本文主要是介绍【图算法】(2) 网络的基本静态几何特征(一),附networkx完整代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,今天和大家分享一下图算法中的静态几何特征,以及如何使用python中的networkx库实现度分布、效率、直径、距离、度-度相关性、介数、核度。内容较多,可通过右侧目录栏跳转。
1. 度分布
1.1 节点的度
以无向网络为例。在网络中,节点 的邻边数
称为该节点的度,是根据网络的邻接矩阵
求得的。计算公式如下:
对网络中所有节点的度求平均,可得到网络的平均度
无向无权图的邻接矩阵 的二次幂
的对角元素
就是节点
的邻边,即
。实际上,无向无权图的邻接矩阵
的第 i 行或第 i 列的元素之和也是度。从而无向无权网络的平均度就是
对角线元素之和除以节点数,即
,式中
表示矩阵
的迹,即对角线元素之和。
1.2 度分布
大多数实际网络中的节点的度是满足一定的概率分布的。定义 为网络中度为 k 的节点在整个网络中所占的比例。
规则网络:由于每个节点具有相同的度,所以其度分布集中在一个单一尖峰上,是一种Delta分布。
完全随机分布:度分布具有泊松分布的形式,每一条边的出现概率是相等的,大多数节点的度是基本相同的,并接近于网络平均度 ,若远离峰值,度分布则按指数形式急剧下降。把这类网络称为均匀网络。
无标度网络:具有幂指数形式的度分布,即 ,所谓无标度是指一个概率分布函数 F(x) 对于任意给定常数 a 存在常数 b 使得 F(ax) 满足 F(x)=bF(x)
幂律分布:是唯一满足无标度条件的概率分布函数。许多实际大规模无标度网络,其幂指数通常为 ,绝大多数节点的度相对很低,也存在少量度值相对很高的节点,把这类网络称为非均匀网络(异质网络)
指数度分布网络:满足 ,式中
一般为常数。

1.3 累计度分布
使用累计度分布函数描述度的分布情况,它与度分布的关系是: ,它表示度不小于k的节点的概率分布。
若度分布为幂律分布,即 ,则相应的累积度分布函数符合幂指数为
的幂分布:
若度分布为指数分布,即 ,则相应的累计度分布函数符合同指数的指数分布
1.4 代码实现
1.4.1 泊松分布--ER随机网络
度分布的峰值所对应的横坐标就是网络的平均度
创建ER网络: nx.erdos_renyi_graph( 节点数, 连边概率 )
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt# 创建一个ER随机网络为例
n = 10000 # 网络节点数
p = 0.001 # 连边的概率0.001
# 生成ER网络
ER = nx.erdos_renyi_graph(n, p)# 计算获取网络每个节点的度
d = dict(nx.degree(ER))
# 计算平均度=总度数/结点数
d_avg = sum(d.values()) / len(ER.nodes) # 10.026# 获取所有的度的值,及其对应的概率
# x记录有哪些度值
x = list(range(max(d.values())+1))
# 获取每个度值出现的次数
d_list = nx.degree_histogram(ER)
# y计算每个度值对应的出现概率=每个度值对应的结点个数/总节点数
y = np.array(d_list) / n# 绘制度分布
plt.plot(x, y, 'o-')
plt.xlabel('du_num')
plt.ylabel('du_prob')
plt.show()度分布曲线如下:

1.4.2 幂律分布--BA无标度网络
BA网络需要在双对数坐标轴下绘制,并且由于0值对应的无穷大没有意义,绘制时需要把0值剔除掉。
创建BA网络:nx.barabasi_albert_graph( 节点数, 平均度/2 )
import networkx as nx
import numpy as np
import matplotlib.pyplot as pltn = 10000 # 网络节点数
m = 3 # 平均度=6
# 生成网络
BA = nx.barabasi_albert_graph(n, m)# 获取网络每个节点的度
d = dict(nx.degree(BA))
# 计算平均度=节点度总数/节点总数
d_avg = sum(d.values()) / len(BA.nodes) # 5.9982# 获取所有出现的度值
x = list(range(max(d.values())+1))
# 获取每个度出现的次数
d_list = nx.degree_histogram(BA)
# 计算没个度值出现的概率=每个度值对应的结点个数/总结点数
y = np.array(d_list) / len(BA.nodes)#(1)在普通坐标轴下绘制度分布图
plt.plot(x, y, 'o-', color='b')
plt.xlabel('du_num')
plt.ylabel('du_prob')
plt.show()#(2)在双对数坐标轴下绘制,由于坐标中存在0出现无穷大的情况
plt.plot(x, y, 'o-', color='r')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('du_num')
plt.ylabel('du_prob')
plt.grid()
plt.show()#(3)在双对数坐标轴下绘制,并且把点0值坐标排除
new_x = []
new_y = []
# 删除0值
for i in range(len(x)):if y[i] != 0:new_x.append(x)new_y.append(y)# 绘图
plt.plot(new_x, new_y, 'o-', color='g')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('du_num')
plt.ylabel('du_prob')
plt.grid()
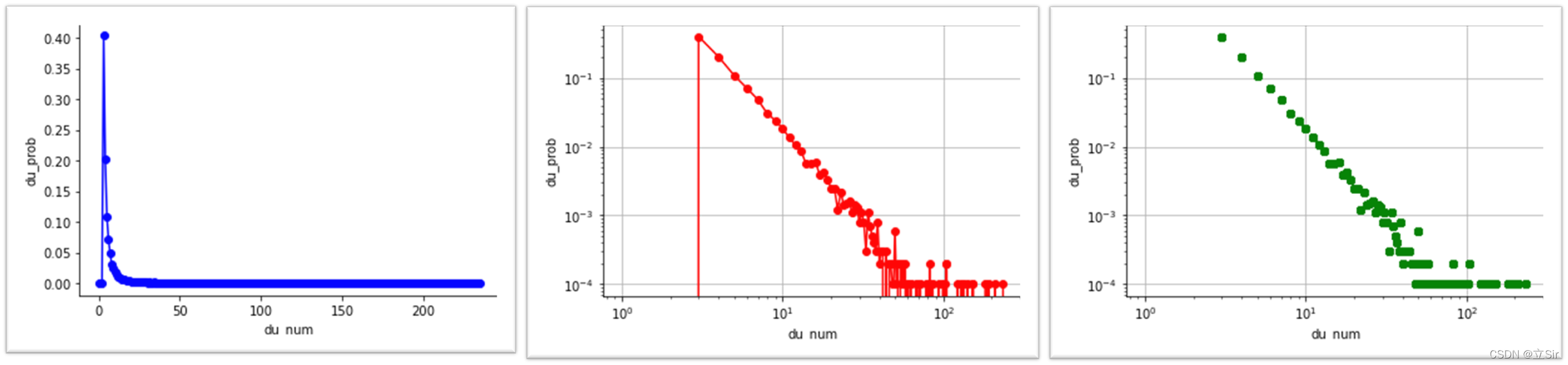
plt.show()第一张是在普通坐标系下,第二张是双对数坐标系下,第三张是双对数坐标系下删除0值
2. 网络的效率、直径和平均距离
2.1 方法介绍
网络中的两节点 和
之间经历边数最少的一条简单路径(经历的边各不相同),称为测地线。
测地线的边数 称为两节点
和
之间的距离(两节点之间的最短路径长度)
称为节点
和
之间的效率,记为
,通常效率用来度量节点之间的信息传递速度。当
和
之间没有路径连通时,
,而
。所以效率很适合度量非全连通网络。
网络的直径D定义为所有距离 中的最大值:
平均距离(特征路径长度)L定义为所有节点对之间距离的平均值,它描述了网络中节点间的平均分离程度,即网络有多小,计算公式为:
对于无向图来说, 且
,那么上面的公式可以简化为:
很多实际网络虽然节点数巨大,但平均距离却很小,这称为小世界效应。
2.2 代码实现
网络直径: nx.diameter( Graph )
两个节点之间的效率: nx.efficiency( Graph, 节点1, 节点2 )
两个节点之间的最短路径: nx.shortest_path_length( Graph, 节点1, 节点2 )
网络的局部效率: nx.local_efficiency( Graph )
网络的全局效率: nx.global_efficiency( Graph )
网络的平均距离: nx.average_shortest_path_length( Graph )
import networkx as nx#(1)直径
# 创建1000各节点,平均度为6的BA网络
G1 = nx.barabasi_albert_graph(1000, 3)
# 计算网络的直径=6
print( nx.diameter(G1) )#(2)效率
# 计算节点1和5之间的效率=0.5
print( nx.efficiency(G1,1,5) )#(3)最短路径
# 计算节点1和5之间最短路径长度=2
print( nx.shortest_path_length(G1,1,5) )# 效率==最路距离长度的倒数#(4)局部效率
print( nx.local_efficiency(G1) ) # 0.03958432238854824#(5)全局效率
print( nx.global_efficiency(G1) ) # 0.30804264264331954#(6)求整个网络的平均距离
# 1k个节点只有3.4的平均距离,距离很小
print( nx.average_shortest_path_length(G1) ) # 3.4374934934934935
4. 度-度相关性
4.1 基于最近邻平均度值的度-度相关性
度-度相关性描述了网络中度大的节点和度小的节点之间的关系。若度大的节点倾向于和度大的节点连接,则网络是度-度正相关的;反之,若度大的节点倾向于和度小的节点连接,则网络是度-度负相关的。
节点 的最近邻平均度值是把节点 Vi 的邻居的度值加起来求平均,公式如下:
式中, 表示节点
的度值,
为邻接矩阵元素。
所有度值为 k 的节点的最近邻平均度值的平均值 ,公式如下:
式中,N 表示节点总数,p(k) 为度分布函数。
如果 是随着 k 上升的增函数,则说明度值大的节点倾向于和度值大的节点连接,网络具有正相关特性,称之为同配网络;反之是单调递减函数,则网络具有负相关特性,称之为异配网络。
4.2 代码实现
import networkx as nx
# 参数是网络
def average_nearest_neighbor_degree(G):# 获取所有可能的度k = set([G.degree(i) for i in G.nodes()])# 从小到大排序所有的度sorted_k = sorted(k)# 求所有度值对应的最近邻平均度k_nn_k = []for ki in sorted_k:c = 0k_nn_i = 0for i in G.nodes():if G.degree(i) == ki:k_nn_i += sum([G.degree(j) for j in list(nx.all_neighbors(G,i))]) / kic += 1k_nn_k.append(k_nn_i/c)# 返回所有可能的度,以及度对应的最近邻平均度return sorted_k, k_nn_k5. 介数
5.1 概念介绍
要衡量一个节点的重要程度,其度值当然可以作为一个衡量指标,但又不尽然,例如在社会网络中,有的节点的度虽然很小,但它可能是两个社团的中间联络人,如果去掉该节点,那么就会导致两个社团的联系中断,因此该节点在网络中起到极其重要的作用。对于这样的节点,需要定义另一种衡量指标,这就引出了另一种重要的全局几何量--介数
介数分为节点介数和边介数两种,反映了节点或边在整个网络中的作用和影响力。
节点的介数 Bi 定义如下:
式中, 代表节点
和
之间的最短路径条数,
表示节点
和
之间的最短路径经过节点
的条数。
边的介数 Bij 定义如下:
式中, 代表节点
和
之间的最短路径条数,
表示节点
和
之间的最短路径经过边
的条数
5.2 代码实现
计算每个节点的介数: nx.betweenness_centrality( Graph )
计算每条连边的介数: nx.edge_betweenness_centrality( Graph )
import networkx as nx
# 首先创建一个BA无标度网络
BA = nx.barabasi_albert_graph(20, 2)#(1)计算每个节点的介数
bc = nx.betweenness_centrality(BA)
# 以字典保存,键是节点,值是介数
print(bc)
# 获取介数最大的节点标签
max_id = max(bc, key=bc.get)
print(max_id) # 3 #(2)计算每条边的介数
ebc = nx.edge_betweenness_centrality(BA)
# 以字典保存,键是边,值是介数
print(ebc)
# 获取介数最大的连边的标签
max_ebc = max(ebc, key=ebc.get)
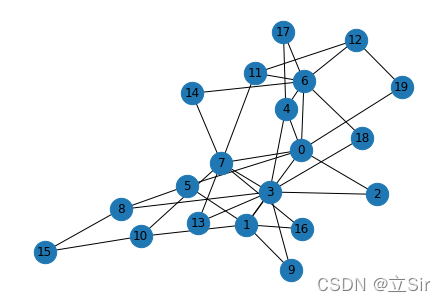
print(max_ebc) #(3,8)# 绘制网络
nx.draw(BA, node_size=500, with_labels=True)
绘制网络图

6. 核度
6.1 概念介绍
一个图的 k-核 是指反复去掉度值小于 k 的节点及其连线后,所剩余的子图,该子图的节点数就是该核的大小。
若一个节点属于 k-核,而不属于 (k+1)-核 ,则此节点的核度为 k
节点核度的最大值叫做网络的核度。
节点的核度可以说明节点在核中的深度,核度的最大值自然就对应着网络结构中最中心的位置。k-核 解析可用来描述度分布所不能描述的网络特征,揭示源于系统特殊结构和层次性质。
如下图所示,首先设定一个阈值ks=1,将网络中所有节点的度小于等于1的节点全部删除,直到网络中不存在度小于等于1的节点。有的节点一开始的度是大于1的,但是由于邻接的节点的度是1被删除了,从而导致这个节点的度小于等于1,也要被删除。

6.2 代码实现
计算每个节点的核度: nx.core_number( Graph )
import networkx as nx
# 首先创建一个club网络
kcg = nx.karate_club_graph()# 计算每个节点的核度
ks = nx.core_number(kcg)
# 以字典类型保存,键是节点,值是节点的核度
print(ks)# 获取核度最大的节点标签
max_id = max(ks, key=ks.get)
print(max_id) # 0# 绘制网络
nx.draw(BA, node_size=500, with_labels=True)
绘制网络图
这篇关于【图算法】(2) 网络的基本静态几何特征(一),附networkx完整代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






