本文主要是介绍10 | 中国大学MOOC所有课程信息爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中国大学MOOC所有课程信息爬虫
中国大学 MOOC 是网易旗下一款慕课视频教育网站。实话说,这是网易几款教育类产品中,我最喜欢的一个。
10 | 中国大学MOOC所有课程信息爬虫(课程ID、学校简称、课程名字、教师、学校全称、学生人数、学生人数、评价人数、平均评价)
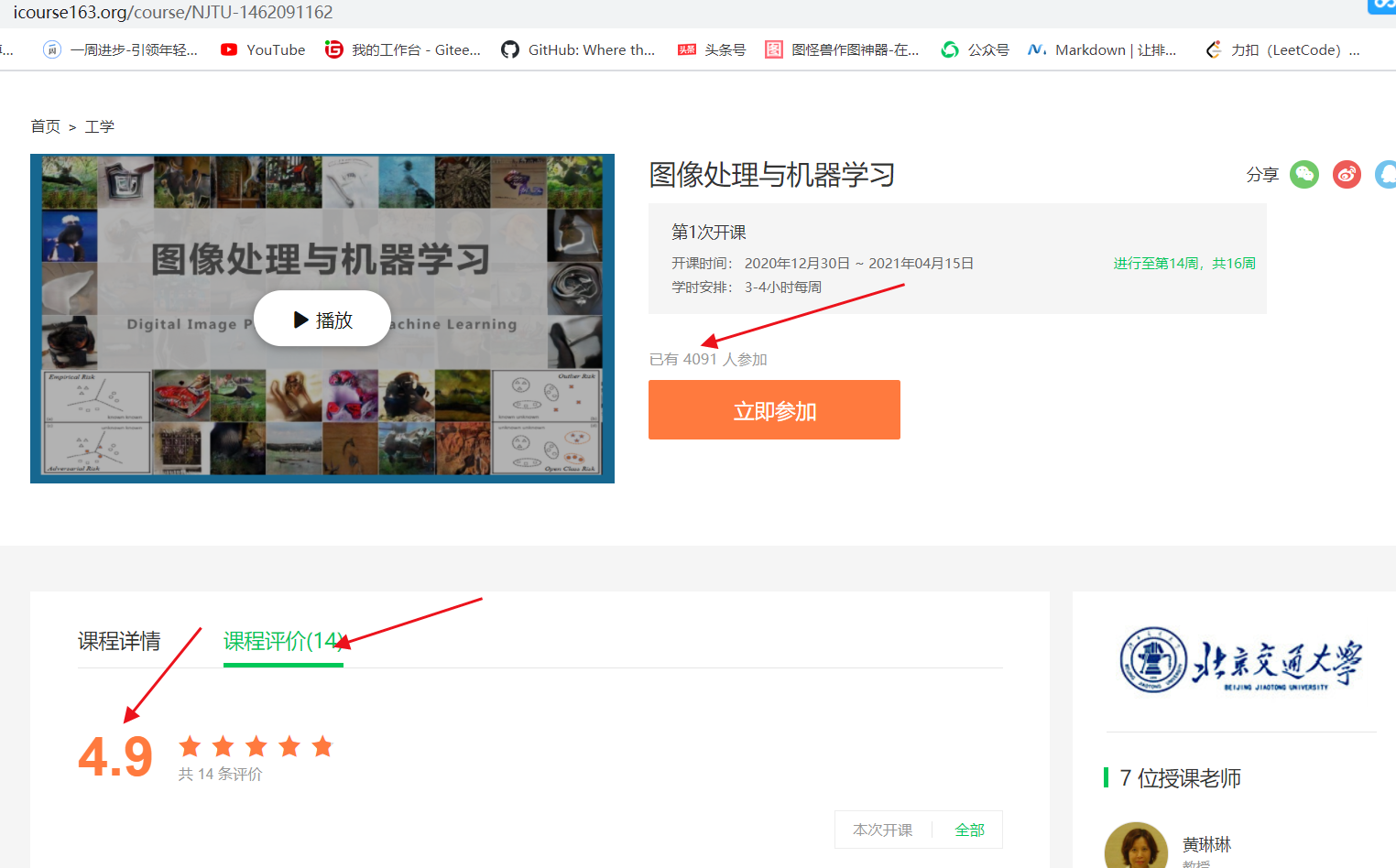
爬取成果:

这里有一个难点:就是课程评价和评分 参加人数。
很多人是用selenium处理,但是我觉得太慢了,而且没必要。
爬取思路
先爬学校
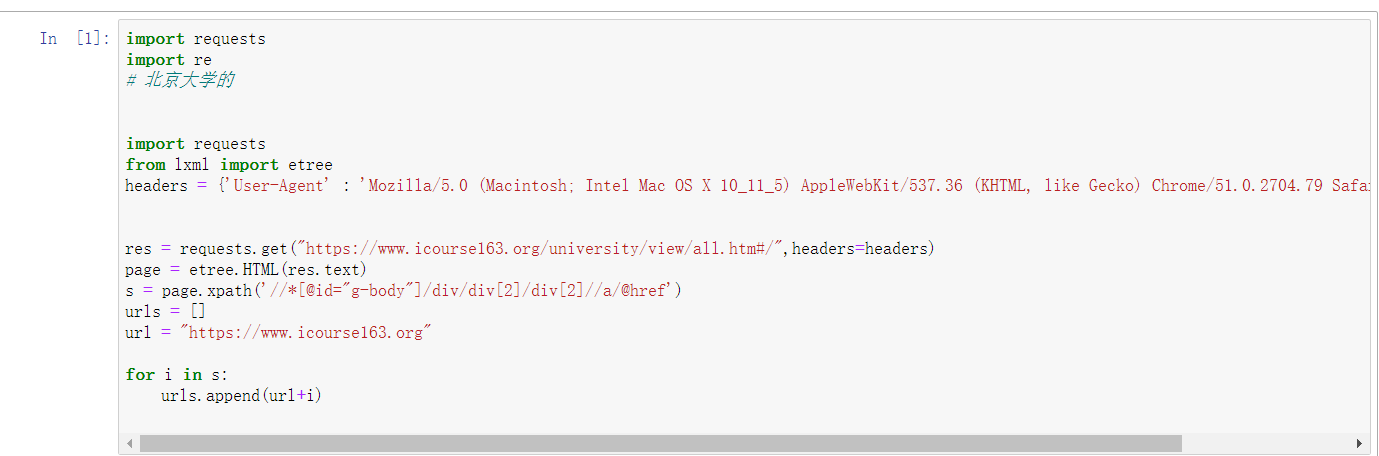
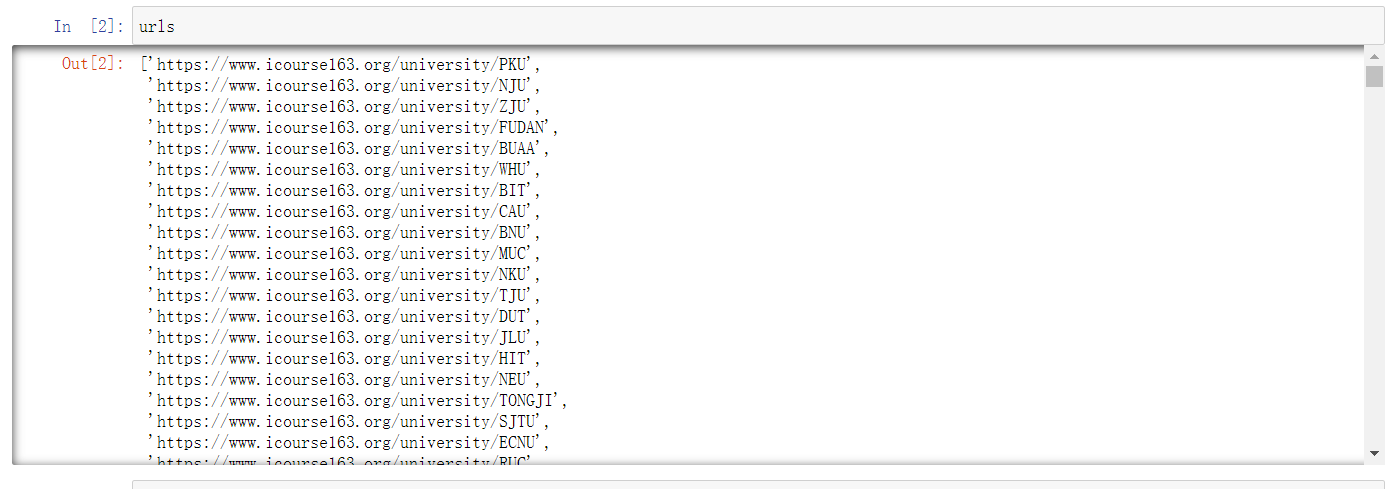
爬完学校,就进入学校课程的ID
这篇关于10 | 中国大学MOOC所有课程信息爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






