本文主要是介绍【推荐算法系列五】DeepFM 模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 参考资料
- Sparse Features
- Dense Embeddings
- FM Layer
- Hidden Layer
- Output Units
- 优缺点
- DeepFM 的优点
- DeepFM 自身的缺点。
参考资料
DeepFM 中关于 整个发展过程, FM, PNN, wide&deep 的描述很给力。
所以FM在其中的含义就是low-order, deep 就是所谓的 high-order 么?
DeepFM 是一种基于深度学习和 FM 模型的混合模型,它包含两个部分,一部分是 FM 模型,用来捕捉特征之间的交互效应;另一部分是一个深度神经网络,用来学习更高阶的特征交互和特征表达。
由于 DeepFM 算法有效地结合了 FM 和神经网络算法的优点,能够同时对低阶组合特征和高阶组合特征进行提取,因此被广泛使用。
在 DeepFM 中,FM 部分用来处理低阶特征交互,包括一阶特征和二阶特征交互。FM 模型能够捕捉到特征之间的线性关系和二次关系,对于数据稀疏的情况,FM 模型以几乎线性的时间和空间复杂度快速地学习特征交互,这对于处理高维离散特征非常有优势。
而 DNN 部分用来处理高阶特征交互,包括三阶特征和更高阶的特征交互。DNN 对输入的 Embedding 向量进行深度处理,从而能够挖掘到更为复杂的高阶交互模式。同时,DNN 可以对未知的特征进行插值和泛化,因此在数据不完整的情况下也能够保持较好的预测准确率。
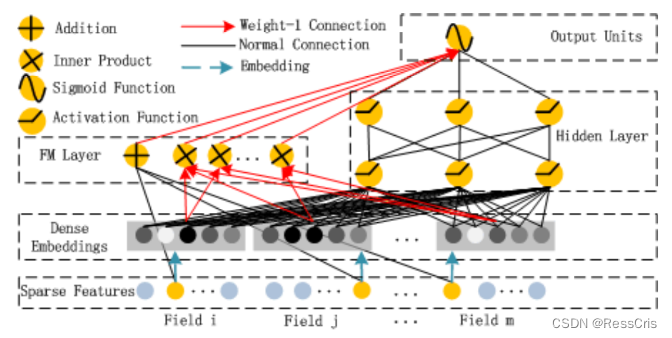
在这个模型中从下往上看,一共分成五个部分,分别是 Sparse Features、Dense Embeddings、FM Layer、Hidden Layer 以及 Output Units。
Sparse Features
这一层的主要作用是对特征进行处理。在做特征处理时,需要对每一个离散型的数据来做 One-Hot 编码。经过 One-Hot 编码后,一个特征会用很多列来表示,这时整个特征就会变得非常稀疏。因此就需要去记录 One-Hot 之前的特征(即图中的 Field),我们可以暂且理解为原始输入的特征。这样做就是为了在存储矩阵时,可以把一个大的稀疏矩阵转换成两个小的矩阵和一个字典进行存储。
Dense Embeddings
DeepFM 模型中的 Dense Embeddings 层(稠密嵌入层)用于将稀疏高维的数据压缩成稠密的实数向量表示。
我们在上一步(也就是通过 Sparse Features 层的处理后)得到的是一个高维度的稀疏向量,这个高维度的稀疏向量实际上在计算时无法得到特征之间的相互关系。那么我们就可以通过 Dense Embeddings 层,将稀疏的 01 向量做一个 Embedding,将其转化成低维稠密的向量。
根据上面的结构图可以看到,实际上每一个高维稀疏向量都有自己所对应的 Embedding 向量,不同的向量之间的 Embedding 实际上是相互独立的,我们把每一个稠密向量进行横向的拼接,使其变成一个长度很长的稠密向量,然后再拼接上原始的数值特征,统一作为 Deep 与 FM 的输入。
一般来说在 DeepFM 模型中,Sparse Features 层和 Dense Embeddings 层是紧密结合的。我们所做的就是提取稀疏特征,再划分 Field 做 Dense Embeddings,将这些原始的特征转化为低维稠密的向量,方便 input 到之后的模型中。而这些 input 共同构成了一个特征嵌入的整体,旨在为数据提供更好的特征表达能力和更强的预测性能。
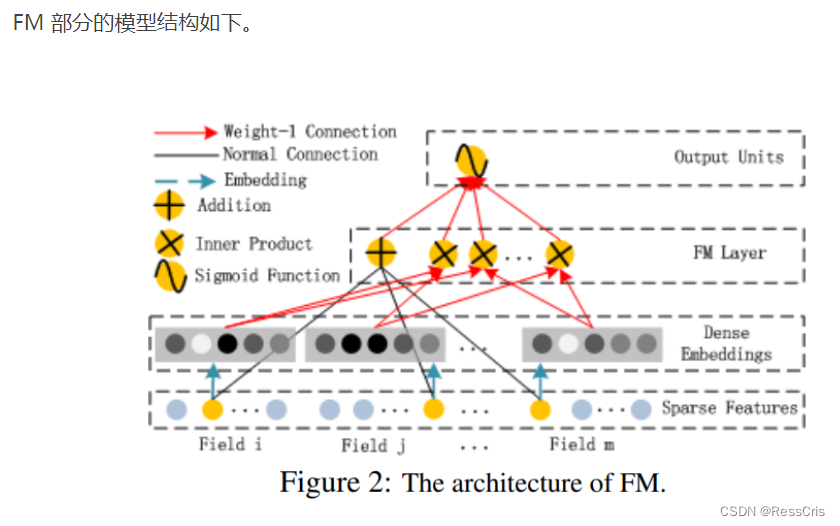
FM Layer
DeepFM 中的 FM 层由线性部分和交叉部分两部分组成。
线性部分指输入特征的线性组合,可以类比于 LR 模型的线性部分。它可以得到输入特征的权重,从而学习输入特征的重要程度。
交叉部分是指捕获二阶交互特征的部分,它会将所有特征向量的每个元素分别相乘,得到所有可能的二阶交互项,然后,对这些二阶交互项进行加权求和,得到交叉部分的输出。
值得注意的是,FM 层的线性和交叉部分可以共享特征向量的 Embedding 参数,有助于节省模型的参数量,提高模型训练效率。
Hidden Layer
Hidden Layer 是一个简单的前馈神经网络,由于原始特征向量中大多数都是高维度的稀疏向量、连续的特征和类别特征混合。为了能够更好地发挥 DNN 模型的特性,设计了一套子网络来将原始的系数特征转换成稠密的特征向量,也就是下面这张图中的部分。
Output Units
Output Units 实际上就是将 FM 的预训练向量 V 作为网络权重,初始化替换为 FM 和 DNN 进行联合训练,从而得到一个端到端的模型。在这一层中,会对 FM Layer 的结果与 Hidden Layer 的结果进行累加,这样做的好处是将低阶与高阶的特征交互融合,然后将得到的结果进行一个 sigmoid 操作,得到预测的概率输出。
优缺点
DeepFM 的优点
- 考虑了高阶交叉特征:DeepFM 可以对各种交叉特征进行编码,包括高阶交叉特征,从而提高了模型的表达能力。
- 既考虑了线性特征又考虑了非线性特征:DeepFM 同时考虑了线性模型和因子分解机模型,可以对线性特征和非线性特征进行学习和推断。
- 适用于稀疏特征:DeepFM 可以处理具有稀疏结构的特征,例如在推荐系统中常见的用户 - 物品交互。
- 可以通过高效的 Embedding 实现对离散特征的编码:DeepFM 基于 Embedding 层实现了对离散特征的编码,这种方法可以高效地处理海量的离散特征。
DeepFM 自身的缺点。
- 模型训练较慢:DeepFM 中的深度模块导致了训练过程的时间和计算复杂度的增加。
- 特征选取和处理的要求较高:DeepFM 需要对原始数据进行一定的预处理,同时对于不同的数据集,需要结合实际场景设计合适的特征。
- 对于连续特征的处理较为有限:DeepFM 采用了 Embedding 层来处理离散特征,虽然它也支持连续特征,但是处理连续特征的方法较为简单并且直接。
这篇关于【推荐算法系列五】DeepFM 模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




