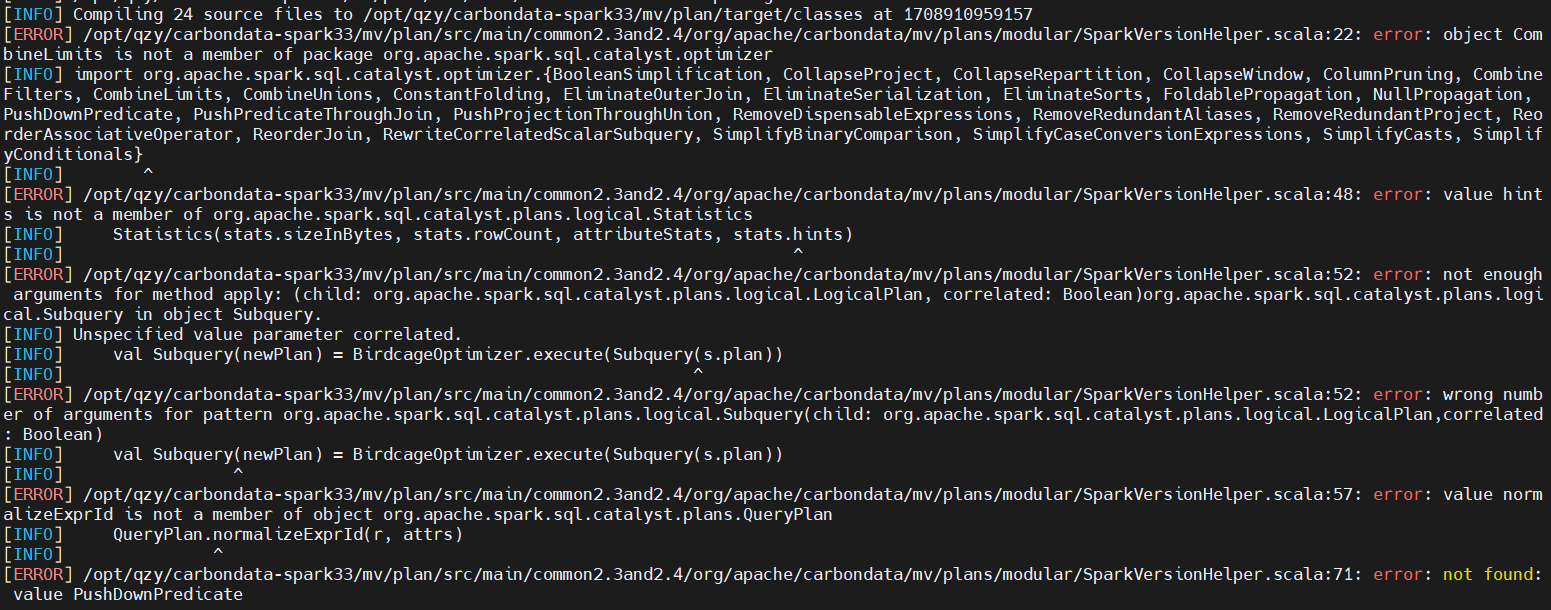
使用IDEA打开源码逐个分析怎么解决。
- error: object CombineLimits is not a member of package org.apache.spark.sql.catalyst.optimizer
- error: value hints is not a member of org.apache.spark.sql.catalyst.plans.logical.Statistics
- error: not enough arguments for method apply: (child: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
分析上下文发现这里应该是编译路径选择了spark2.x版本造成的,查看源码发现mv模块下缺少spark3.3目录及profile。
因此先进行一步简单修改pom试下:
vim ./mv/plan/pom.xml
# 复制spark3.1的相关内容改为3.3,复制比较麻烦也可以直接改
拷贝一份源码:
cd carbondata-spark33/mv/plan/src/main
cp spark3.1 spark3.3
报错:
[INFO] Compiling 24 source files to /opt/qzy/carbondata-spark33/mv/plan/target/classes at 1708917290440
[ERROR] /opt/qzy/carbondata-spark33/mv/plan/src/main/scala/org/apache/carbondata/mv/plans/modular/AggregatePushDown.scala:131: error: wrong number of arguments for pattern org.apache.spark.sql.catalyst.expressions.aggregate.Sum(child:
解决办法:修改AggregatePushDown.scala:131,给SUM加上第二个参数false;
org.apache.spark.sql.catalyst.expressions.Expression,useAnsiAdd: Boolean)
[ERROR] /opt/qzy/carbondata-spark33/mv/plan/src/main/scala/org/apache/carbondata/mv/plans/modular/AggregatePushDown.scala:193: error: wrong number of arguments for pattern org.apache.spark.sql.catalyst.expressions.aggregate.Average(child: org.apache.spark.sql.catalyst.expressions.Expression,useAnsiAdd: Boolean)
解决办法:修改AggregatePushDown.scala:193,给Average加上第二个参数false;
还有更多报错:
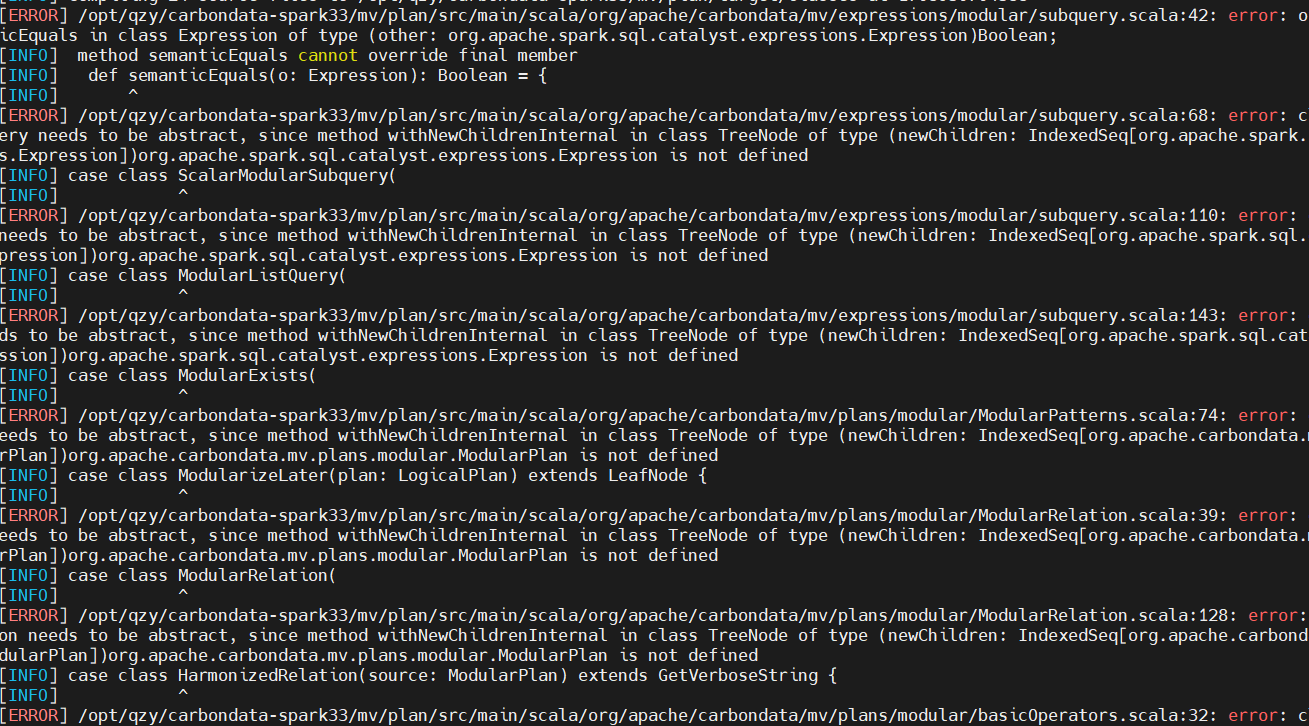
终止适配!太多地方要改,入不敷出。
快速测试
https://carbondata.apache.org/quick-start-guide.html
按照官网指导运行本地测试时报错如下:
以Spark local模式打开客户端:
spark-sql --conf spark.sql.extensions=org.apache.spark.sql.CarbonExtensions --jars /usr/hdp/3.0.1.0-187/spark3/carbondata/carbon.jar --master local
sql客户端中执行创建表:
CREATE TABLE IF NOT EXISTS test_carbon (id string,name string,city string,age Int)
STORED AS carbondata;
报错找不到类:
java.lang.ClassNotFoundException: org.apache.carbondata.hive.MapredCarbonInputFormat
jar包是确实存在的,实际需要在spark.sql.hive.metastore.jars所指示的路径添加这个jar才可以本地运行。
官网在后面YARN章节有提到。
If use Spark + Hive 1.1.X, it needs to add carbondata assembly jar and carbondata-hive jar into parameter ‘spark.sql.hive.metastore.jars’ in spark-default.conf file.
创建本地示例数据,后面会用到sample.csv:
cd carbondata
cat > sample.csv << EOF
id,name,city,age
1,david,shenzhen,31
2,eason,shenzhen,27
3,jarry,wuhan,35
EOF
然后可以正常创建表,执行加载数据和查询命令,注意加载数据路径要写file开头的符号。
LOAD DATA INPATH 'file:///usr/hdp/3.0.1.0-187/spark3/carbondata/sample.csv' INTO TABLE test_carbon;SELECT * FROM test_carbon;SELECT city, avg(age), sum(age)
FROM test_carbon
GROUP BY city;
local查询正常,待测yarn模式。
结论
- Spark3.3接口改变过多,与当前最新2.3.1-rc分支不兼容!
- Spark3.1 + Carbondata build 初步测试功能正常!
这篇关于Carbondata编译适配Spark3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







