spark3专题

spark3.x新特性
Adaptive Query Execution自适应查询(SparkSQL) 由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想 在Spark3.x版本提供Adaptive Query Execution自适应查询技术 通过在”运行时”对查询执行计划进行优化,允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据 统计进行动
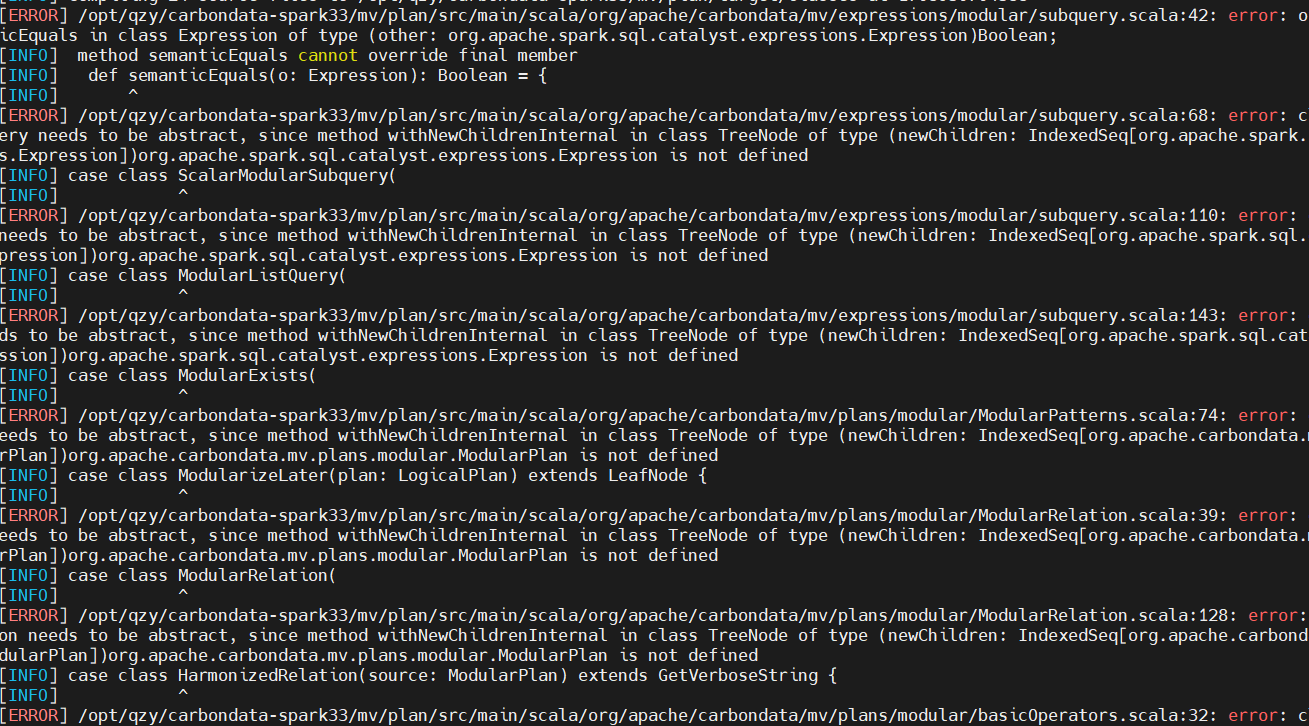
Carbondata编译适配Spark3
背景 当前carbondata版本2.3.1-rc1中项目源码适配的spark版本最高为3.1,我们需要进行spark3.3版本的编译适配。 原始编译 linux系统下载源码后,安装maven3.6.3,然后执行: mvn -DskipTests -Pspark-3.1 clean package 会遇到一些网络问题,命令不变继续尝试编译即可: 例如:[INFO] Apache Car
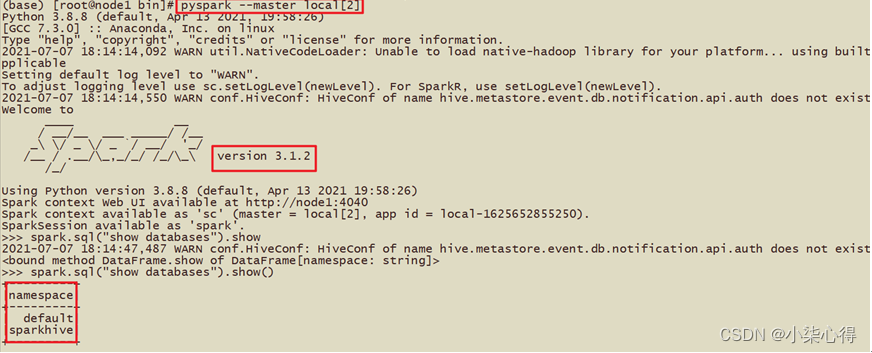
cento7 spark3 安装 anaconda安装
一、Spark部署安装 1. Spark Local 模式搭建文档 在本地使用单机多线程模拟Spark集群中的各个角色 1.1 安装包下载 目前Spark最新稳定版本:课程中使用目前Spark最新稳定版本:3.1.x系列 https://spark.apache.org/docs/3.1.2/index.html 注意1: Spark3.0+基于Scala2.12 http://spark
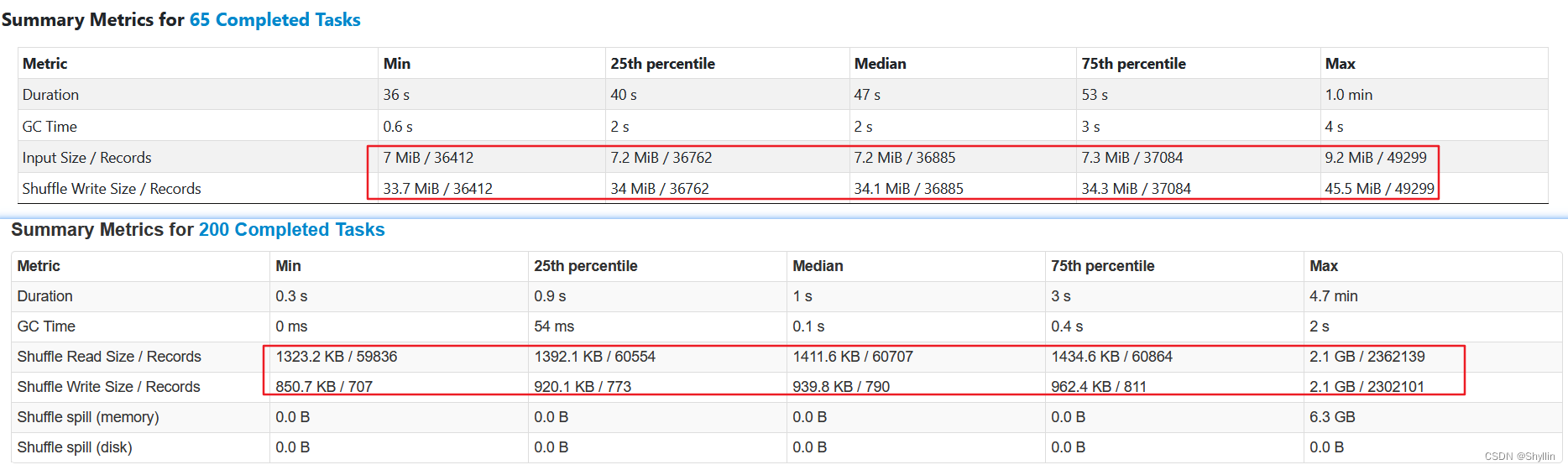
Spark3 新特性之AQE
文章目录 Spark3 AQE一、 背景二、 Spark 为什么需要AQE? (Why)三、 AQE 到底是什么?(What)四、AQE怎么用?(How)4.1 自动分区合并4.2 自动数据倾斜处理4.3 Join 策略调整 五、对比验证5.1 执行耗时5.2 自动分区合并5.3 自动数据倾斜处理 六、结论 Spark3 AQE 一、 背景 Spark 2.x 在遇到有数据

spark3.x 读取hudi报错
报错信息如下: Exception in thread "main" org.apache.hudi.exception.HoodieUpsertException: Failed to upsert for commit time 20231201203145254 at org.apache.hudi.table.action.commit.BaseWriteHelper.wr
Hive3 on Spark3配置
1、软件环境 1.1 大数据组件环境 大数据组件版本Hive3.1.2Sparkspark-3.0.0-bin-hadoop3.2 1.2 操作系统环境 OS版本MacOSMonterey 12.1Linux - CentOS7.6 2、大数据组件搭建 2.1 Hive环境搭建 1)Hive on Spark说明 Hive引擎包括:默认 mr、spark、Tez。 Hive on
Hive3 on Spark3配置
1、软件环境 1.1 大数据组件环境 大数据组件版本Hive3.1.2Sparkspark-3.0.0-bin-hadoop3.2 1.2 操作系统环境 OS版本MacOSMonterey 12.1Linux - CentOS7.6 2、大数据组件搭建 2.1 Hive环境搭建 1)Hive on Spark说明 Hive引擎包括:默认 mr、spark、Tez。 Hive on
Hive3 on Spark3配置
1、软件环境 1.1 大数据组件环境 大数据组件版本Hive3.1.2Sparkspark-3.0.0-bin-hadoop3.2 1.2 操作系统环境 OS版本MacOSMonterey 12.1Linux - CentOS7.6 2、大数据组件搭建 2.1 Hive环境搭建 1)Hive on Spark说明 Hive引擎包括:默认 mr、spark、Tez。 Hive on

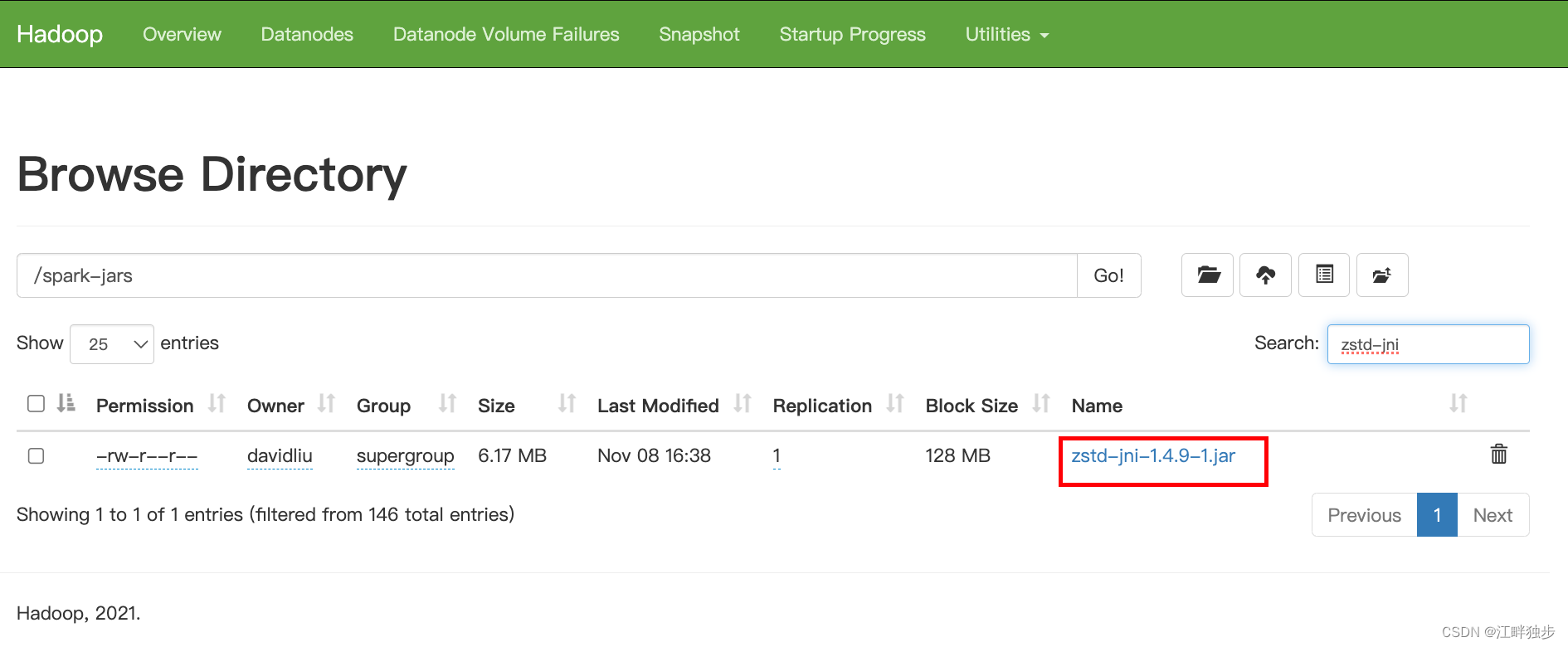
spark3使用hive zstd压缩格式总结
ZSTD(全称为Zstandard)是一种开源的无损数据压缩算法,其压缩性能和压缩比均优于当前Hadoop支持的其他压缩格式,本特性使得Hive支持ZSTD压缩格式的表。Hive支持基于ZSTD压缩的存储格式有常见的ORC,RCFile,TextFile,JsonFile,Parquet,Squence,CSV。 ZSTD压缩格式的建表方式如下: ORC存储格式建表时可指定TBLPROPERT
浪尖以案例聊聊spark3的动态分区裁剪
动态分区裁剪,其实就牵涉到谓词下推,希望在读本文之前,你已经掌握了什么叫做谓词下推执行。 SparkSql 中外连接查询中的谓词下推规则 动态分区裁剪比谓词下推更复杂点,因为他会整合维表的过滤条件,生成filterset,然后用于事实表的过滤,从而减少join。当然,假设数据源能直接下推执行就更好了,下推到数据源处,是需要有索引和预计算类似的内容。 1.静态数据集分区谓词下推执行 下面sql 是