本文主要是介绍NLP-拼写纠正,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.编辑距离
2.筛选方式
1.编辑距离
通过多少个操作才可以把写错的单词,转换成可能正确的单词。通常有3种方式:修改,添加,删除。每使用一次,则编辑距离+1。比如对于下面的therr,想变成their,则可以通过一次修改,把r修改为i,则编辑距离为1。
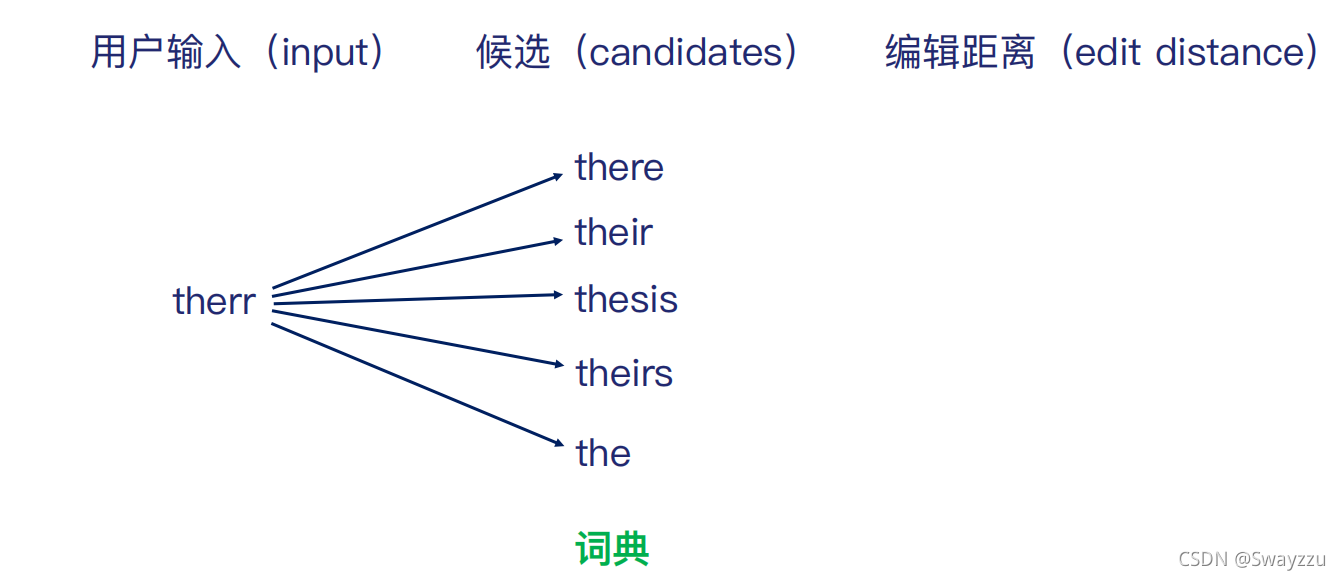
2.筛选方式
可以遍历一遍词典库里面的词去对比,但词典库内容可能很多,会增大时间复杂度,因此我们选用第二种方式:针对一个错误的输入,我们生成所有的编辑距离为1,2的字符串,之后进行过滤。

生成的字符串可能有10e4, 10e5个词,过滤方式如下:
如果要计算P(C|S),也就是给定用户输入的词,正确的词的概率,那么根据贝叶斯定理,计算P(S|C) * P(C)即可,其中S是用户输入的词,C是正确的词。
P(C)可以统计,在所有单词中,C这个词出现的概率。
P(S|C)也可以统计,统计用户输入的所有的错误的词,之后对每一个写错的单独计算即可。
最后返回概率最高的正确的词。

这篇关于NLP-拼写纠正的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





