本文主要是介绍测试一波回归模型的误差,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何衡量一个线性回归模型准确性
上一篇文章讲了怎么使用线性回归来预测,但是没有对这个模型的性能和准确性进行有效评估。
一般来讲,误差越小,预测就越准确。但是如果误差过于小,也要考虑是否过度拟合。
下面几个指标是用来衡量一个模型的误差大小:
-
平均绝对误差(Mean Absolute Error,简称MAE)
-
它的数学公式是:

scikit-learn里对应的函数如下:
mean_absolute_error(y_true, y_pred)其中y_true是真实的目标值,y_pred是预测目标值。MAE越小,说明模型的预测能力越好。
-
均方误差(Mean Squared Error,简称MSE)
-
它的数学公式是:

mean_squared_error(y_true, y_pred)MSE越小,表示模型的预测值与实际观测值之间的差异较小,即模型具有较高的预测精度。
-
均方对数误差(Mean Squared Log Error,简称MSLE):
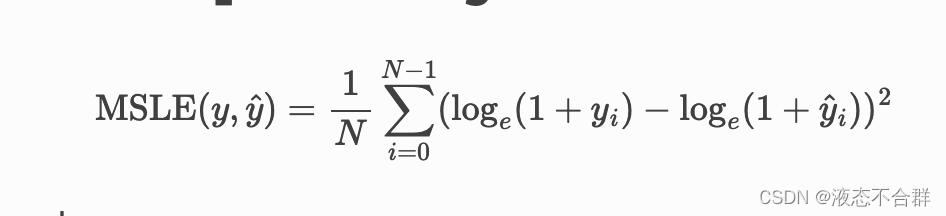
mean_squared_log_error(y_true, y_pred)MSLE的值越小,表示预测结果与真实值的差异越小,即模型的拟合程度越好。
-
绝对误差中值(Median Absolute Error,简称MedAE):

median_absolute_error(y_true, y_pred)
MedAE越小的模型,通常意味着它在大多数数据点上的预测更为准确。
实际使用中我用得最多的是MSE和MEdAE以及r2 score(它用来描述自变量和因变量的关联性,通常值为0-1之间),具体代码如下所示:
import sklearn.metrics as metrics
import numpy as np# Sample data
X = np.array([[1], [2], [3], [4], [5]]) # Input feature
y = np.array([2, 3.5, 2.8, 4.6, 5.2]) # Output target# Create a linear regression model
model = LinearRegression()# Fit the model to the data
model.fit(X, y)# Make predictions
X_new = np.array([[6], [7]]) # New data for prediction
y_pred = model.predict(X_new)print("Predictions:", y_pred)mse = metrics.mean_squared_error(y, y_pred)
r2 = metrics.r2_score(y, y_pred)
m_error = metrics.median_absolute_error(y, y_pred)print('MSE is {}'.format(mse))
print('R2 is {}'.format(r2))
print('M_ERROR is {}'.format(m_error))文章转载自:freephp
原文链接:https://www.cnblogs.com/freephp/p/18035887
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
这篇关于测试一波回归模型的误差的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








