本文主要是介绍数据迁移DTS | 云上MySQL 数据库迁移至达梦数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引入
云上 MySQL 数据库 —> 向达梦国产化数据库迁移
下载&安装
达梦客户端工具 DM->可参考之前国产化专栏达梦文章
创建模式
在客户端分别依次执行以下命令脚本(这里没有通过客户端管理工具去创建达梦数据库的模式,当然也可以通过图形化界面去创建模式)
CREATE TABLESPACE
YD_KNOW DATAFILE
'YD_KNOW.DBF' SIZE 128;CREATE USER YD_KNOW
IDENTIFIED BY
"YD_KNOW123456"
DEFAULT TABLESPACE
YD_KNOW;GRANT RESOURCE TO
YD_KNOW;
上述,以 YD_KNOW 为例。
可视界面化 数据迁移DTS
接着,打开 DM8 数据迁移 DTS 工具:
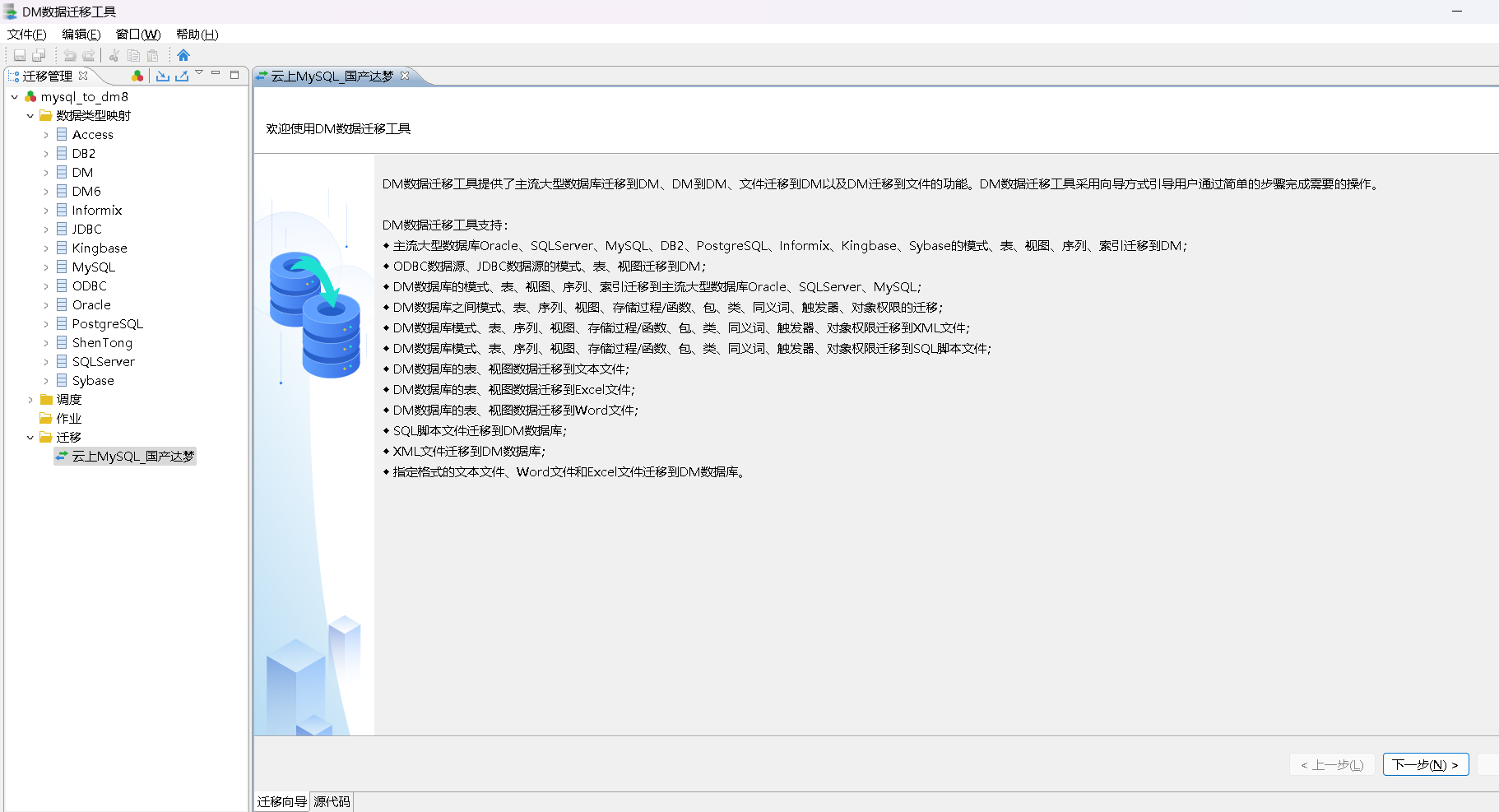
建立迁移作业
打开主页即点击“🏠”,新建工程,建立迁移作业-任务如下
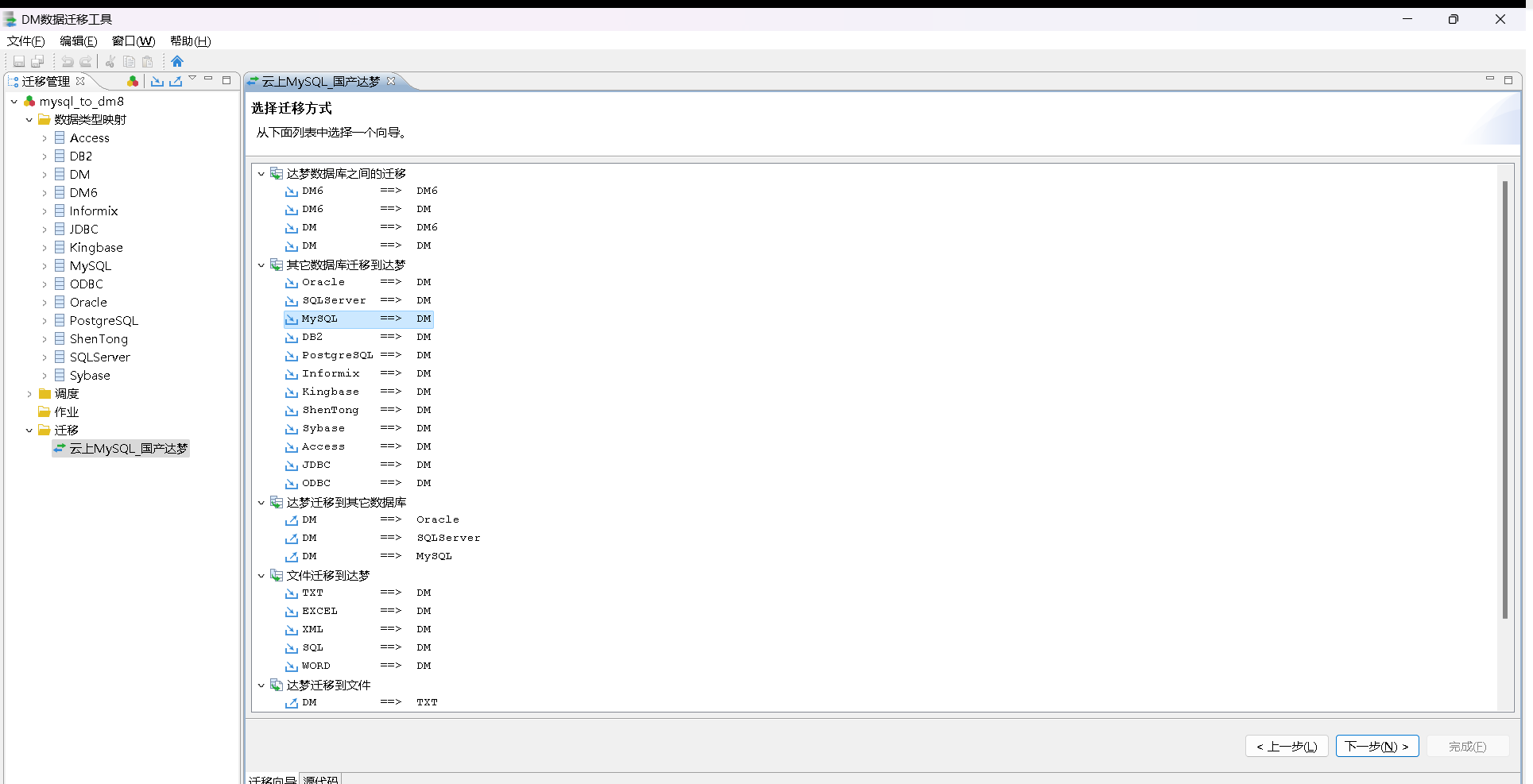
选择迁移方式
选择迁移方式:同构数据库 VS 异构数据库
这里选择 MySQL ===> DM
源数据库
输入源数据库信息:主机名+端口+用户名+密码+库名称
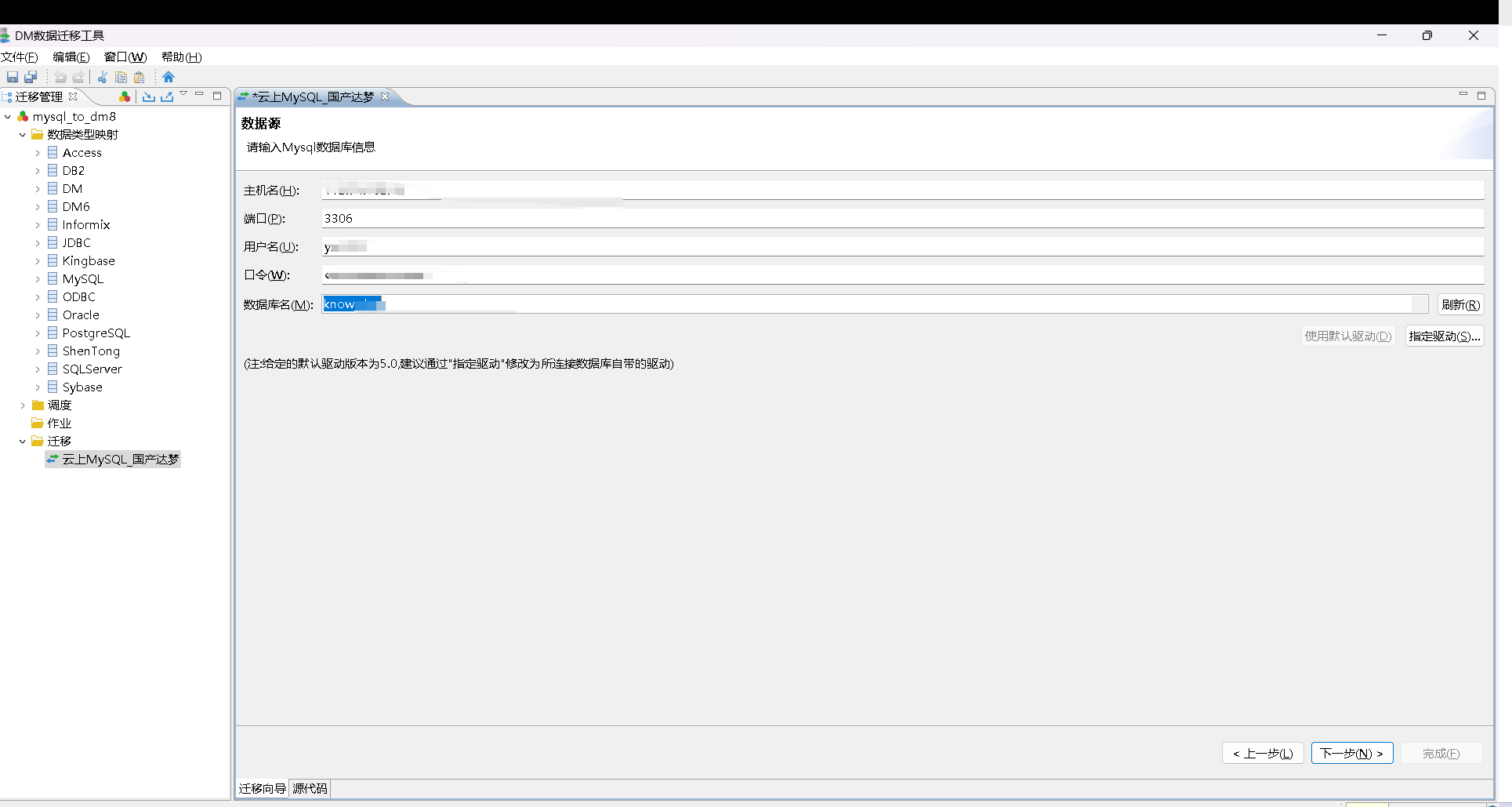
这里,使用默认版本可能会出现 jdbc 连接异常
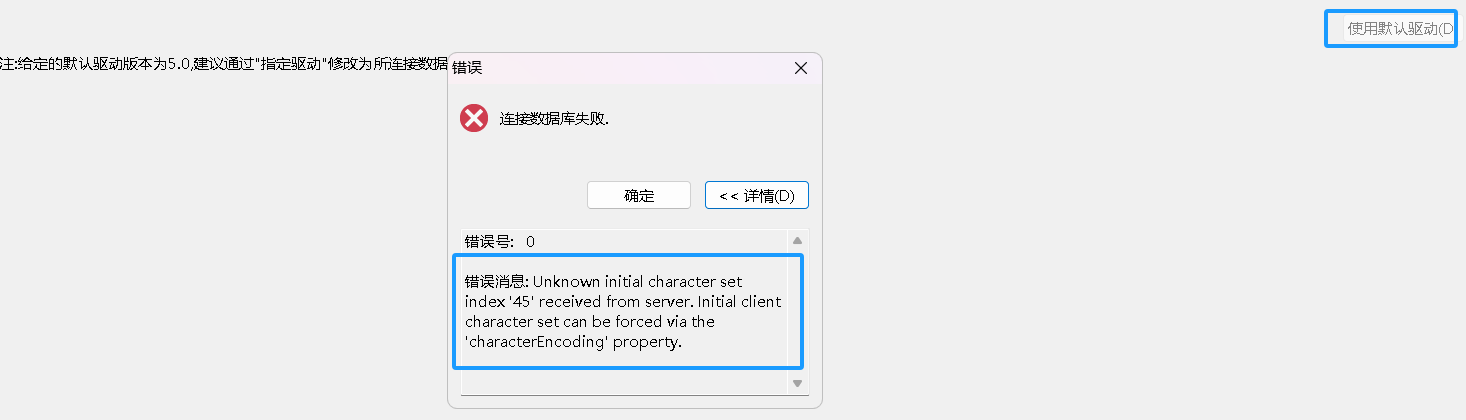
我们指定高驱动版本8即可

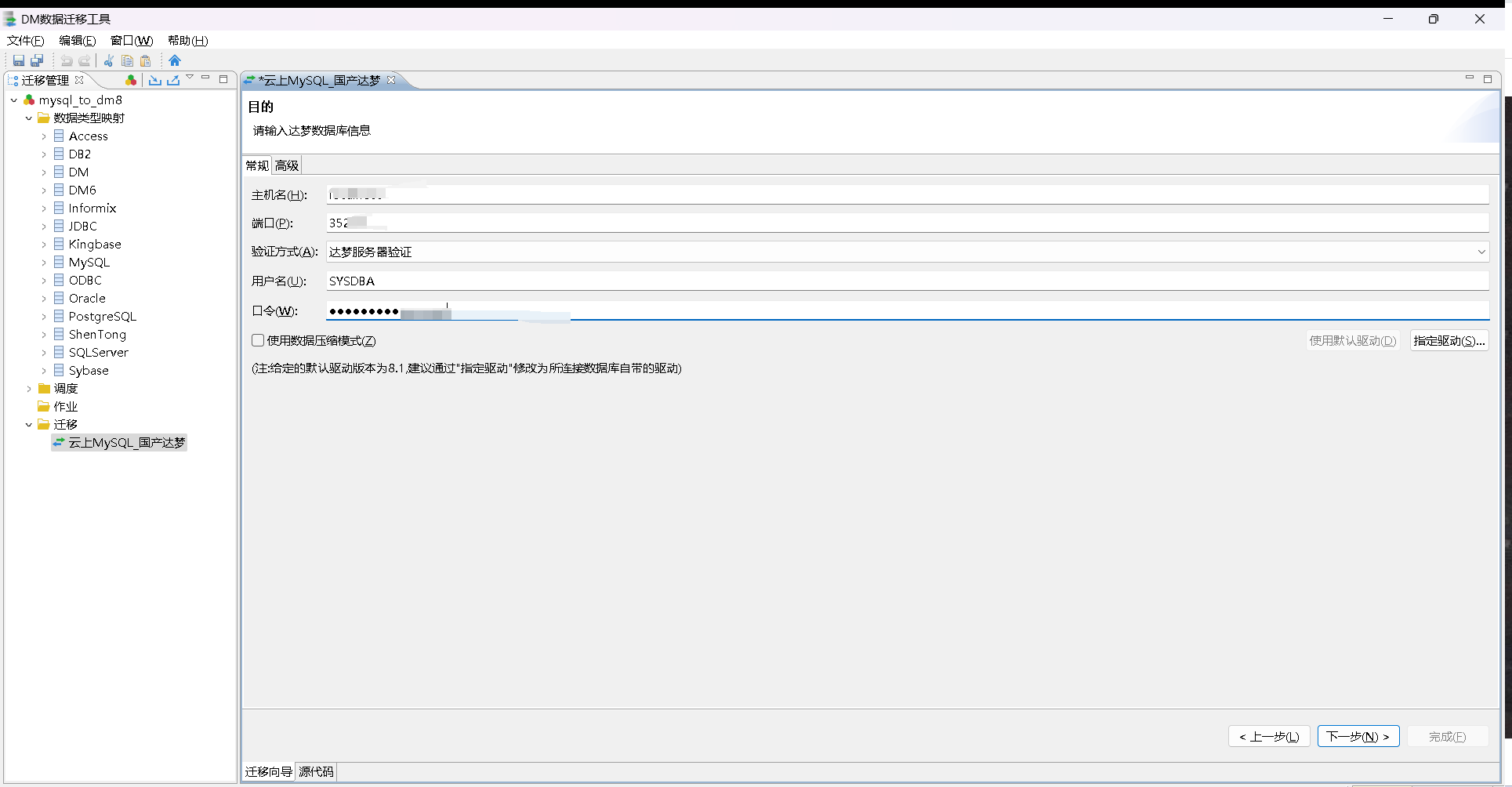
目标数据库
输入迁移目标数据库信息:主机名+端口+用户名+密码
指定对象复制或查询
指定迁移对象,这里可选择之前建立好的,当然,也可以通过工具去建立到新的模式下
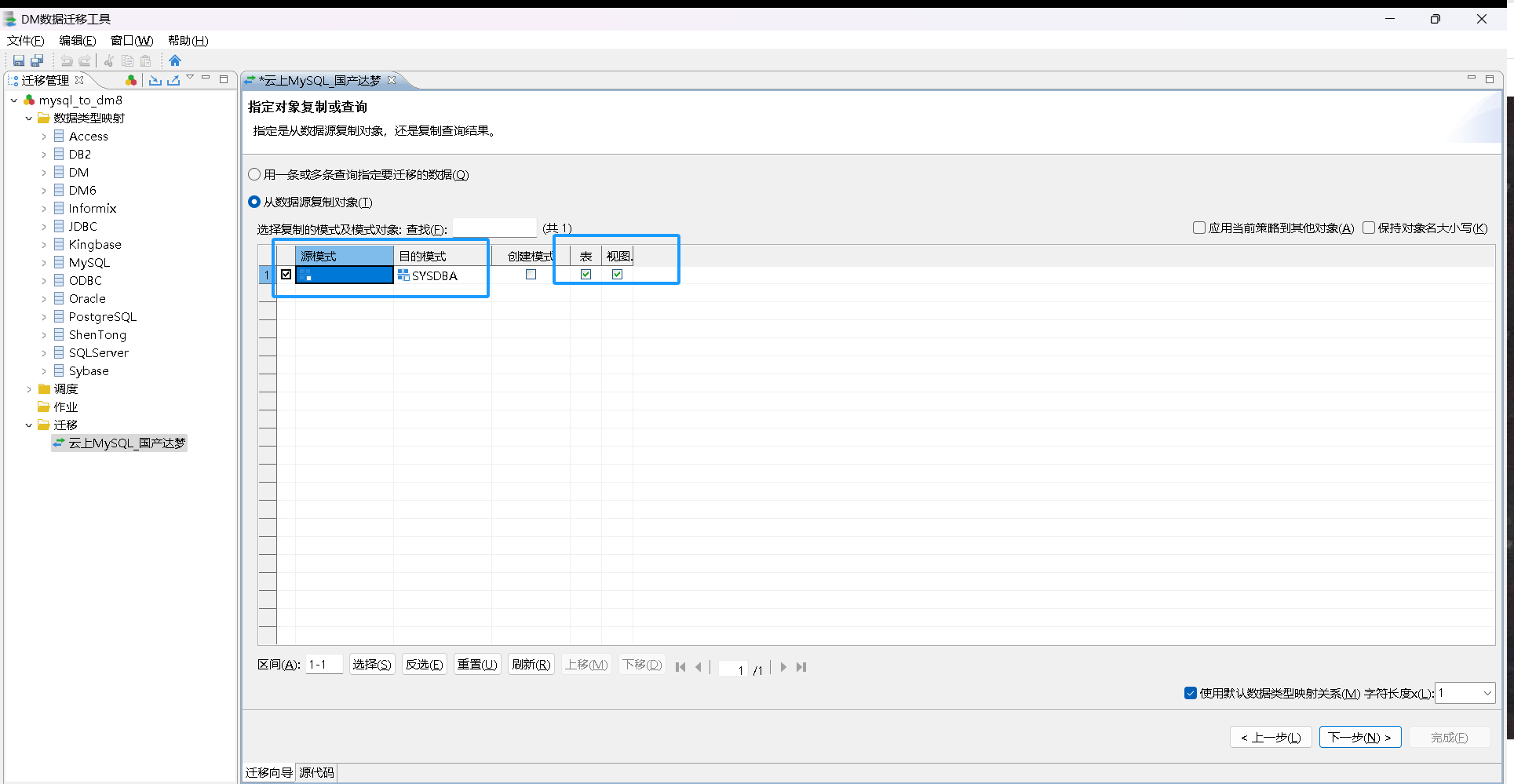
温馨提示:源模式选择源库名称,目标模式选择之前创建好的,迁移到你对应需要的目标模式即可。
指定迁移对象表结构以及数据
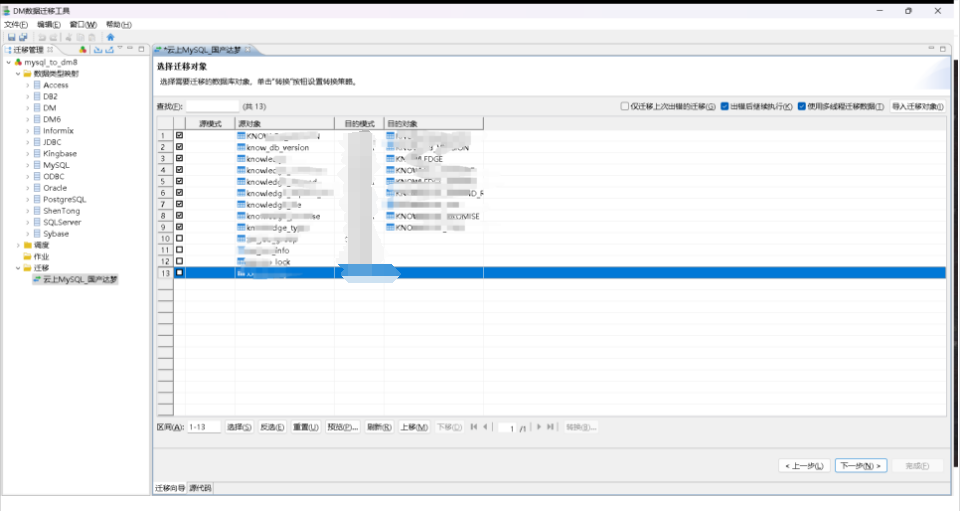
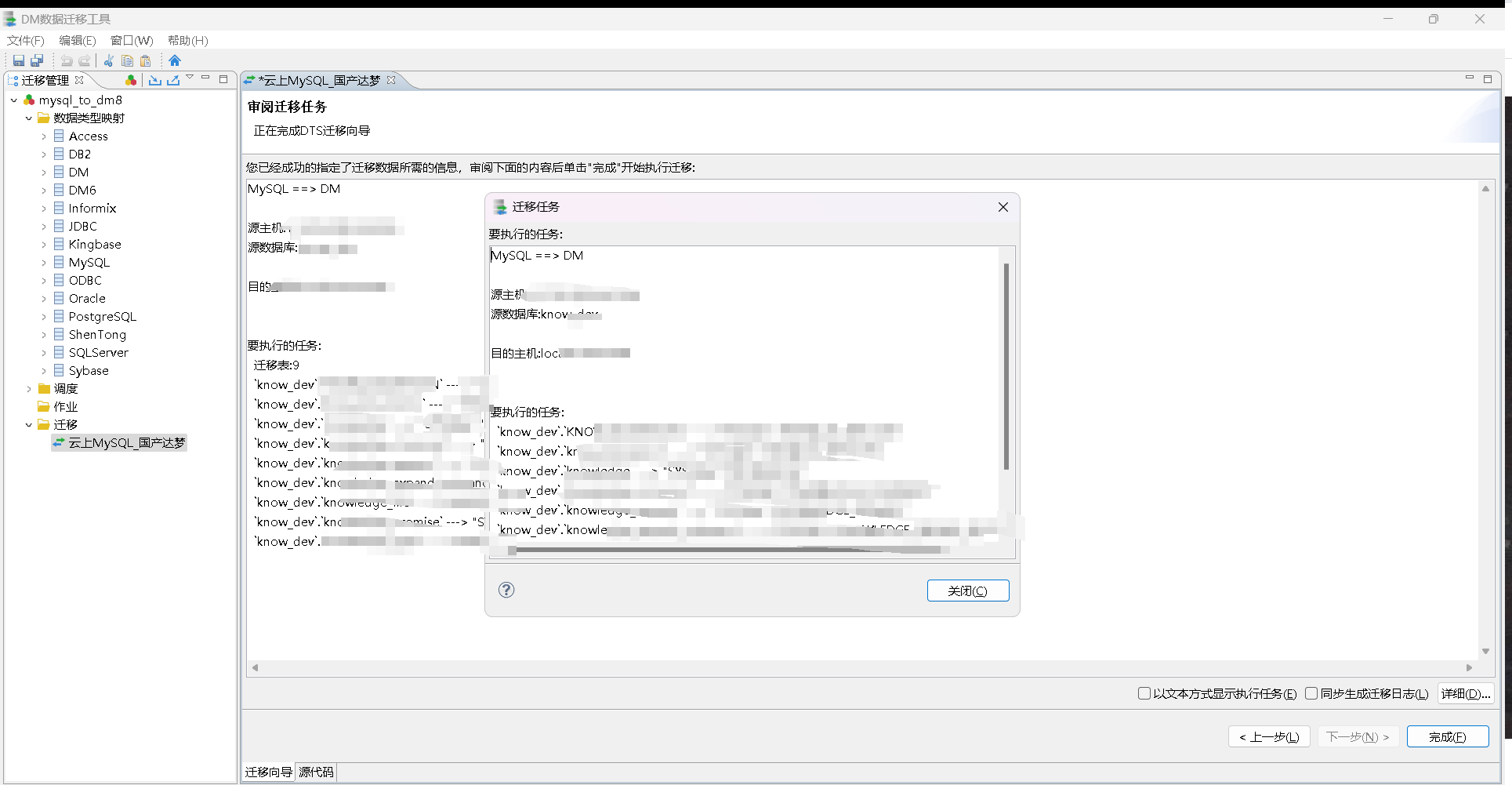
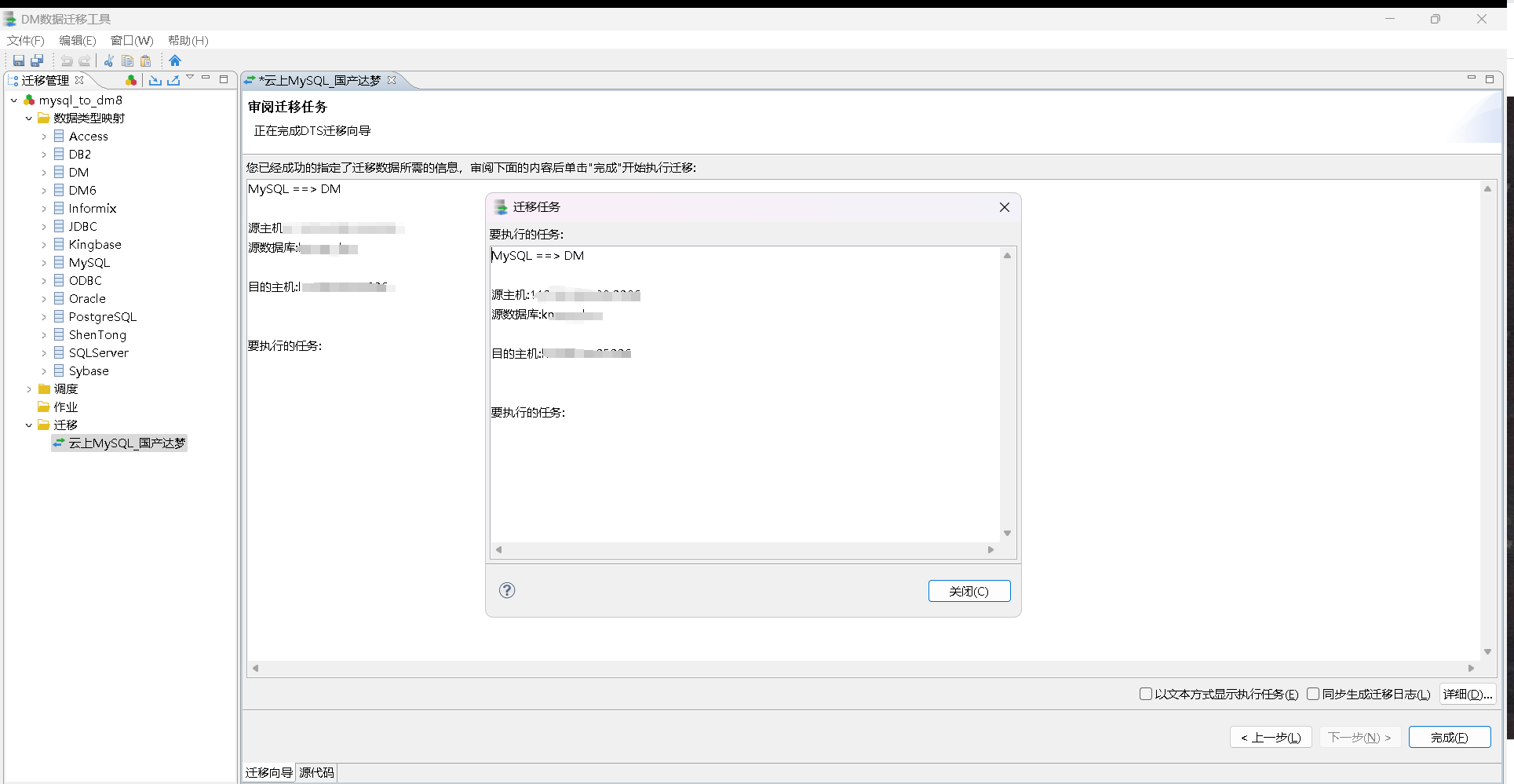
数据迁移过程
我们看看迁移情况,不出所料有成功的也有异常的
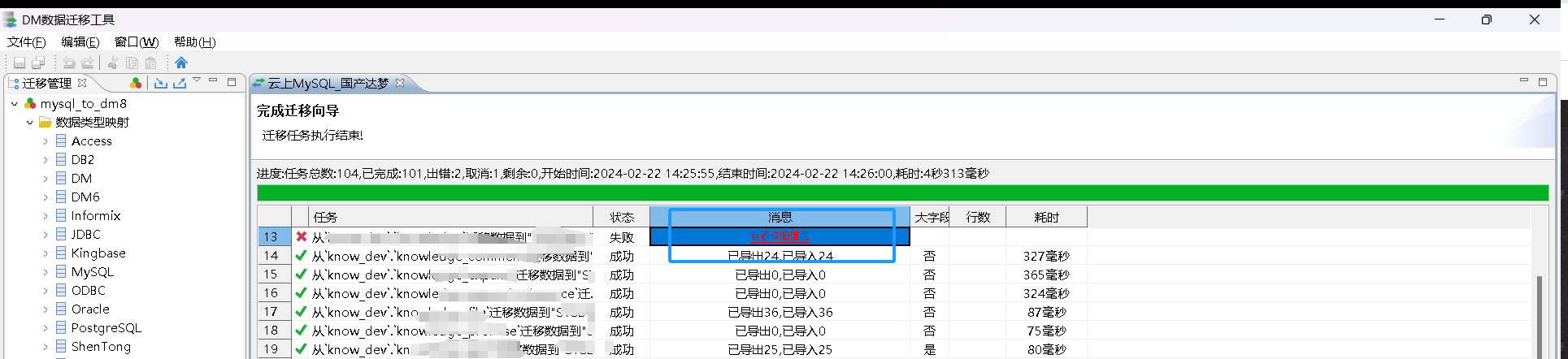
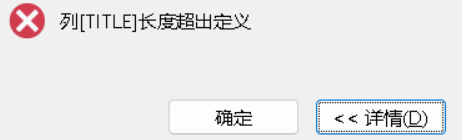
这里调整字段属性的长度定义即可,之前在国产化专栏中已有介绍处理方式,不再赘述!
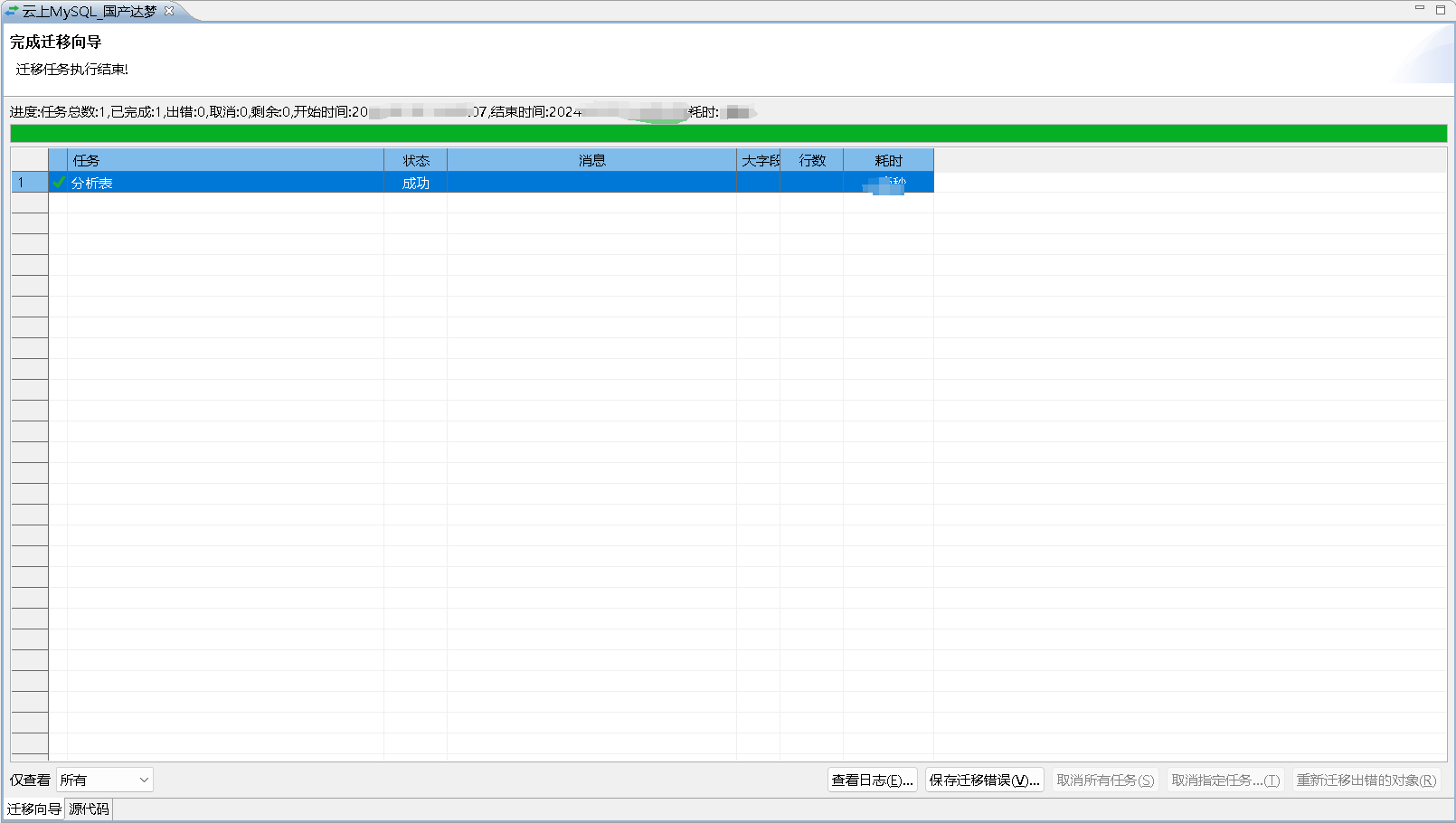
迁移统计情况
我们可以查阅整体的迁移情况,以及相关日志的查阅,便于排查数据的迁移异常分析
归纳&&总结
数据库迁移&异构性兼容:本身数据库迁移,其实是一项复杂的任务。在源库到目标库迁移的过程中,由于多方面因素,就比如数据库表属性上存放的内容在各个数据库体系中所占的位宽都可能存在差异,还有比方说同样在 utf-8 的字符集下存放中文的个数也有所不同,需要我们详细规划,也需要我们仔细留意,细致执行。
归纳:
数据转换和兼容性:将数据从源数据库迁移到目标数据库时,其中数据结构、属性类型、字段索引、约束和关系等可能需要作出调整以适应并匹配目标数据库的模型。
数据恢复和完整性:将数据从源数据库迁移到目标数据库时,有可能出现异常中断,或者出现数据丢失。针对异常的情况进行分析,予以人工干预,检测并修复数据以确保数据的完整性。
从源库到目标库的迁移过程中,考虑目标库的高性能和高可扩展性,不同的 DBMS 可能具有不同的特性和扩展性能力,可能会出现一定性能损失,还有确保数据的安全,以及对整个迁移作业进行管理和监控,这些都是极其重要的考量因素。
总结:
可以通过各厂家提供的迁移工具,进行自动化和转换数据类型格式,以此保障数据的完整性、准确性。
同时,建议各提供商通过一系列机器学习算法,加强对数据格式类型自动化转换、数据内容可靠性训练能力。
通过数据库性能优化工具和技术,对数据库不断进行调优,以提高迁移到目标库后系统的高性能和高可扩展性。
在一定程度上,去减少需要我们人工干预并提高准确性的工作量,使得整个数据库迁移过程可视化出来、更高效、更准确、更可靠!
关注了解更多国产化适配内容实践回顾
推荐阅读
在国产化面前 | 我们应该如何面对?
分布式数据库 | 浅谈OB演进的一点思考
浅谈 | DBA与架构的一次对话交流
开源数据库 | 记一次多方式连接 openGauss 实践之旅
openEuler+openGauss|记一次基于鲲鹏欧拉搭建 openGauss 实践过程
这篇关于数据迁移DTS | 云上MySQL 数据库迁移至达梦数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




