本文主要是介绍【C++进阶】哈希表的闭散列和开散列(哈希桶)的代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

👦个人主页:@Weraphael
✍🏻作者简介:目前学习C++和算法
✈️专栏:C++航路
🐋 希望大家多多支持,咱一起进步!😁
如果文章对你有帮助的话
欢迎 评论💬 点赞👍🏻 收藏 📂 加关注✨
目录
- 一、哈希表的闭散列实现
- 1.1 结构
- 1.2 插入操作
- 1.3 查找操作
- 1.3 删除操作
- 二、哈希表的开散列实现(哈希桶)
- 2.1 结构
- 2.2 构造函数
- 2.3 插入操作
- 2.4 测试
- 2.5 查找操作
- 2.6 删除操作
- 2.7 析构函数
- 三、源码
一、哈希表的闭散列实现
1.1 结构
【分析】
- 当在哈希表中删除值时,如何抹除数据?给个
0或者-1,那如果数据本身就有0或者-1呢,因此不行;挪动数据覆盖就更加不行了,因为会影响数据的哈希值。 - 当在哈希表中插入值时,如果不为空,说明该位置已存储数据,需要向后遍历,直到遇到空位置或者已经删除数据的位置插入。
因此,在闭散列的哈希表中,哈希表每个位置除了存储所给数据之外,还应该存储该位置当前的状态,哈希表中每个位置的可能状态如下:
EMPTY:当前是无数据的空位置EXIST:当前位置已存储数据DELETE:当前位置原本有数据,但被删除了

vector里面有一个size接口为什么还要再定义_n呢?
这是因为哈希表存储数据是分散存储的,因此size接口的大小是不确定的。

1.2 插入操作
- 通过哈希函数计算出对应的哈希地址。当位置的状态是
EMPTY或者DELETE就可以直接插入;如果是EXIT则要向后继续遍历(越界后需要从0开始)

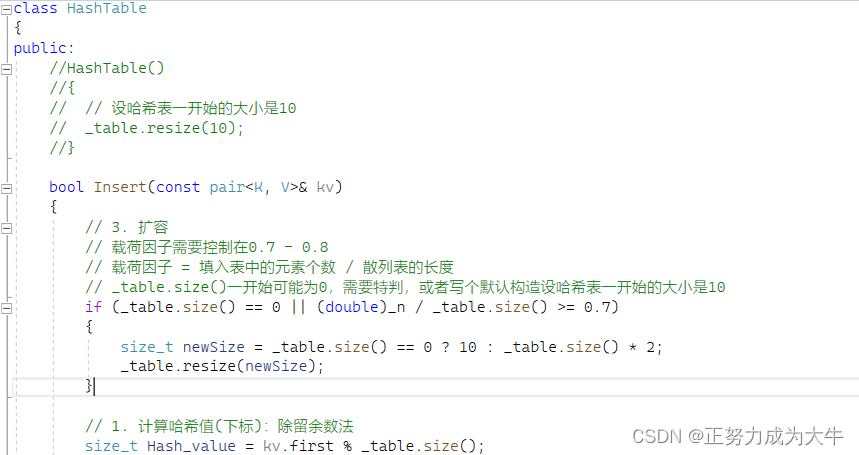
然而如果哈希表中的元素接近满了,这时候就很容易引发哈希冲突,而哈希表不期望这样。那么扩容就很有必要,因此,哈希表引入了负载因子(载荷因子)。
散列表的载荷因子定义为:
α = 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于散列表是定值,α与填入表中的元素个数_n成正比,所以,_n越大,表明填入表中的元素越多,产生冲突的概率就越大;反之,_n越小,标明填入表中的元素越少,产生冲突的概率就越小。- 注意:哈希表不能满了再扩容,需要控制负载因子一定值就扩容。
- 对于散列表,荷载因子
α是特别重要因素,应严格限制在0.7 - 0.8
以上这种扩容方式是由问题的

扩容完后,映射关系变了,需要重新映射。
- 现代写法
步骤如下:
- 创建新哈希表并扩容到足够的空间
- 遍历旧表的数据插入到新表即可(建立映射关系的工作交给
Insert) - 交换新表旧表。

以上代码还有问题,假设key的类型是除了int之外的类型,那么除留余数法就走不通了!因为求余数的两个操作数必须是整数。
因此可以做两次映射。先让key和整型做映射( 使用仿函数),最后再和存储位置做映射。
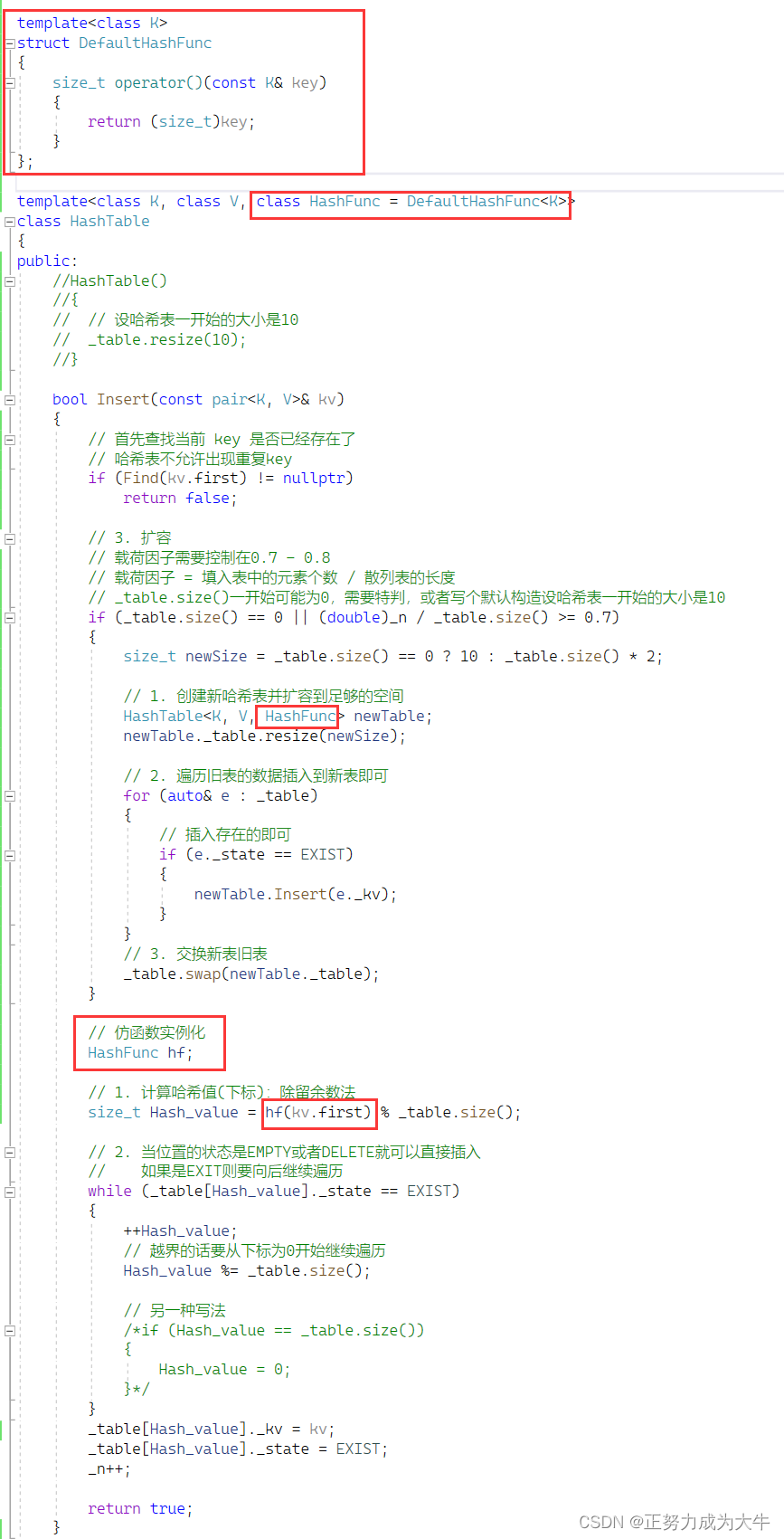
有的人想:在仿函数那一块key不是被const修饰吗,为什么还是能修改key。比如const double key = 1.1转化成(size_t)key = 1
const只限制修饰的对象不能修改,但并不影响对其进行类型转换操作,这是合法的!
但是当测试string类型的时候,发现还是编译不通过
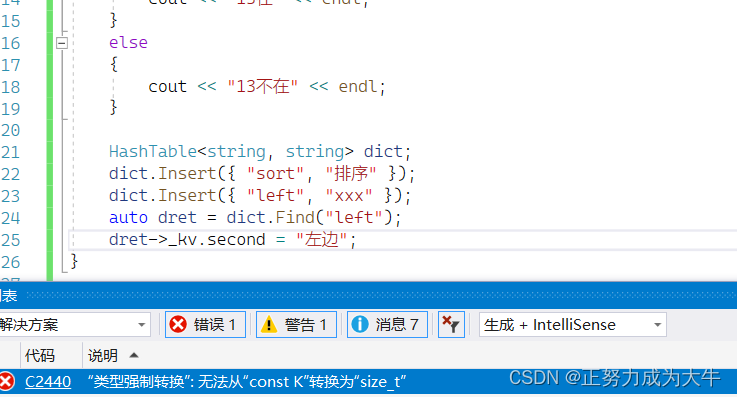
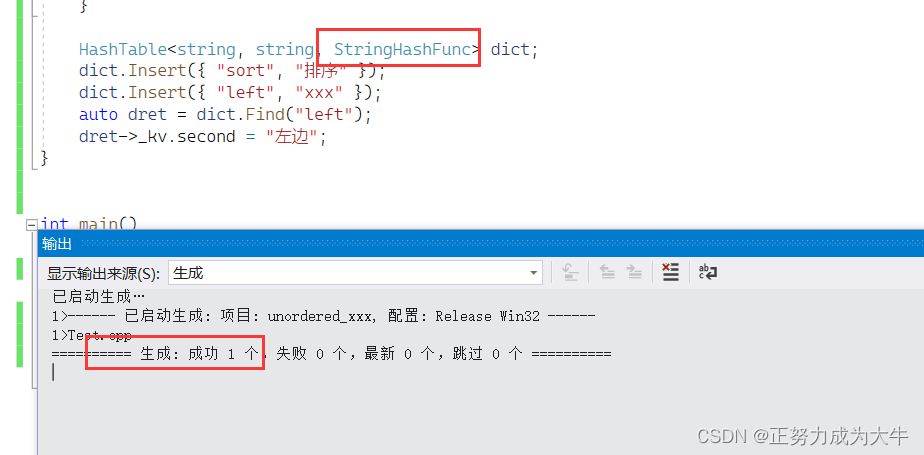
法一:可以再针对string类型写一个仿函数

然后编译就通过了
但是返回字符串的第一个字符的asc码也不好,万一序列中字符串第一个字符都相等,那么又会引发哈希冲突的概率就越大。因此,可以将字符串中的asc码全部相加再返回
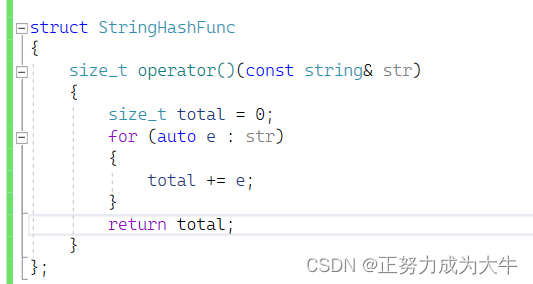
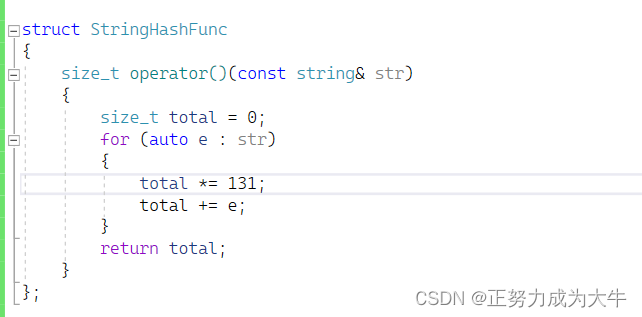
但是因此方法还是完美避免哈希冲突。比如有这些字符串:"abc"、"bac"、“cab”等九种排列组合,它们相加的asc码都是一样的。因此,就有人发明了字符串哈希算法:点击跳转。它的思想也是将所有字符的asc码相加,但是在相加之前乘以131
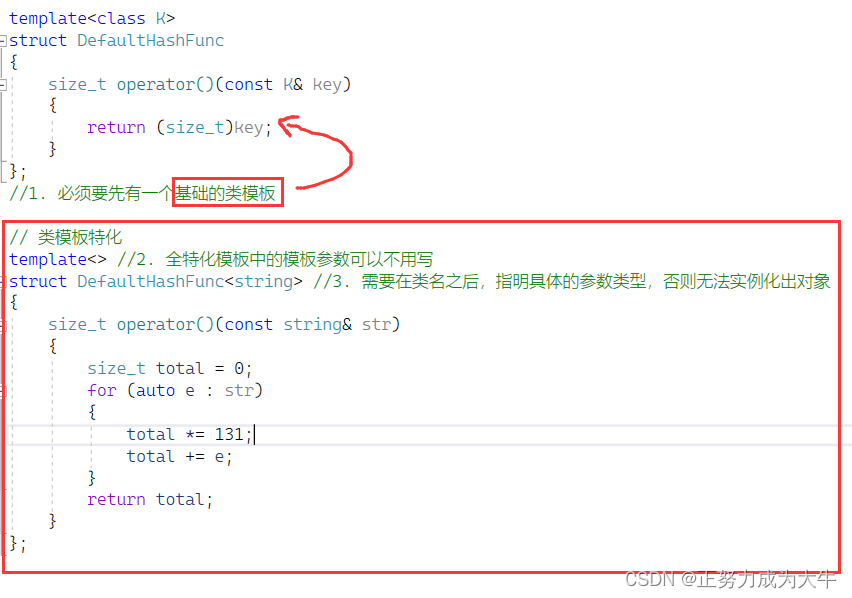
法二:类模板特化。好处:不用在main函数显示传递列表类型,由编译器自己匹配
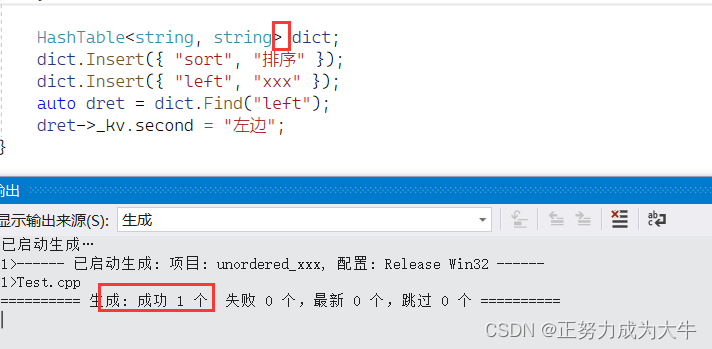
同样也能编译通过
1.3 查找操作
-
通过哈希函数计算出对应的哈希地址。
-
如果位置的状态是
EXIST则要比较key。相等返回,不相等继续向后找。 -
如果位置的状态是
DELETE还要继续向后找 -
如果位置的状态是
EMPTY就没有必要向后查找了

1.3 删除操作
- 调用
Find函数,如果找到了,直接在当前位置标记为DELETE;否则返回false
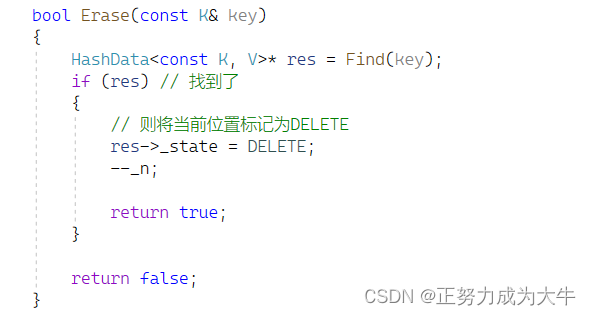
闭散列只做简单了解即可,真正重点在于开散列
二、哈希表的开散列实现(哈希桶)
2.1 结构
开散列又称为哈希桶。当发生哈希冲突时,直接在冲突位置挂着一个单链表,形似一个桶,也看作是一个指针数组。
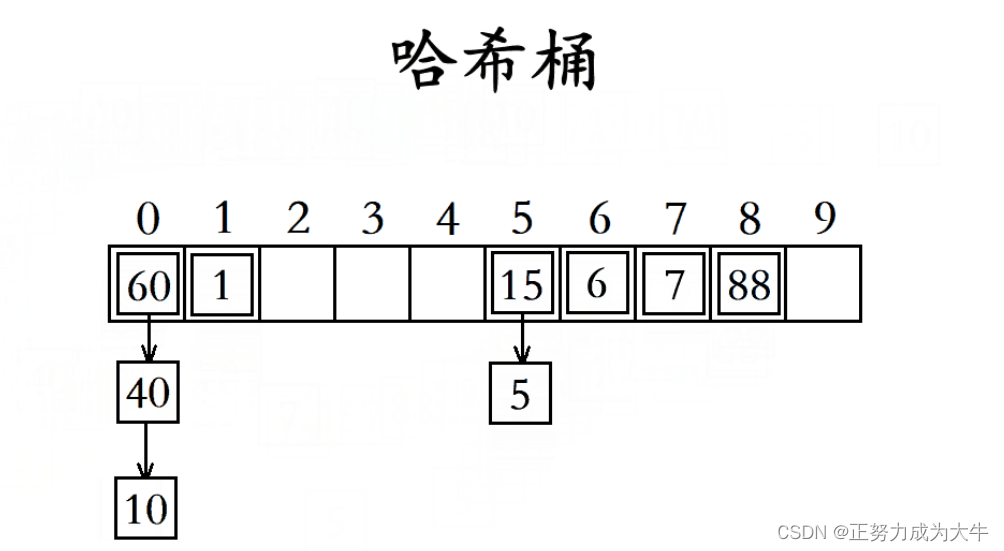
该结点类型除了存储所给数据之外,还需要存储一个结点指针用于指向下一个结点。

在开散列的哈希表中,哈希表的每个位置存储的实际上是某个单链表的头结点,即每个哈希桶中存储的数据实际上是一个结点类型。
当然了,在插入数据时也需要根据负载因子判断是否需要增容,所以我们也应该存储哈希表中的有效元素个数,当负载因子过大时就应该进行哈希表的增容。

与闭散列的哈希表不同的是,开散列是将相同哈希值的元素都放到了同一个哈希桶中,并不需要经过探测寻找所谓的下一个位置,因此不需要存储状态字段。
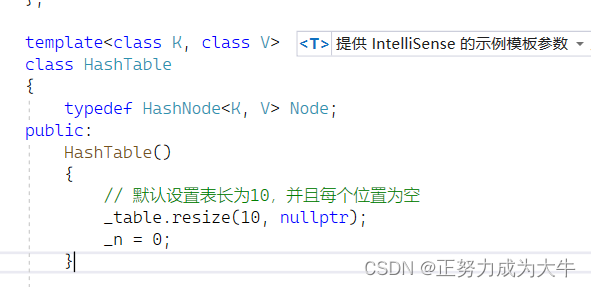
2.2 构造函数
- 默认设置表长为
10,并且初始化每个位置都为空nullptr
2.3 插入操作
在进行数据插入时,既可以尾插,也可以头插,因为桶中的存储顺序没有要求。为了操作简单,这里 选择头插
【头插思路】
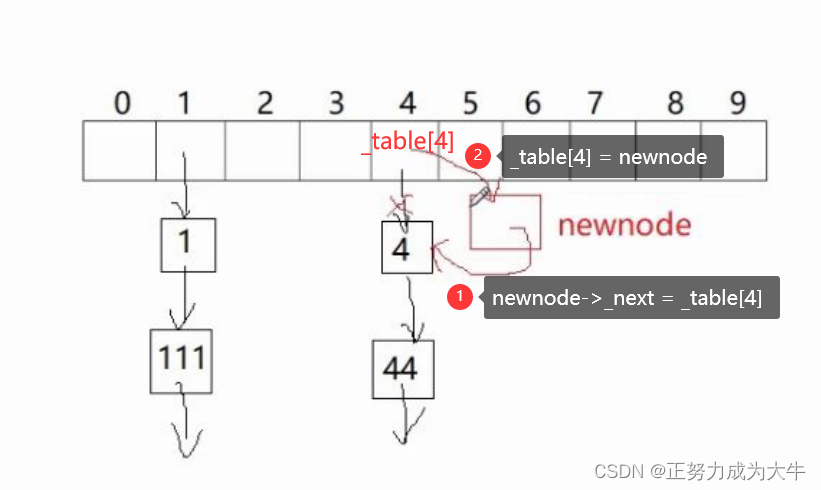
【代码实现】
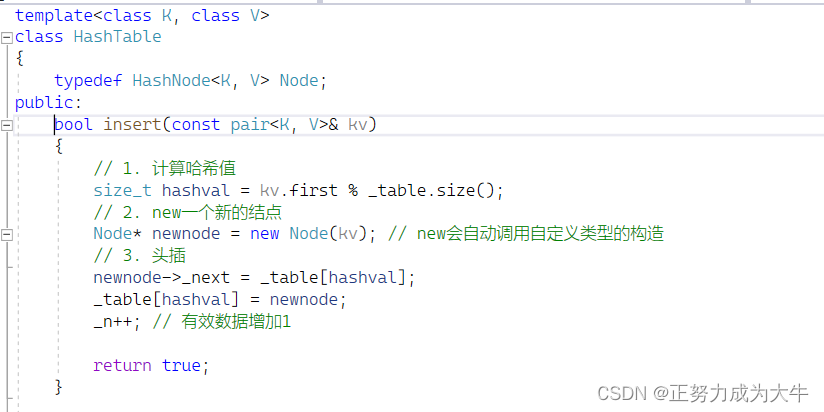
随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,。那么这就和链表没什么区别了,因此在一定条件下需要对哈希表进行增容。
那该什么条件需要增容呢?
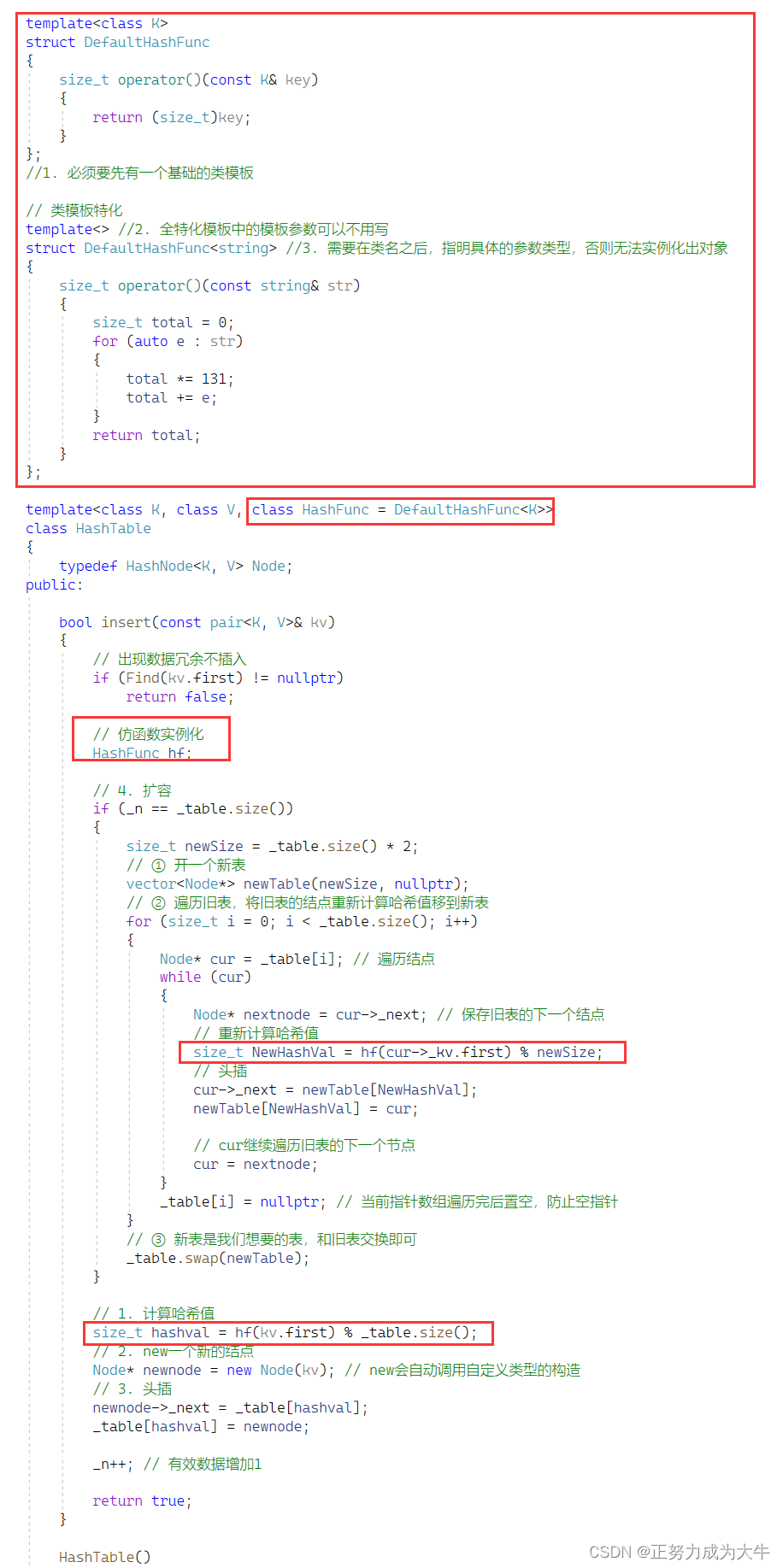
开散列的扩容还是要控制负载因子α = 填入表中的元素个数 / 散列表的长度。对于开散列,一般控制在1,即填入表中的元素个数 == 散列表的长度。
注意:扩容的时候不能像闭散列一样复用insert,因为开散列的insert是有new操作的,会有损耗。
因此,这里可以步骤是:
- 开一个新表
- 遍历旧表的结点,通过计算结点在新表的哈希值,然后头插到新表中
- 最后新旧表交换。

当然还要特殊处理key是不是整数的情况(和闭散列一样)
2.4 测试

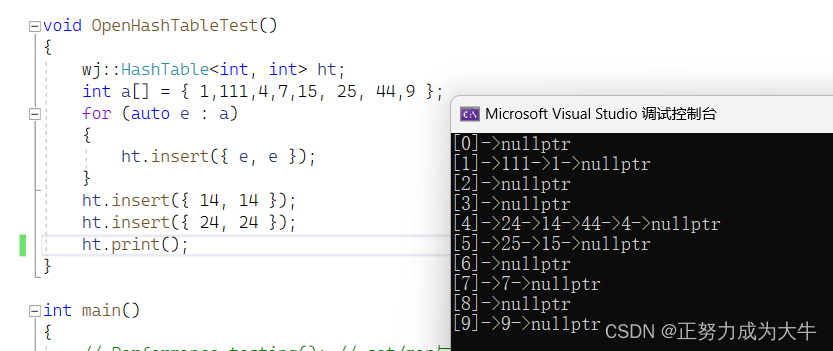
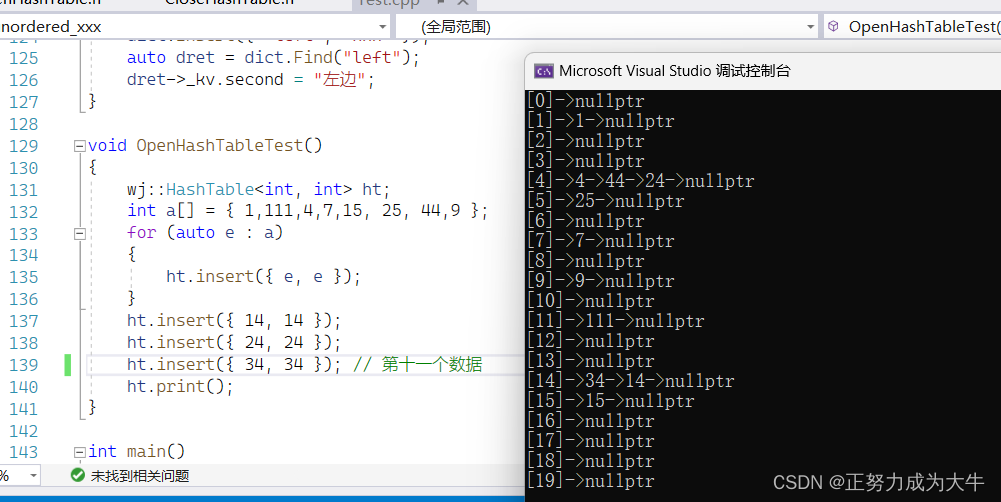
【测试结果】
-
插入十个数据(没有扩容)
-
插入十个数据(扩容
2倍)
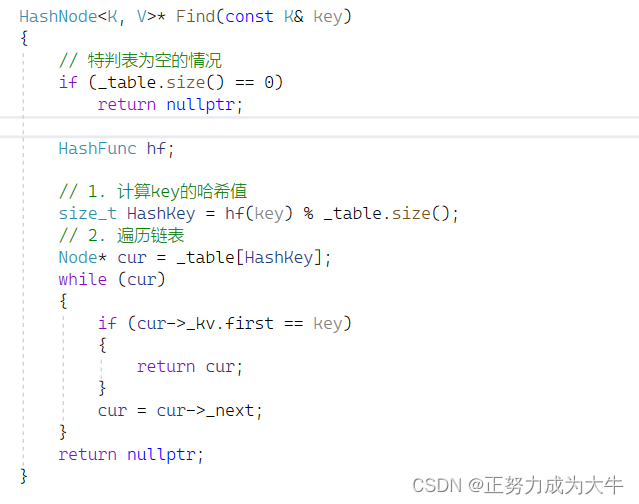
2.5 查找操作
步骤:
- 首先计算查找元素的哈希值
- 最后再根据哈希值去遍历链表
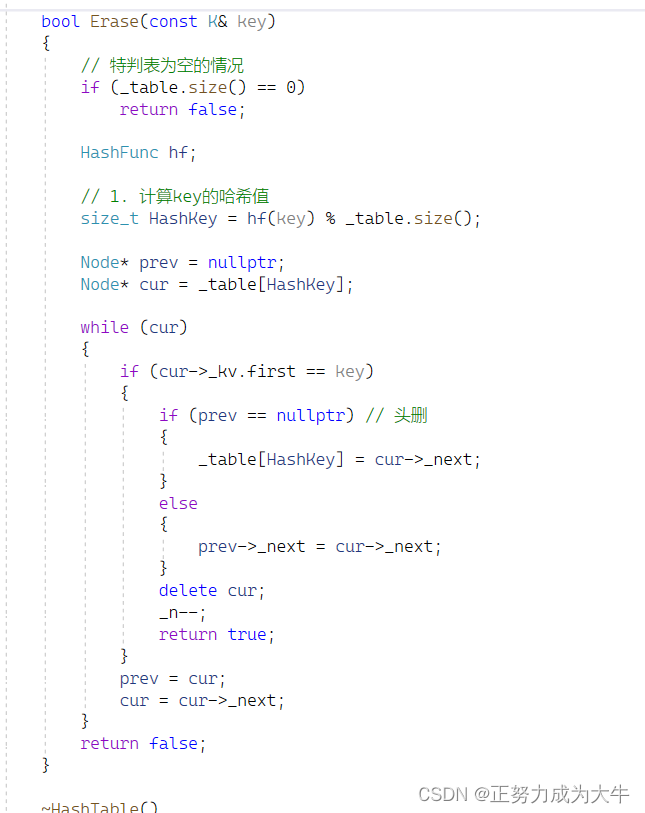
2.6 删除操作
步骤:
- 通过哈希函数计算出
key的哈希值。 - 遍历链表查找并删除。要注意头删的情况
2.7 析构函数
因为有new操作,所以需要手动遍历将其释放,避免内存泄漏

三、源码
Gitee仓库链接:点击跳转
这篇关于【C++进阶】哈希表的闭散列和开散列(哈希桶)的代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


