本文主要是介绍YOLOv5 项目:推理代码(detect),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、前言
本章将介绍yolov5项目的推理函数,关于yolov5的下载和配置环境,参考上一篇文章:
YOLOv5 项目:环境配置-CSDN博客

pycharm 中打开的推理模块如红框中所示
pycharm将conda新建的虚拟环境导入,参考 :pycharm 配置 conda 新环境
2、推理一下看看
大部分运行代码都是在pycharm里面运行,但其实更多的在命令行里直接运行反而方便
命令行参考代码如下:
python detect.py --source 0 # webcamimg.jpg # imagevid.mp4 # videopath/ # directorypath/*.jpg # glob'https://youtu.be/Zgi9g1ksQHc' # YouTube'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
path/*.jpg,这个意思就是预测path文件夹下以.jpg结尾的文件。
命令行直接运行python detect.py文件或者pycharm直接运行的话,会自动推理官方预设的图片
推理打印的日志,这里可以看到推理的文件放在runs\detect\exp里面

这里的runs文件夹可以删除,下次推理会自动生成新的序列
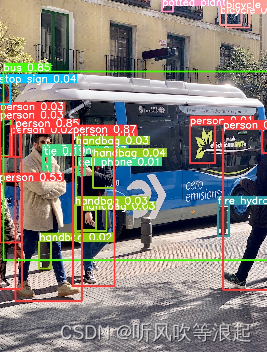
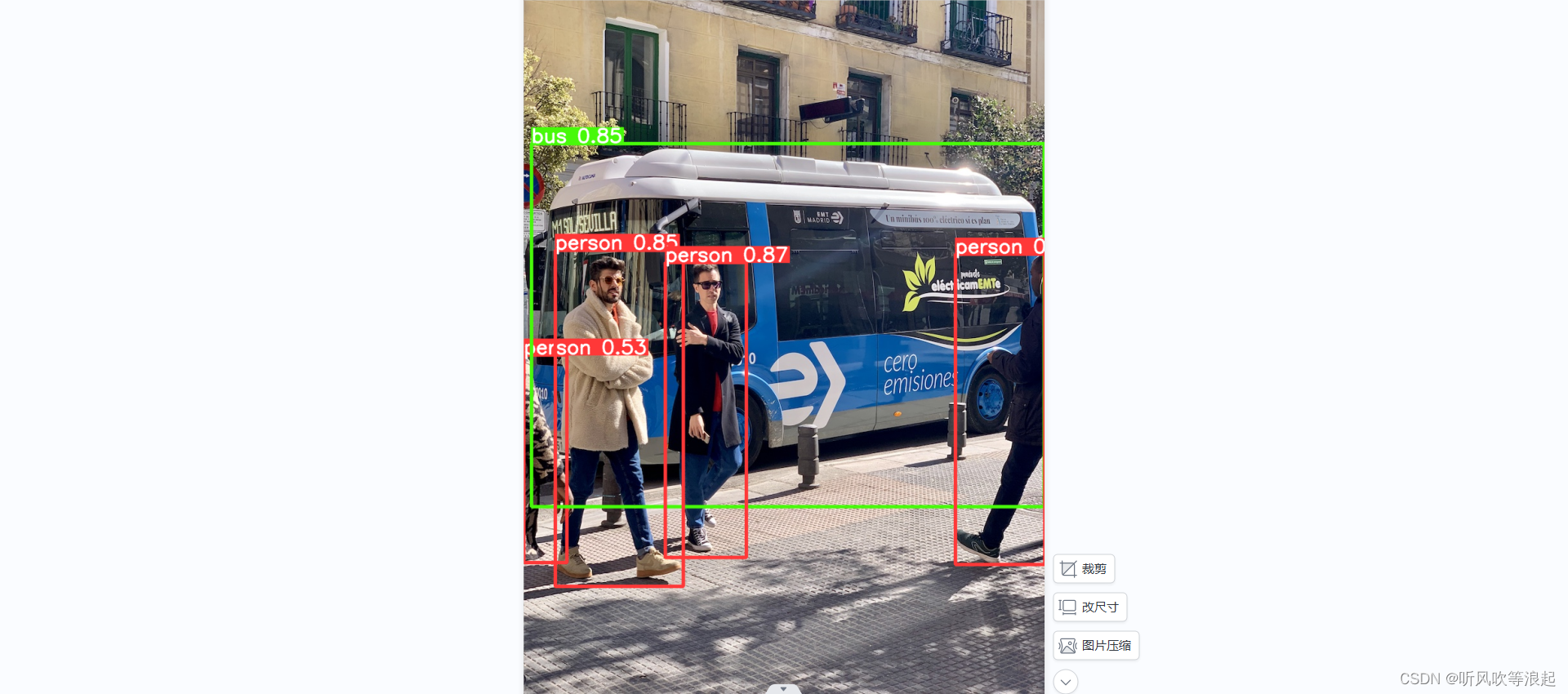
推理结果:

3、detect 代码参数讲解
参数如下,模型推理的超参数都在里面

需要注意的带有 action = 'store_true' ,理解为布尔类型的参数,默认就是关闭。如果打开的话,直接用python detect.py --save-txt 即可
其他类型的要在后面跟实参,例如python detect.pt --conf-thres 0.5
3.1 weights 权重文件
yolov5网络推理的权重参数文件,需要注意的是这里默认的是yolov5.pt,所以首次推理不需要指定权重,网络会自动从网上下载权重

官方提供的权重如下所示,当然也可以指定自己训练好的
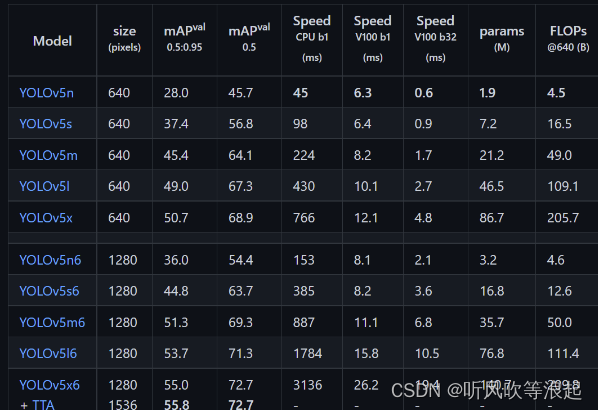
3.2 source 待推理的路径
这里默认的是data/images,里面放的就是上面推理的两张原图

这里可以是单张图片、整个目录、视频、乃至摄像头都可以

3.3 data 配置文件
配置文件,例如分类的个数啊、训练数据的路径等等

训练的时候要更改,要不然会训练coco的数据集!!!
3.4 imgsz、img、img-size 输入数据的尺寸
意思在推理的时候,将图片缩放成多少的size,然后喂到网络里
这里最后还会还原图像的大小
![]()
注意:这里的size要和训练的size一致,这样效果最好。
理论上size训练的时候越大效果越显著,但并不一定,并且会大大加深网络的计算量
3.5 conf-thres 置信度阈值
通俗来说,网络计算出的目标会有一个预测概率(这里就叫置信度)
![]()
置信度越低的时候,框会越多
| conf-thres = 0.01 | conf-thres = 0.25 | conf-thres = 0.8 |
 |  |  |
这里没有固定的值,都是动态调节的,不会设置的话就按照官方设定值
3.6 iou-thres IOU阈值
IOU 阈值,值越大,框越多
![]()
当同一个目标周围好多个框,会进行NMS非极大值抑制,两个框重叠到多大程度才会去除呢?
重叠的程度就按照iou来算,数值就是设定的数值

3.7 max-det 检测最大的数量
一张图片最大的检测数量
![]()
如果目标多余这个阈值,就会按照conf-thres 置信度阈值显示前面的max-det个
3.8 device 推理设备
推理的设备,不指定会自动检测
![]()
3.9 view-img 实时检测的时候是否展示
检测的时候是否展示
![]()
想要使用直接运行下面命令即可:
python detect.py --view-img
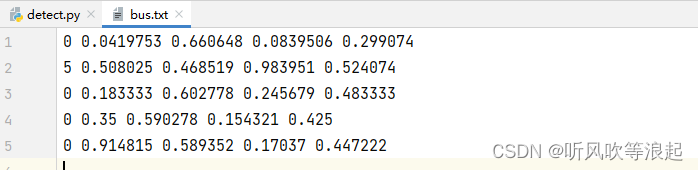
3.10 save-txt 保存边框、类别的信息
将检测出来的边界框和目标按照yolo格式保存在txt文本
在标注数据的时候,可以辅助标注
![]()
使用如下:
python detect.py --save-txt

3.11 save-csv 保存边界框信息以csv格式
同 save-txt,只不过以csv的形式保存
3.12 save-conf 保存txt中的置信度
配合save-txt使用,否则没有效果
这个参数会在txt文本里,加一个置信度
3.13 save-crop 保存检测的裁剪区域
这会把检测的边界框裁剪出来,并且按照类别保存在对应的文件夹里
![]()
裁剪出来的目标可以用于图像分类
3.14 nosave 不保存推理结果
配合--view-img 使用
不会生成预测结果,但是还是会生成exp空的文件夹
3.15 classes 指定推理哪个类别
指定哪个类别,就只会预测哪个
![]()
python detect.py --classes 0 2 33.16 agnostic-nms 跨类别的NMS
如果一个物体被预测成两个类别,那么这个物体会被标注两个预测框。打开这个函数,就只会显示预测大置信度的边界框
3.17 augment 推理增强
增强推理的函数
3.18 visualize 可视化特征图
把网络特征图可视化出来,如下

3.19 update
用于模型训练最后得到去除优化器信息,去除不必要的文件
3.20 project 保存路径
就是保存路径,建议不更改
![]()
3.21 name 保存文件夹名字
就是保存文件夹名字,建议不更改
![]()
3.22 exist-ok 保存位置是否更替
每次推理都会生成新的exp文件夹,打开这个就不会了,直接删除前面的,在里面保存此次的推理结果
3.23 line-thickness 边界框的粗细
字面意思
3.24 hide-labels 隐藏标签
打开后,只有边界框,没有label和置信度
3.25 hide-conf 隐藏置信度
打开后,有边界框和label,没有置信度
326 half 半精度推理
类似于训练过程的混合精度推理
3.27 dnn
是否使用opencv dnn进行ONNX推理
3.28 vid-stride
推理视频的时候,推理步长
4、 常用参数介绍
参数太多,大部分一般用不到,这里介绍常见的关键参数
4.1 weights 权重参数
根据自己需要选择

4.2 source 检测的文件
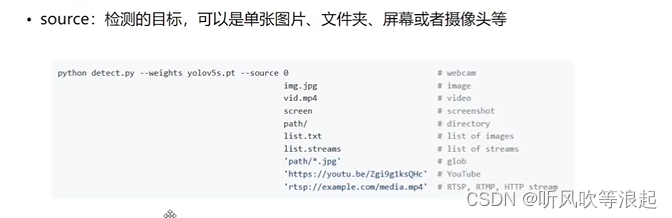
- python detect.py --source data/images/bus.jpg 对指定路径的单个图片进行推理

- python detect.py --source screen 对当前屏幕进行检测
4.3 其他参数
有的参数也很重要,例如置信度阈值啊、iou阈值、coco的配置文件啊等等,但一般的检测任务都不需要改变,使用官方的预设值即可。
5. 其他
提供一个简单的推理代码
import torchmodel = torch.hub.load('./','yolov5s',source='local')img = './data/images/bus.jpg'ret = model(img)ret.show()

这篇关于YOLOv5 项目:推理代码(detect)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






