本文主要是介绍深度学习_17_丢弃法调整过拟合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
除了权重衰退法调整过拟合,还有丢弃法调整模型得过拟合现象
过拟合:

丢弃法如果直接丢弃会导致新期望的不确定性,为了防止这个不确定被模型学到,所以要保证丢弃后的期望和丢弃前的期望一样(个人观点)
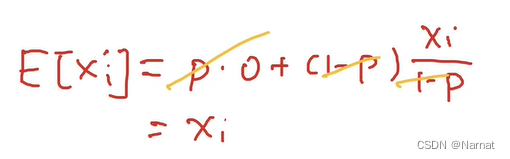
顾名思义,丢弃一些元素,单保持整体期望不变,让模型自己去权衡哪些元素是最重要得部分,从而着重选择那些元素
过拟合是因为模型学习过多无用杂质,用丢弃法,丢弃的可能是重要特征,或者杂质,通过丢弃的结果,让模型权衡哪些部分是最重要的,从而学习更稳健的特征
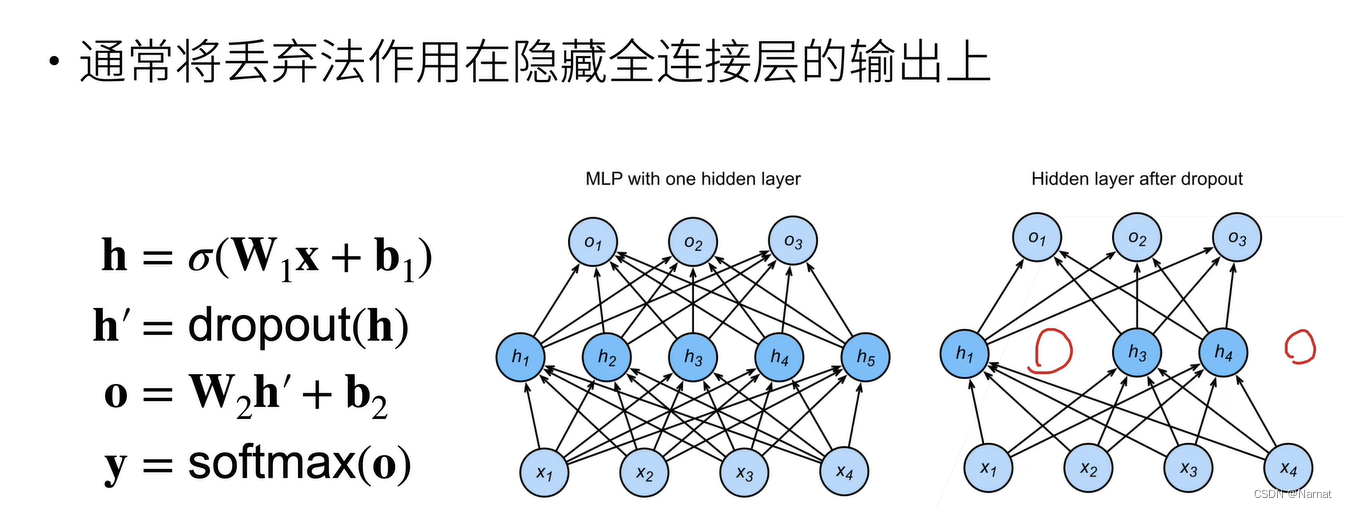
丢弃法在含隐藏层的模型中应用非常广泛
实例代码:
完整代码:
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as pltnum_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256def evaluate_loss(net, data_iter, loss):metric = d2l.Accumulator(2)net.eval() # 评估状态for X, y in data_iter:out = net(X)# y = y.float()l = loss(out, y)metric.add(l.sum(), l.numel())return metric[0] / metric[1]
def dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)dropout1, dropout2 = 0.7, 0.7 # 0.7 0.7class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1) # 形状(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs) # 总体输出为(num_inputs, num_outputs), num_output类别self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outif __name__ == '__main__':net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)num_epochs, lr, batch_size = 10, 0.5, 256loss = nn.CrossEntropyLoss()train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 取衣服数据集trainer = torch.optim.SGD(net.parameters(), lr=lr) # 优化器
# d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)train_losses = []test_losses = []test_acces = []for epoch in range(num_epochs):train_metrics, _ = d2l.train_epoch_ch3(net, train_iter, loss, trainer)train_losses.append(train_metrics)test_acc = d2l.evaluate_accuracy(net, test_iter)test_loss = evaluate_loss(net, test_iter, loss)test_acces.append(test_acc)test_losses.append(test_loss)print(f"Epoch {epoch + 1}/{num_epochs}:")print(f" 训练损失: {train_metrics:.4f}, 测试损失: {test_loss:.4f}, 测试精度: {test_acc:.4f}")plt.figure(figsize=(10, 6))plt.plot(train_losses, label='train', color='blue', linestyle='-', marker='.')plt.plot(test_losses, label='test', color='purple', linestyle='--', marker='.')plt.plot(test_acces, label='train_acc', color='red', linestyle='--', marker='.')plt.xlabel('epoch')plt.ylabel('loss & acc')plt.title('Test Loss and Train Accuracy over Epochs')plt.legend()plt.grid(True)plt.ylim(0, 1) # 设置y轴的范围从0到1plt.show()
实例是 深度学习_11_softmax_图片识别代码&原理解析 和 深度学习_14_单层|多层感知机及代码实现 两者代码结合,为了达到过拟合效果,所以上述代码是三层感知机,在原先两层感知机的条件下多加了一层,这样模型就会过拟合,再用丢弃法调整上述三层感知机
代码讲解:
丢弃函数
def dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)
求模型损失函数
def evaluate_loss(net, data_iter, loss):metric = d2l.Accumulator(2)for X, y in data_iter:out = net(X)# y = y.float()l = loss(out, y)metric.add(l.sum(), l.numel())return metric[0] / metric[1]
其他不再赘述
过拟合:
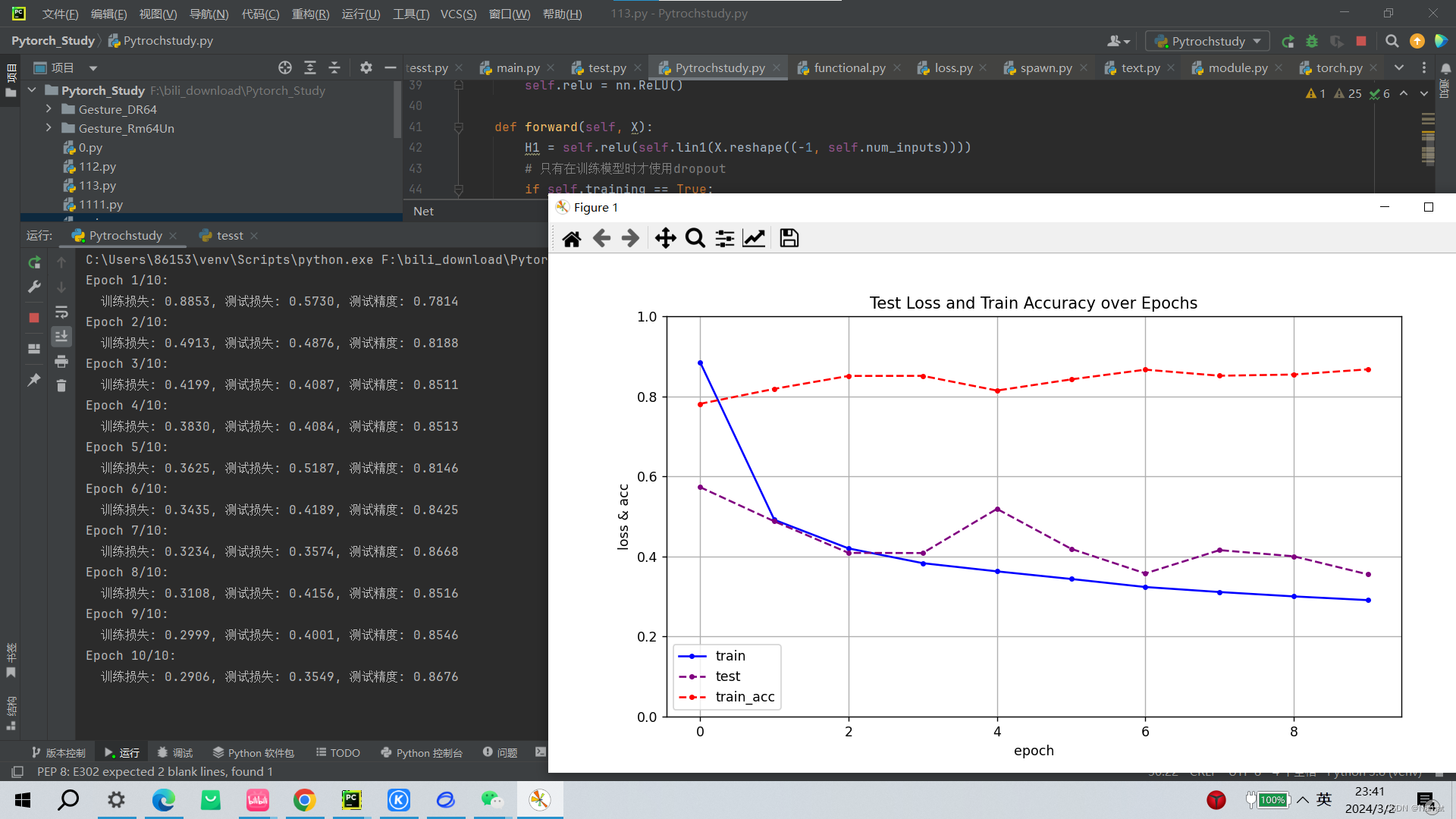
在正常情况下,模型测试损失波动比较大,存在过拟合现象
丢弃法调整过拟合:
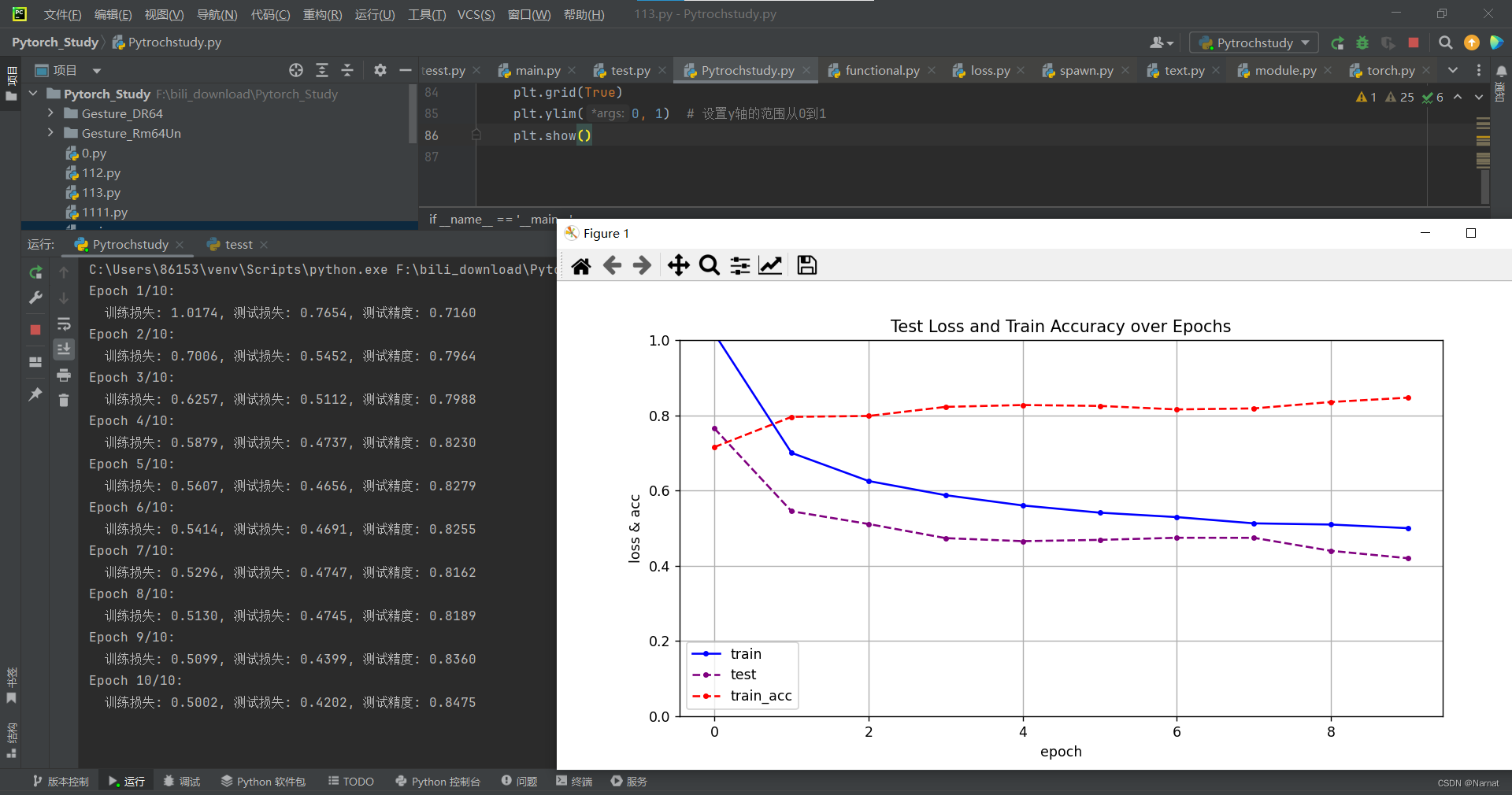
丢弃率都是0.7,测试损失比较稳定,过拟合被缓解
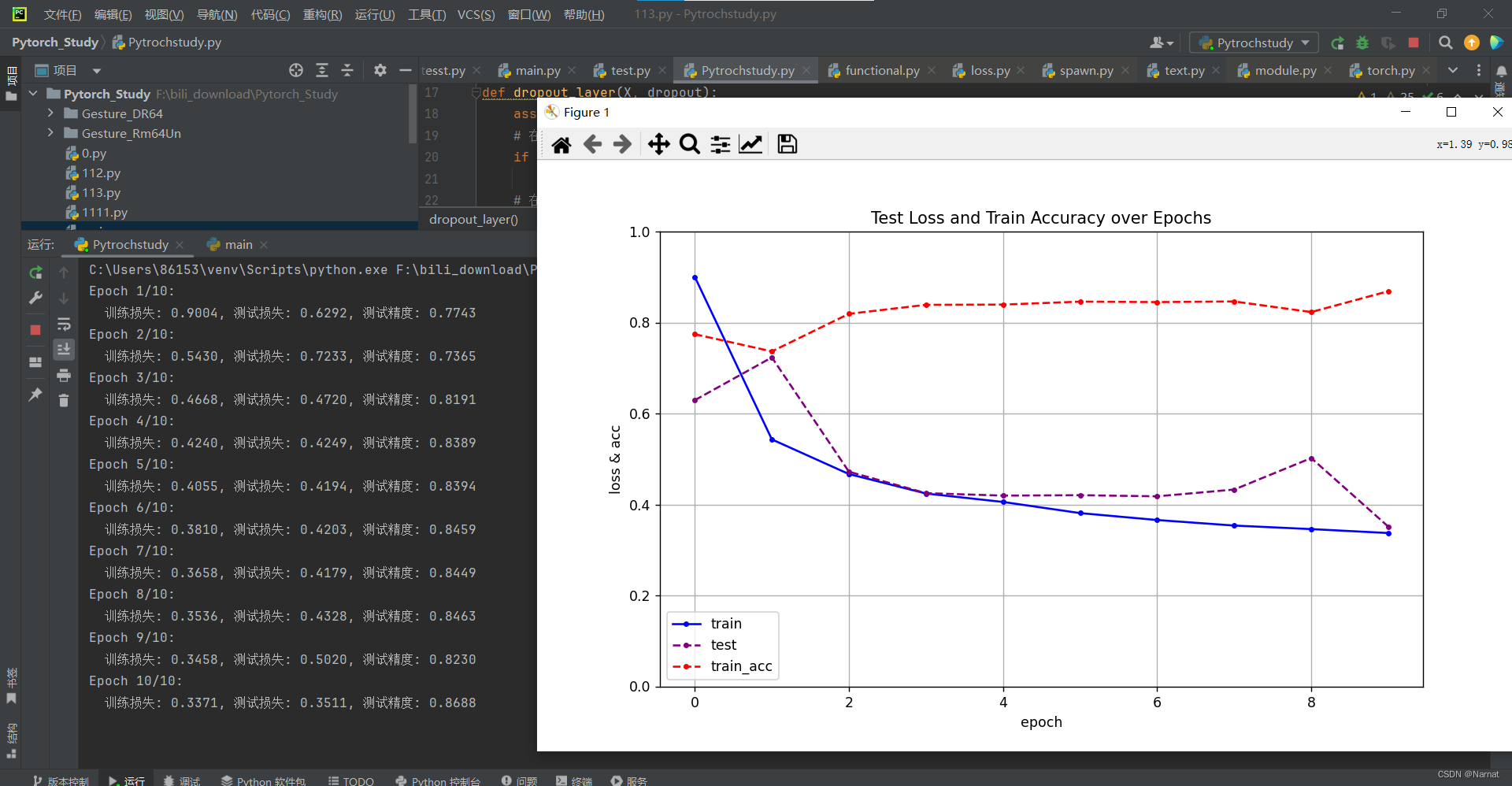
丢弃率0.2和0.7的效果
补充:
代码1:
import torch
import torch.nn as nn# 创建一个均方误差损失函数,使用 'sum' reduction
loss_fn = nn.MSELoss(reduction='none')# 生成一些示例数据
predictions = torch.randn(3, requires_grad=True)
targets = torch.randn(3)# 计算均方误差损失
loss = loss_fn(predictions, targets)# 通过对损失张量调用 .sum() 也可以得到相同的结果
loss_sum = loss_fn(predictions, targets).sum()# 打印两者的值
print(loss) # 输出总体均方误差损失值
print(loss_sum.item()) # 输出通过 .sum() 得到的总体均方误差损失值
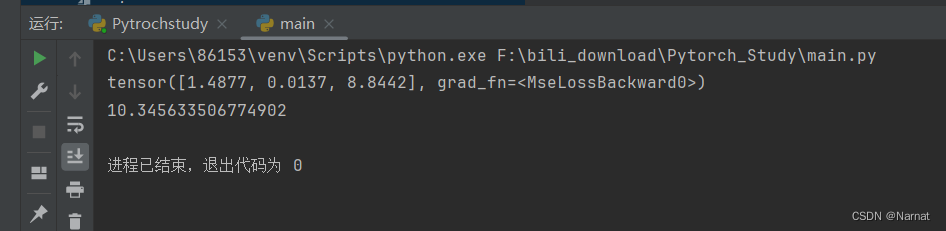
损失函数求得是每个样本的损失所以两者输出不一样
代码2:
import torch
import torch.nn as nn# 创建一个均方误差损失函数,使用 'sum' reduction
loss_fn = nn.MSELoss(reduction='sum')# 生成一些示例数据
predictions = torch.randn(3, requires_grad=True)
targets = torch.randn(3)# 计算均方误差损失
loss = loss_fn(predictions, targets)# 通过对损失张量调用 .sum() 也可以得到相同的结果
loss_sum = loss_fn(predictions, targets).sum()# 打印两者的值
print(loss.item()) # 输出总体均方误差损失值
print(loss_sum.item()) # 输出通过 .sum() 得到的总体均方误差损失值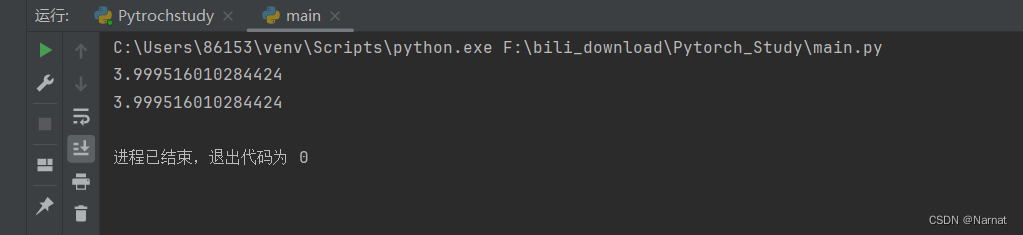
损失函数求得是整体样本的损失和再加.sum()无效,所以两者输出相同
这篇关于深度学习_17_丢弃法调整过拟合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







