本文主要是介绍【Intel oneAPI实战】使用英特尔套件解决杂草-农作物检测分类的视觉问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、简介:计算机视觉挑战——检测并清除杂草
- 二、基于YOLO的杂草-农作物检测分类
- 2.1、YOLO简介
- 2.2、基于YOLO的杂草-农作物检测分类解决方案
- 三、基于YOLO的杂草-农作物检测分类系统设计
- 3.1、基于flask框架的demo应用程序后端
- 3.2、基于Vue框架的demo应用程序前端
- 四、Intel oneAPI工具包使用
- 五、后续待完善的部分
科技是人类历史发展最具革命性的关键力量,而科技创新将是赢得未来发展主动权的必然选择。
如今,新一轮科技革命和产业革命正蓬勃兴起。它不再是单一科学领域、技术领域的突破,而是在信息技术、人工智能、新能源、新材料、生物医药等多领域、多赛道竞相迸发。

前段时间,我荣幸参加了英特尔和C站官方联合举办的[oneAPI的人工智能黑客松活动,并且第一次使用英特尔的官方套件来解决了杂草-农作物检测分类的问题,本篇博客将分享下解决方案和心得体会。
一、简介:计算机视觉挑战——检测并清除杂草

杂草是农业经营中不受欢迎的入侵者,它们通过窃取营养、水、土地和其他关键资源来破坏种植,这些入侵者会导致产量下降和资源部署效率低下。一种已知的方法是使用杀虫剂来清除杂草,但杀虫剂会给人类带来健康风险。
参赛者需运用英特尔® oneAPI AI分析工具包构建一个模型。该模型可以自动检测杂草的存在,并在杂草上而不是在作物上喷洒农药,同时使用针对性的修复技术将其从田地中清除,从而最小化杂草对环境的负面影响。
二、基于YOLO的杂草-农作物检测分类
2.1、YOLO简介
YOLO是一种基于深度学习的目标检测算法,全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。由Joseph Redmon等人于2016年提出。相比于传统的目标检测算法,如RCNN、Fast RCNN、Faster RCNN等,YOLO算法具有更快的检测速度和更高的准确率,因此在目标检测领域得到了广泛的应用。

因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
也就是说,一个典型的Region-base方法的流程是这样的:先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域,将这些区域裁剪下来,放入一个图片分类器中,由分类器分类。
YOLO算法的核心思想是将目标检测问题转化为一个回归问题,即通过一个神经网络直接预测目标的类别和位置。具体来说,YOLO算法将输入图像分成S×S个网格,每个网格预测B个边界框和每个边界框的置信度和类别概率。在预测时,YOLO算法将每个边界框的置信度和类别概率相乘,得到每个边界框的最终得分,然后根据得分进行非极大值抑制,得到最终的目标检测结果。
YOLO算法的优点在于它可以在一个神经网络中同时完成目标检测和分类,而且检测速度非常快,可以达到实时检测的要求。此外,YOLO算法还可以处理多个目标的检测,而且对于小目标的检测效果也比较好。
2.2、基于YOLO的杂草-农作物检测分类解决方案
基于YOLO,可以设计一种杂草-农作物的分类解决方案,具体来说,基于YOLO的杂草-农作物分类解决方案包括以下几个步骤:
- 数据采集和处理。首先,需要采集大量的杂草和农作物的图像数据,并对这些数据进行处理和标注,以便后续的模型训练和测试。
- 模型训练和测试。在进行杂草-农作物的分类时,需要使用YOLO算法来训练分类模型,并对模型进行测试和评估,以确定其准确率和鲁棒性。
- 应用和优化。在进行杂草-农作物的分类时,需要将训练好的模型应用到实际场景中,并优化精度和速度。
数据采集部分:赛道主办方已经为我们准备好了杂草-农作物数据集:https://filerepo.idzcn.com/hack2023/Weed_Detection5a431d7.zip
每张图片还包括一个指示类别和标记框的txt,其中第一个数值表示分类,0表示农作物,1表示杂草,如下所示:
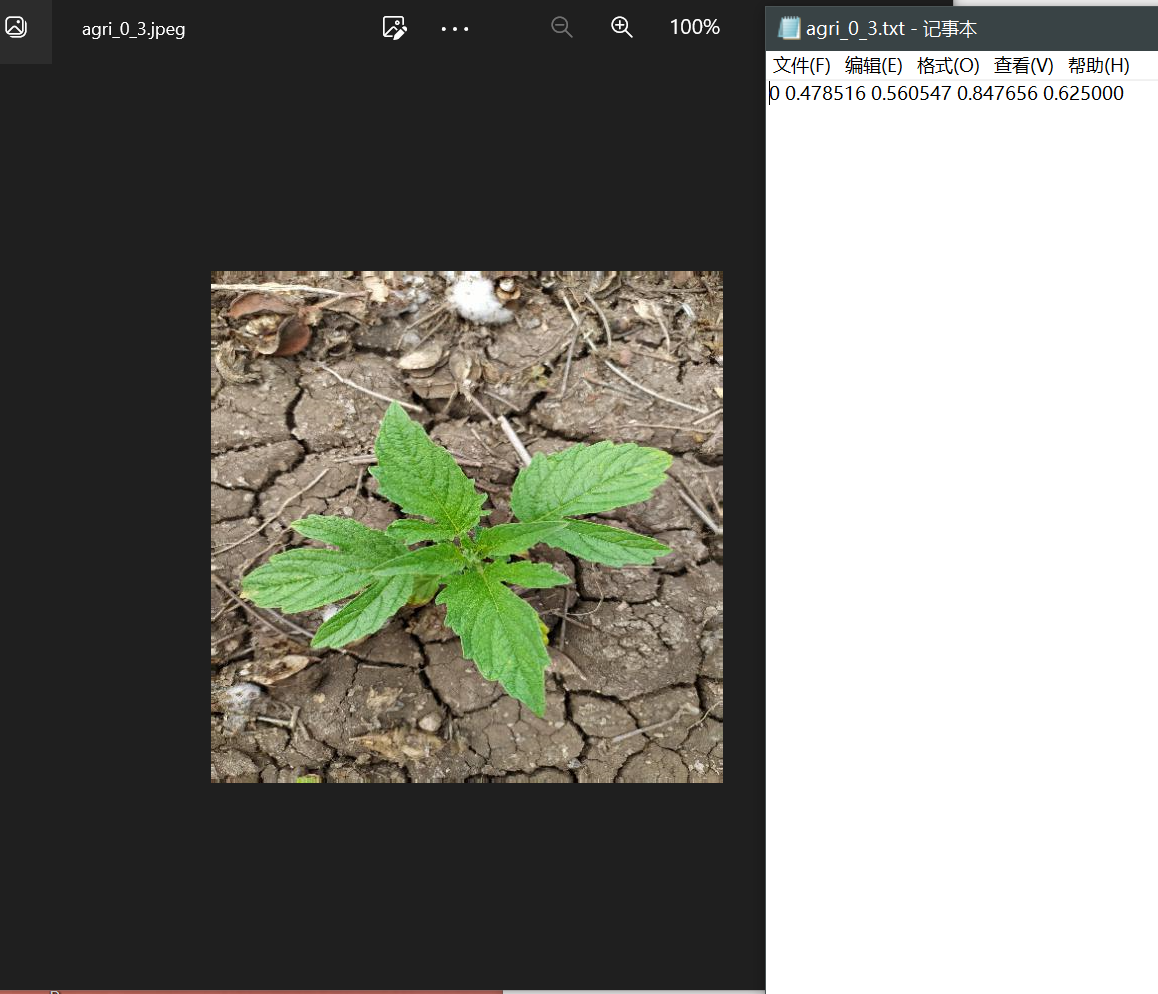
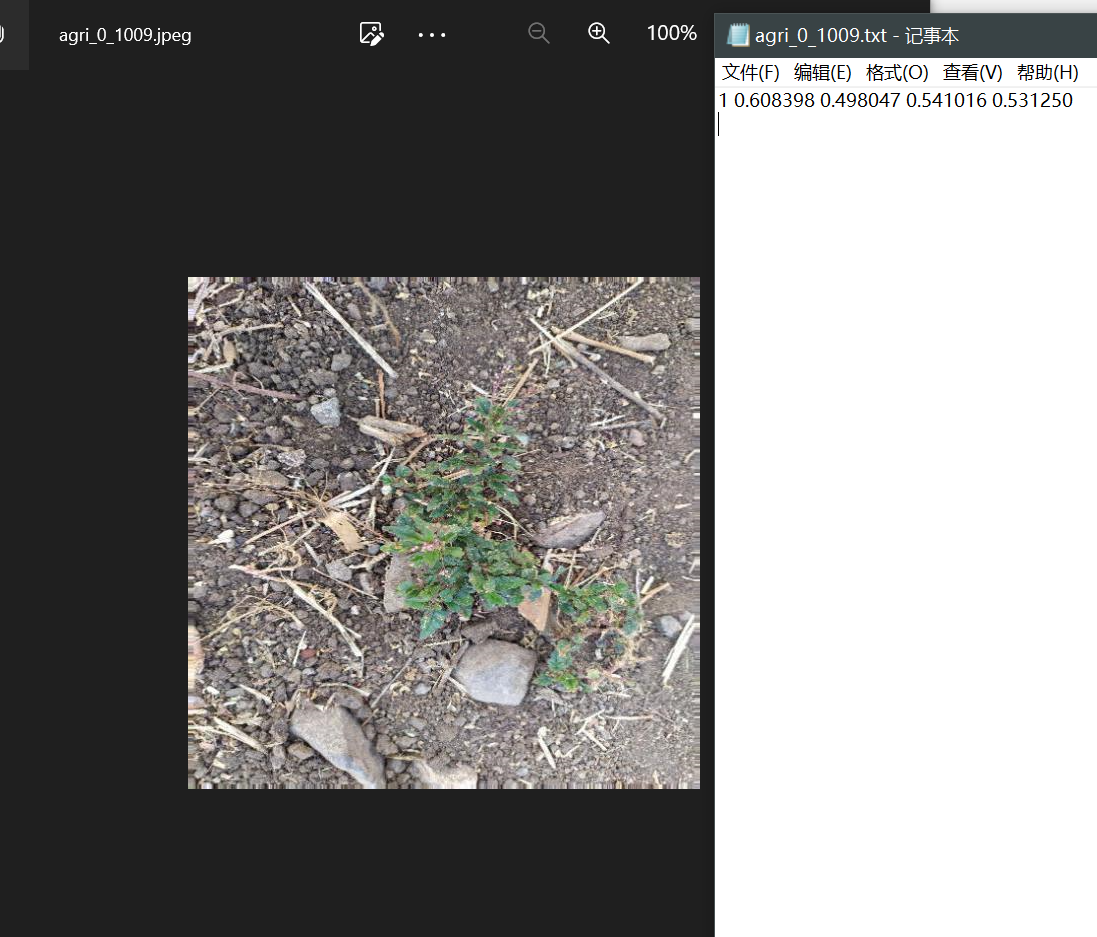
模型的训练部分:我们参考ravirajsinh45大佬的代码作为baseline,这是一个深度学习模型Darknet,其中包含了多个卷积层、上采样层、shortcut层、route层和yolo层。其中,卷积层用于提取特征,上采样层用于将特征图的尺寸扩大,shortcut层用于实现跨层连接,route层用于将多个层的特征图拼接在一起,yolo层用于目标检测。模型的前向传播过程中,根据不同的层类型,对输入进行相应的处理,最终输出目标检测结果。模型的参数可以通过load_weights函数加载预训练的权重。
将赛题方提供的数据集导入其中,并进行简单配置,进行训练。
应用和优化:在训练成功后,我们将模型使用后端flask框架部署到服务器中,并写一个前端demo部署到客户端,模拟实际应用场景。
三、基于YOLO的杂草-农作物检测分类系统设计
3.1、基于flask框架的demo应用程序后端
后台需要设计两种功能,一种是上传图片,一种是分析图片
- /upload:用于上传文件,接收
POST请求,从请求中获取上传的文件,保存到服务器的upload目录下,并返回上传成功的信息。 - /analyze:用于分析上传的图片,接收
POST请求,调用detection函数(detection函数为调用之前训练好的模型)对上传的图片进行分析,将结果保存为PNG图像,并将PNG图像转换为 Base64 编码,最后将分析结果和Base64编码作为JSON格式的响应返回给客户端。
在 if __name__ == '__main__': 语句中,使用 app.run() 启动 Flask 应用程序,监听本地的 3031 端口,等待客户端的请求。
将其设计如下:
@app.route('/upload', methods=['POST'])
def upload():# 获取上传的文件if 'file' not in request.files:return '请选择文件'file = request.files['file']# 保存文件file.save('upload/'+'image.jpeg')# 返回成功信息return '文件上传成功'@app.route('/analyze', methods=['POST'])
def analyze():res_cls_name, res_cls_conf = detection('upload/image.jpeg')# 打开结果PNG图像with open('result.png', 'rb') as f:image_data = f.read()# 将PNG图像转换为Base64编码base64_data = base64.b64encode(image_data).decode('utf-8')print(res_cls_name)print(res_cls_conf)response = {'message': 'File uploaded successfully','res_cls_name': res_cls_name,'res_cls_conf': str(res_cls_conf.item()),'base64_data' : base64_data}return json.dumps(response), 200if __name__ == '__main__':app.run(host='0.0.0.0', port=3031)
3.2、基于Vue框架的demo应用程序前端
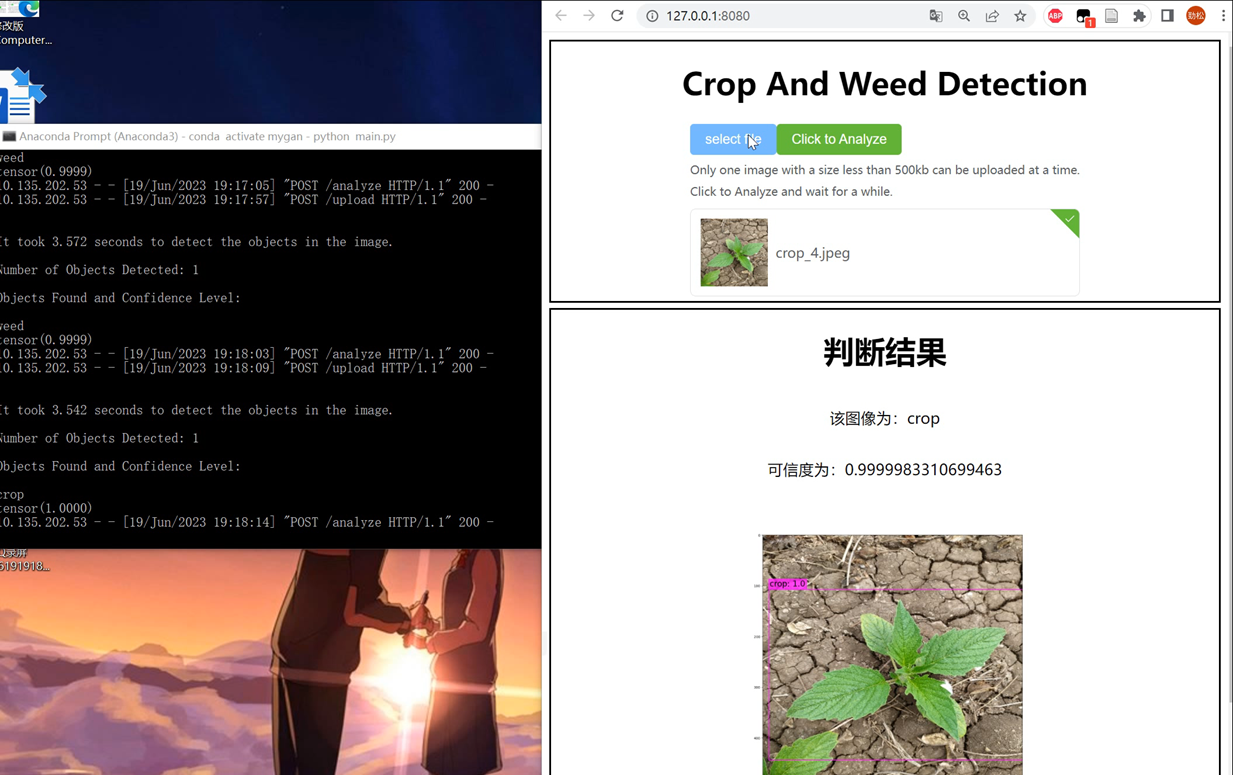
构建一个基于 Vue.js 框架的前端页面,使用 Element Plus 组件库中的 el-upload 组件进行图片上传,分析结果会显示在页面的下侧,包括图片的分类名称、可信度和图片本身。其中,分类名称和可信度是通过调用后端 API 获取的,图片则是通过将后端返回的 Base64 编码转换为图片显示出来的,运行效果如下
:
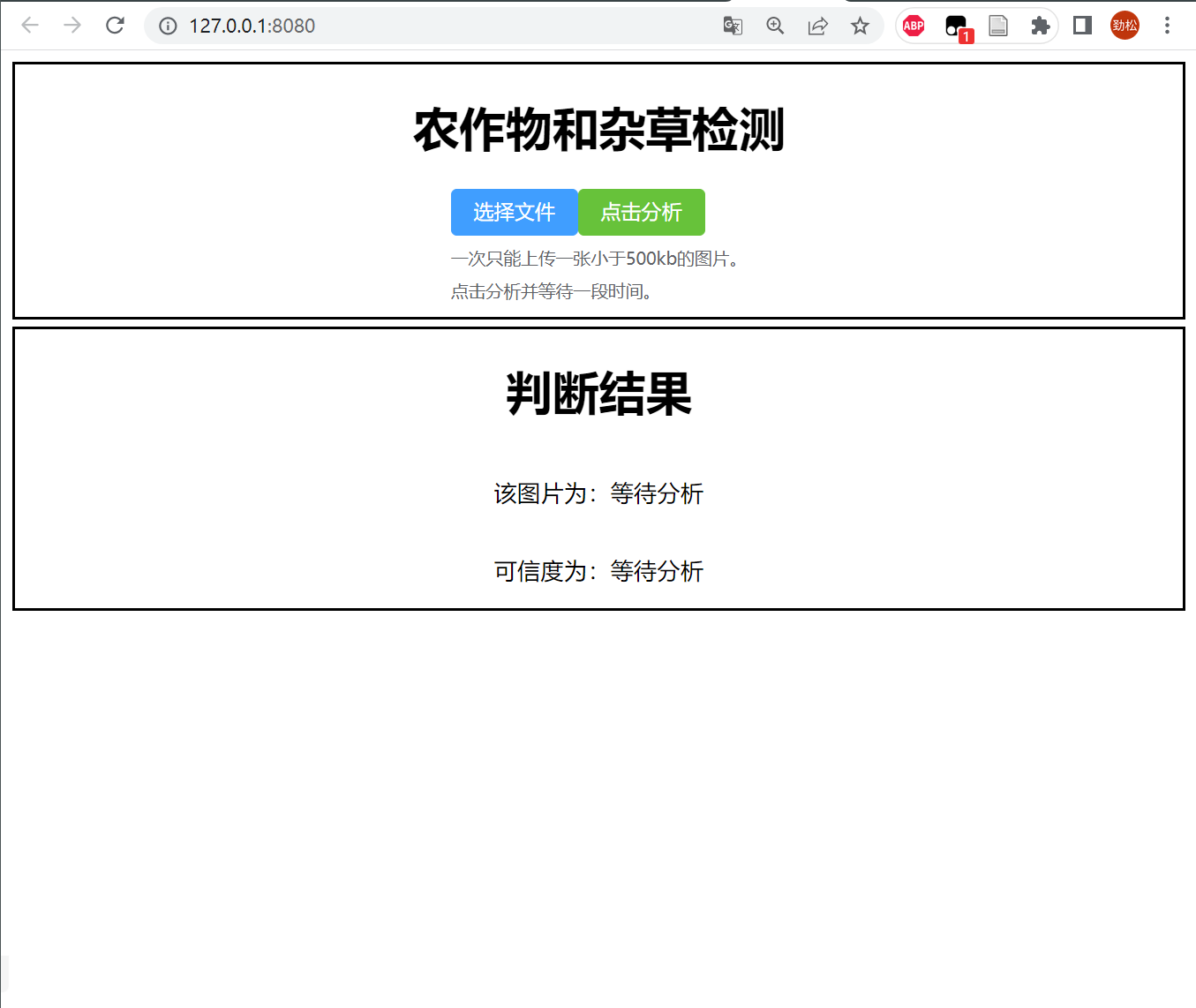
运行效果:
运行后:
部分核心代码如下:
<template><div class="content-main"><h1>Crop And Weed Detection</h1><el-uploadref="upload"class="upload-demo"action="/api/upload":on-preview="handlePreview":on-remove="handleRemove":on-exceed="handleExceed"list-type="picture":limit=1><template #trigger><el-button type="primary">select file</el-button></template><!-- <el-button type="primary">Click to upload</el-button> --><el-button type="success" :onclick="analyze">Click to Analyze</el-button><template #tip><div class="el-upload__tip">Only one image with a size less than 500kb can be uploaded at a time.</div><div class="el-upload__tip">Click to Analyze and wait for a while.</div></template></el-upload></div><div class="content-result"><div><h1>判断结果</h1></div><div><p>{{ "该图像为:" + classname }}</p></div><div><p>{{ "可信度为:" + classconf }}</p></div><el-image style="width: 600px" :src="'data:image/png;base64,'+ classurl"/></div></template><script lang="ts" setup>
import { ref } from 'vue'
import { analyzeApi } from '../api/analyzeApi';
import { genFileId } from 'element-plus'
import type { UploadInstance, UploadProps, UploadRawFile } from 'element-plus'const upload = ref<UploadInstance>()let classname = ref("Waiting Analyze");
let classconf = ref("Waiting Analyze");
let classurl = ref();const handleRemove: UploadProps['onRemove'] = (uploadFile, uploadFiles) => {console.log(uploadFile, uploadFiles)classname.value = "Waiting Analyze";classconf.value = "Waiting Analyze";classurl.value = "";}
const handleExceed: UploadProps['onExceed'] = (files) => {upload.value!.clearFiles()const file = files[0] as UploadRawFilefile.uid = genFileId()upload.value!.handleStart(file)upload.value!.submit()classname.value = "Waiting Analyze";classconf.value = "Waiting Analyze";classurl.value = "";
}
const handlePreview: UploadProps['onPreview'] = (file) => {console.log(file)
}const analyze = (): number => {analyzeApi().then(function (result) {console.log(result.data);classname.value = result.data.res_cls_name;classconf.value = result.data.res_cls_conf;classurl.value = result.data.base64_data;});return 0;
}
</script>
四、Intel oneAPI工具包使用
在算法实现过程中,我们使用到了oneAPI工具包,

英特尔相关软件具体使用如下:
- Intel Optimization for PyTorch:使用到了英特尔优化过的
PyTorch深度学习框架,以最少的代码更改应用PyTorch中尚未应用的最新性能优化,并自动混合float32和bfloat16之间的运算符数据类型精度,以减少计算工作量和模型大小。 - Interl Nerual Compressor:使用
Nerual Compressor自动执行流行的模型压缩技术,例如跨多个深度学习框架的量化、修剪和知识蒸馏。并通过自动精度驱动的调优策略快速收敛量化模型
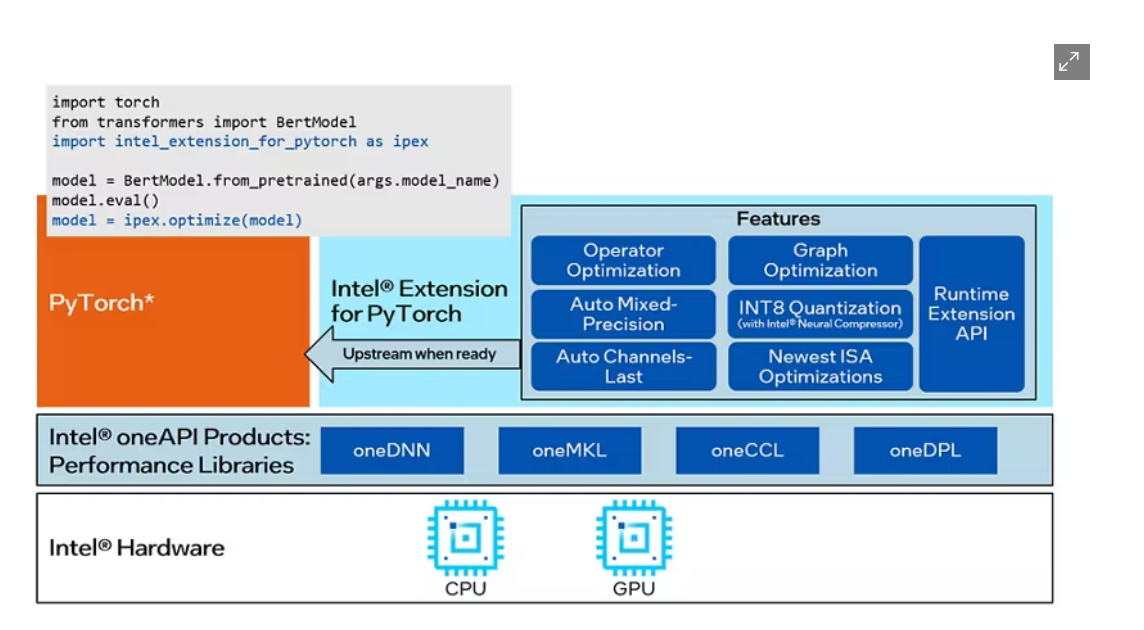
检测部分的代码如下:
import torch
import torch.nn as nn
import intel_extension_for_pytorch as ipex
import numpy as np
import cv2# 设置设备为GPU
device = torch.device("gpu")# 使用 Intel PyTorch 扩展库优化模型
ipex.enable_auto_dnnl()# 加载 YOLO 模型
model = ... # YOLO 模型的加载代码,此处省略
model = model.to(device)
model.eval()# 定义 COCO 类别标签
classes = [...] # ,此处省略# 加载图像
image_path = "test.jpg" # 替换为自己的图像路径
image = cv2.imread(image_path)# 预处理图像
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (416, 416))
image = np.transpose(image, (2, 0, 1))
image = image.astype(np.float32) / 255.0
image = torch.from_numpy(image).unsqueeze(0).to(device)# 执行目标检测
with torch.no_grad():detections = model(image)# 后处理检测结果
# 此处省略
模型优化部分代码:
from neural_compressor.experimental import Quantization
quantizer = Quantization("./conf.yaml")
quantizer.model = model
quantizer.calib_dataloader = test_loader
quantizer.eval_dataloader = test_loader
q_model = quantizer()
q_model.save('./output')
在其中,Intel PyTorch 扩展库被用于优化模型的性能,通过ipex.enable_auto_dnnl()导入 Intel PyTorch 扩展库并启用了自动 DNNL(Deep Neural Network Library)优化可以帮助我们更高效地进行深度学习模型的训练和推理,提高模型的性能和效率。 Intel Neural Compressor 被使用来对模型进行量化,减小模型的大小并提高在低功耗设备上的推理速度,同时保持相对较高的准确率
同时,也可以帮助我们减少模型的大小和计算工作量,从而更好地适应不同的硬件和场景需求。
五、后续待完善的部分
系统集成:原型中只实现了模型训练和测试的基本功能,未能实现完整的系统集成。计划通过系统集成技术,将模型集成到完整的杂草检测系统中,实现端到端的杂草检测功能。
模型优化:原型中使用的模型精度和推理速度还有提升空间。计划继续深入学习Interl Optimization for PyTorch,优化模型计算工作量和模型大小,并继续深入学习Interl Nerual Compressor提高在 CPU 或 GPU 上部署的深度学习推理的速度
这篇关于【Intel oneAPI实战】使用英特尔套件解决杂草-农作物检测分类的视觉问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




