本文主要是介绍Python 全栈系列231 以数据处理为核心的微服务思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
最初我是专注与做数据分析和建模的,通俗点说也就是pandas和sklearn。照理来说,分析和建模作为一种分工,本身是可以独立于架构的设计和使用的。其实也就是从20年之后,我才开始花比较多的时间研究这一块。
回想了一下原因:
- 1 交付价值。以模型为例,输入原始数据,经过一系列复杂的变换,给到处理结果。按照传统的部署方法,或者是交给其他团队,那么耗费的时间和资源是非常多。这就影响到了我们工作所能交付的价值。现在的大语言模型通常提供gradio或者streamlit这样前端的使用,其实也就是一种增强价值交付的手段。而且本身封装微服务是一种很简单的方法,文章后面会例子。
- 2 提高效率。仅从数据IO的角度,我觉得我没办法很好的在多种不同的数据库风格间切换。虽然python提供了大部分主流数据库的连接包,但是风格和语法还是有较大不同的,适应起来比较费时费力。对数据库本身的功能来说,其实本身的抽象功能是比较固定的:列出库表信息、索引的建立、数据的增删改查等。通过微服务提供统一的接口,屏蔽掉不同数据库的操作差异,可以极大的提升效率。
- 3 提升计算能力。工业化的数据处理必然要通过分布式来增强计算能力,微服务本身就可以很好的支持横向的计算拓展。
本篇介绍微服务的概念(优缺点)、微服务的部署基础(Docker)、Python微服务构造样例(Tornado)以及我的微服务使用现状。
内容
1 微服务概念
在我看来,微服务主要针对的是单体应用。
微服务(Microservice)这个概念是2012年出现的,作为加快Web和移动应用程序开发进程的一种方法,2014年开始受到各方的关注,而2015年,可以说是微服务的元年;(这段话引用的,关于时间差不多是这样)
最早的时候,通常说“一个jar包打天下”,将所有的功能封装在一起进行发布。这样容易产生三类问题:
- 1 耦合性高,某个地方出问题,很可能影响其他业务模块的使用
- 2 代码管理成本高,项目沉重,并会随着需求的增加越来越重
- 3 随着访问量的增多,这种架构的工程并发力不够
微服务出现后:系统的功能是松耦合的,一方面系统更加稳定了,另外一块是便于分工。
系统的稳定性来自于在项目的功能分解:将具体的功能切分为一个个的微服务,本身是分治的思想。另外,微服务本身也是独立部署的,某个微服务的bug可能不会导致系统的全面瘫痪。
便于分工则体现在,API接口的规范是一致的,每个人很清楚知道自己的IO格式。在微服务内部,你使用了什么语言或者是依赖是灵活的,只要在测试时你的并发能力足够,结果准确就行。
微服务的代价主要有两点:
- 1 管理变得复杂了。都使用微服务后,管理大量的微服务需要额外的开销。
- 2 数据的IO转换代价。以json规范为例,在不同的微服务间流转必然要进行序列化和反序列化,这是一笔不小的开销。
容器技术的出现降低了部署和管理难度,而硬件的不断进步使得数据IO的代价变得可以接受。这也是“人生苦短,我用Python”的精髓:用更多的机器时间来解放人的时间。
2 微服务的部署基础
Docker是一个开源的应用容器引擎,是Google公司推出的一个开源项目。它可以将应用和环境打包成一个容器,随后可以在任何地方运行。Docker容器镜像不仅可以在开发环境中打包应用,还可以在测试和生产部署阶段中使用。总之,Docker提供了一种快速单一的解决方案,解决了环境问题。
关于Docker也不多介绍了,可以简单理解为效率很高的虚拟机。从实际的使用上,Docker带来的好处是环境搭建和分布式部署非常方便。唯一可能需要注意的是,最好使用Linux系统服务器。
Docker有镜像仓库,一些云服务商也有镜像仓库(比如阿里云),当然也可以在自己的分布式环境下自建镜像仓库,而且一般都有很大的带宽,可以很快的在不同的主机上拉取。这些镜像仓库提供了许多半成品和成品,可以以类似git的方式进行增改和再提交,这就让定制自己的系统变的很简单。
在AI方面,通常安装CUDA环境是很烦的,有了Docker之后,宿主机只要安装好驱动,然后将显卡挂载到镜像启动,容器中就可以使用了,这个解决系统环境配置的一个大问题。
至于端口映射,让各个子分布系统之间互联互通的问题可以使用一些类似Nginx之类的工具完成。
在效率方面,官方的说法是一台机器可以启动多达上千个容器(肯定超过物理硬件的能力了)
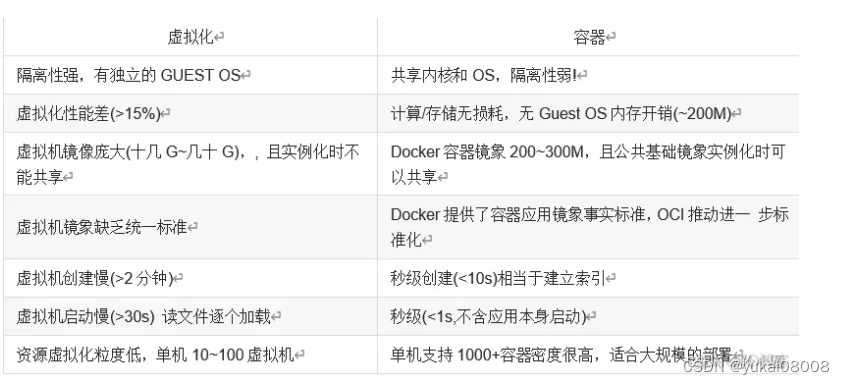
Docker的容器本身还有很多特性,比如限制CPU,内存等,这有助于进一步保证整体宿主机的稳定性。
3 Python微服务构造样例
我简单的把微服务的应用分为后端和前端,就python系而言Tornado适合后端,Flask适合前端。当然还有新出的FastAPI之类的,不过我觉得用不上了。


Tornado和Flask我都用,具体的参数比较就不说了,总而言之,Tornado用于纯后端非常方便(对象应用),Flask在前端应用上非常方便(蓝图模式以及各种钩子)。
可以搜索镜像,一般jupyter的镜像包装的比较全
docker pull jupyter/datascience-notebook
基于镜像创建容器,同时将宿主机的12345端口给到容器的8000端口,可以看到容器里已经有包了。
└─ $ docker run -it -p 12345:8000 jupyter/datascience-notebook bash
(base) jovyan@f7b727336b27:~$ ls
work
(base) jovyan@f7b727336b27:~$ pip3 install tornado
Requirement already satisfied: tornado in /opt/conda/lib/python3.11/site-packages (6.3.3)
以下粘贴两个py文件内容到容器里(使用vi 创建对应的文件再粘贴,或者使用docker cp 考入)
server_funcs.py
import json
from json import JSONEncoder
class MyEncoder(JSONEncoder):def default(self, obj):if isinstance(obj, np.integer):return int(obj)elif isinstance(obj, np.floating):return float(obj)elif isinstance(obj, np.ndarray):return obj.tolist()if isinstance(obj, datetime):return obj.__str__()if isinstance(obj, dd.timedelta):return obj.__str__()else:return super(MyEncoder, self).default(obj)# 【创建tornado所需问文件夹】
import os
# 如果路径不存在则创建
def create_folder_if_notexist(somepath):if not os.path.exists(somepath):os.makedirs(somepath)return Truem_static = os.path.join(os.getcwd(),'m_static')
m_template = os.path.join(os.getcwd(),'m_template')create_folder_if_notexist(m_static)
create_folder_if_notexist(m_template)settings = {
'static_path':m_static,
'template_path':m_template
}server.py
from server_funcs import *
import tornado.httpserver # http服务器
import tornado.ioloop # ?
import tornado.options # 指定服务端口和路径解析
import tornado.web # web模块
from tornado.options import define, options
import os.path # 获取和生成template文件路径app_list = []IndexHandler_path = r'/'
class IndexHandler(tornado.web.RequestHandler):def get(self):self.write('【GET】This is Website for Internal API System')self.write('Please Refer to API document')print('Get got a request test')# print(buffer_dict)def post(self):request_body = self.request.bodyprint('Trying Decode Json')some_dict = json.loads(request_body)print(some_dict)msg_dict = {}msg_dict['info'] = '【POST】This is Website for Internal API System'msg_dict['input_dict'] = some_dictself.write(json.dumps(msg_dict))print('Post got a request test')
IndexHandler_tuple = (IndexHandler_path,IndexHandler)
app_list.append(IndexHandler_tuple)if __name__ == '__main__':tornado.options.parse_command_line()apps = tornado.web.Application(app_list, **settings)http_server = tornado.httpserver.HTTPServer(apps)define('port', default=8000, help='run on the given port', type=int)http_server.listen(options.port)# 单核# 多核打开注释# 0 是全部核# http_server.start(num_processes=10) # tornado将按照cpu核数来fork进程# ---启动print('Server Started')tornado.ioloop.IOLoop.instance().start()
此时文件目录为
(base) jovyan@526ad528a653:~$ ls
server_funcs.py server.py work
# 启动服务
(base) jovyan@526ad528a653:~$ python3 server.py
Server Started
执行测试
import requests as req # get请求
res = req.get('http://127.0.0.1:12345/').text
In [4]: res
Out[4]: '【GET】This is Website for Internal API SystemPlease Refer to API document'
# post请求
some_dict = {'test':123}
res = req.post('http://127.0.0.1:12345/', json = some_dict).json()
In [7]: res
Out[7]:
{'info': '【POST】This is Website for Internal API System','input_dict': {'test': 123}}
将修改过的容器提交
docker commit 526ad528a653 YOUR_IMAGE:V
docker push YOUR_IMAGE:V
如果要进入长期服务,直接采取服务态方式执行即可
docker run -d \--restart=always \-p HOST_PORT:CONTAINER_PORT \YOUR_IMAGE:V \python3 server.py
4 微服务使用现状
我陆续构造了几十个微服务,主要分为:
- 1 数据库类
- 2 数据库代理类
- 3 功能类
- 4 辅助类
4.1 数据库类
Mysql、Mongo、Redis、ES、Milvus、Neo4j
其中Mongo是主库,构造了单机版和集群。
Redis作为内存库,提供KV缓存和简单消息队列(RedisStream)
ES作为全文搜索库。
Milvus是向量数据库。
Mysql很少用。
Neo4j 以前用的很多,以后肯定也会用的很多,最近比较少用。
4.2 数据库代理类
MysqlAgent、MongoAgent、CypherAgent、RedisAgent、RedisOrMongo、GlobalBuffer
顾名思义,就是为了简化数据库操作的。
4.3 功能类
特定功能类:例如主体识别,以及其他的为业务服务的微服务。
通用功能类:GlobalFunc
4.4 辅助类
辅助类也不少,Jupyter, JupyterLab, GitLab, DrawIO、定时类、Nginx、镜像仓库、文件传输、发邮件、发短信、任务看板、在线笔记、还有负责传递命令、监控的,不过有些不完善,目前也没在用。
4.5 应用
基于这些微服务再开发一些对象,就可以和平时的开发代码结合在一起,方便的使用了。
需要特别注意的是缓存的使用与数据的分块。
要对应大量的请求,一定要使用消息队列和内存数据库。像Mongo这样的,我作为主库,很适合进行大批量的吞吐(以万级为单位);但是Mongo如果应对大量的零散请求很容易崩溃,这时候就需要和Redis配合。简单起见我使用Redis实现了KV和消息队列。
除此之外,数据库本身的分片分区和分块比较重要。这样才能比较好的利用分布式的微服务处理:例如根据分片方法,异步并发向多个分片发起查询,速度可以快很多。
5 总结
之前侧重在数据的IO、服务的并发响应以及复杂功能的实现方面。基本上架构方面不再是一个约束,只有在算法和规范上需要进一步完善。
架构方面还需要改进的微服务有两块:
- 1 自动化运维。由于我的服务相对比较集中,所以可以自建一个微服务注册/监控/控制的服务。之前已经有过pilot了,所以应该没啥问题。
- 2 分布式任务调度。使用flask aps + celery + rabbit_mq ,可以再做一个分布式的任务调度。
目前数据的存储和规范基本ok,复杂功能方法基本也ok,并发响应(缓存和队列)也基本ok,在加上自动化运维和分布式任务调度,整个系统就完整了。
这篇关于Python 全栈系列231 以数据处理为核心的微服务思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




