本文主要是介绍算法学习笔记:决策树(上)(decision tree):理解篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
啥是决策树?决策树是一种对样本数据进行自上而下、树形分类的模型。
一般来说,一颗决策树的组成包括:内部结点(internal node)、叶结点(leaf node)、有向边(directed edge)。

先来举个例子感性认识下决策树,来自《百面机器学习》上一对母女的对话,内容如下:
母亲:“闺女,我又给你找了个合适的对象,见不见?”
女儿:“多大?”--------------------------年龄 母亲:“26岁。”
-
女儿:“长得帅吗?”--------------------长相 母亲:“还可以,不算太帅。”
-
女儿:“工资高吗?”--------------------工资 母亲:“中等偏上。”
-
女儿:“会写代码吗?”-----------------是否会写代码 母亲:“人家是程序员,代码写得棒着呢。”
女儿问问题的过程也是她做决定的过程,可以看作一个典型的决策树分类,见或不见是通过对方的年龄、长相、工资和是否会写代码等特征或者说属性来进行逐步判断的。这颗过程可以描述成下面这样:

>>上面这个例子有其特殊性,因为从女儿的问题顺序可以对照树的结点的顺序或位置。
现在再举个更一般的例子,下面是李航的《统计学习方法》中的一组贷款申请样本数据,根据这组数据建立一颗决策树用来判断是否对申请人发放贷款,数据如下:
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
首先,我们先来观察下数据。贷款机构收集了每位申请人的4类特征或属性,分别是:
-
(1)年龄:青年、中年、老年三类,记为A1
-
(2)是否有工作:有工作和无工作两类,记为A2
-
(3)是否有房:有房和无房两类,记为A3
-
(4)信贷情况:一般、好、非常好三类,记为A4
-
现在我们并不能从这4类数据中直接看出它们在决策树上的出场顺序,或者说对于是否发放贷款的重要程度。
接下来,我们看看树的生成过程。这里先梳理一下建树的基本思路:
-
(1)第一步:选出(根)结点。在A1、A2、A3、A4中选出一个最优的作为根结点,至于怎么定义最优和怎么选,等到下面再说。假设选择了A2—是否有工作作为根结点。
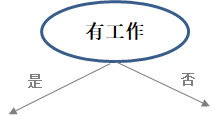
-
(2)第二步:分割数据集。样本数据集已根据A2分成了2个子数据集,如下(a)和(b)所示。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
-
(3)第三步:分别分析数据子集。分别观察下这2个子集:表(a)的类别都是“是”,也就是说,从样本数据来看有工作的申请人会被发放贷款,这时生成一个叶结点,这个树枝就生长结束了。而表(b)的类别还是混乱的,还没有被分类好,咋办?继续对(b)的数据继续进行类似(1)和(2)的选择、分解和分析。
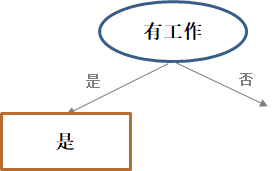
-
(4)第四步:重复(1)。在表(b)剩下的3个特征择优作为新的结点。这里假设选择了A3—是否有房作为新结点。

-
(5)第五步:重复(2)。表(b)的数据又被分为2个子集,如下表(c)和(d)所示。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
-
(6)第六步:重复(3)。此时的表(c)和(d)均已完全分类,故分别生成两个叶结点。至此决策树构建结束,完整的决策树如下所示。

再来观察下上面的这颗决策树:
①“完全正确”的决策树可能不止一个,也可能一个也没有。若把根结点“有工作”和结点“有自己的房子”调换位置,新的决策树仍然可以对这个数据集“完全正确”的分类;如果数据集中出现几个噪声,那么“完全正确”的决策树可能不存在。大部分情况下,“完全正确”意味着过拟合。所以,“最优”的决策树是那颗与训练数据矛盾较小的树并且具备不错的泛化能力。
②求解“最优”决策树的问题是一个NP-C问题(Non-deterministic Polynomial Complete)。关于啥是NPC问题详见 别人的博客(https://blog.csdn.net/sinat_21591675/article/details/86521190),这里需要理解的是这个求解最优的过程需要遍历所有的树!有必要么?回答是没有。所以一般退而求其次选择“次最优(sub-optimal)”的解,即采用所谓的启发式方法求解。
③决策树结点的选择称为“特征选择”。“特征选择”的准则有多种,包括:信息增益(infoinformation gain),也称为KL散度 (K-L divergence);信息增益比(infoinformation gain ratio);基尼指数(gini index)。详见我的另一篇文章:
最后学术性地归纳下:
- 一般来说,决策树需经过(1)特征选择、(2)树的构造、(3)树的剪枝三个过程。
- 常见决策树算法:ID3(1986年,Quinlan)、C4.5(1993年,Quinlan)、CART(1984年,Breiman)。
- 决策树是较为基础的监督学习模型,可用于分类问题(分类树)和回归(回归树)问题,在现实社会中,市场营销领域的销售问题、医疗领域的诊断问题、航空领域的故障诊断等问题使用较多。
这篇关于算法学习笔记:决策树(上)(decision tree):理解篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





