本文主要是介绍【AI+医疗】— MobileNetV3实现皮肤癌检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
1. 前言
1.1 “AI+医疗” 助力健康中国建设
人工智能构建智慧医疗体系,推进医药卫生体制改革。

-
自从有了人类就有了生老病死,也伴随着开始有了医学的产生与发展。中国的中医学起源于三皇五帝时期,相传伏羲发明了针灸并尝试草药,神农炎帝更是尝尽百草,并且用茶来解毒。在公元前3000多年,中国的轩辕黄帝写下了人类第一部医学著作——《黄帝祝由科》,后世人在这部医药著作的基础上不断增补删改,逐渐形成了后来的《黄帝内经》和《黄帝外经》,并形成了后来的中医学。在周代中国就建立了世界上第一个医院和医疗制度,周代的医疗机构设有医师、和管药库的府、管记录的史、及徒等职位。下面又分为内科、外科、兽医等科室,这是世界上已知最早的医学分科。古书中有记载“死终则各书其所以,而入于医师”,规定在死者病历上要写明死因,然后送交医师存档,以便总结医疗经验,提高医疗技术。这也是世界上已知最早的病历制度。
-
而对于现代生活来说,医疗服务质量的好坏会直接影响居民的生活幸福指数。改革开放以来,随着经济的不断发展,各级政府都在持续加大对医疗软硬件基础设施的投入,我们的就医体验也有了明显的改善和提升。但是由于我国人口基数大、医疗资源分配不够均衡、医疗资源两极化,导致大医院人满为患,社区医院无人问津,且病人在就诊过程中存在手续繁琐等等医疗信息不通畅问题。同时现在老年人口占比超过18%,这就意味着给社会的医疗体系带来更大的压力。而智能医疗则可以通过打造健康档案区域医疗信息平台,利用最先进的物联网技术,实现患者与医务人员、医疗机构、医疗设备之间的互动,逐步达到构建智慧医疗体系,推进医药卫生体制改革的目的。尤其在新型冠状肺炎病毒传播期间,各种信息和通信技术融入传统医疗场景,赋能医疗机构和医护人员,为我们战胜疫情提供了巨大的帮助。因此我们需要运用人工智能技术来建立一套智慧的医疗信息网络平台体系,使患者用较短的等疗时间,就可以享受安全、便利、优质的诊疗服务。此外,智慧医疗还可以降低医务工作人员的工作负荷,提升医疗效率;普及医疗健康知识,提高国民身体健康素质;加强医疗资源共享,降低社会医疗成本等。
1.2 项目背景
基于飞桨PaddleX的MobileNetV3_large模型实现皮肤癌检测
- 随着社会的发展和人们生活水平的提高,人们对医疗健康的需求也越来越高。皮肤癌是全球范围内常见的恶性肿瘤之一,其发病率逐年上升。及早发现和诊断皮肤癌可以显著提高治愈率和生存率。因此,开发一种高效、准确、便捷的皮肤癌检测方法具有重要意义。
-
在皮肤癌检测中,图像分类是一种重要的方法。图像分类是将输入的图像划分到不同的预定义类别中,以实现对皮肤癌的自动检测和诊断。近年来,深度学习技术在图像分类领域取得了显著的成果。特别是基于卷积神经网络(CNN)的模型,如VGG、ResNet、Inception等,在ImageNet图像识别挑战赛中不断刷新记录。这些模型在图像分类任务中表现优异,为皮肤癌检测提供了新的解决方案。
-
然而,在实际应用中,由于医疗数据的特殊性,如何保证模型在医疗领域的准确性和安全性至关重要。飞桨PaddleX作为百度飞桨的组成部分,提供了完整的AI开发能力,包括数据处理、模型构建、模型训练、模型评估和推理等。同时,飞桨PaddleX还支持多种模型压缩工具,如剪枝、量化、混合精度等,可以帮助用户在保证模型性能的同时,降低模型体积和资源消耗,实现真正意义上的高效、便捷、安全。
-
本文旨在介绍基于飞桨PaddleX的MobileNetV3_large模型在皮肤癌检测中的应用。MobileNetV3_large是一种轻量级神经网络模型,具有结构简单、参数少、计算量小等特点。适合于在资源受限的移动设备上运行,可实现实时皮肤癌检测。本文将详细介绍项目背景、MobileNetV3_large模型原理、皮肤癌检测数据集和处理方法、模型训练和优化过程以及实验结果分析等内容。
-
随着科技的发展,深度学习技术已经在医疗领域取得了显著的成果。皮肤癌检测作为其中的一个重要应用方向,具有广泛的研究价值。本文旨在利用深度学习技术,基于飞桨PaddleX的MobileNetV3_large模型实现皮肤癌检测,以达到高效、准确、便捷的目的。
1.3 数据集介绍
源数据获取自Kaggle,数据优化后在AI Studio开源
-
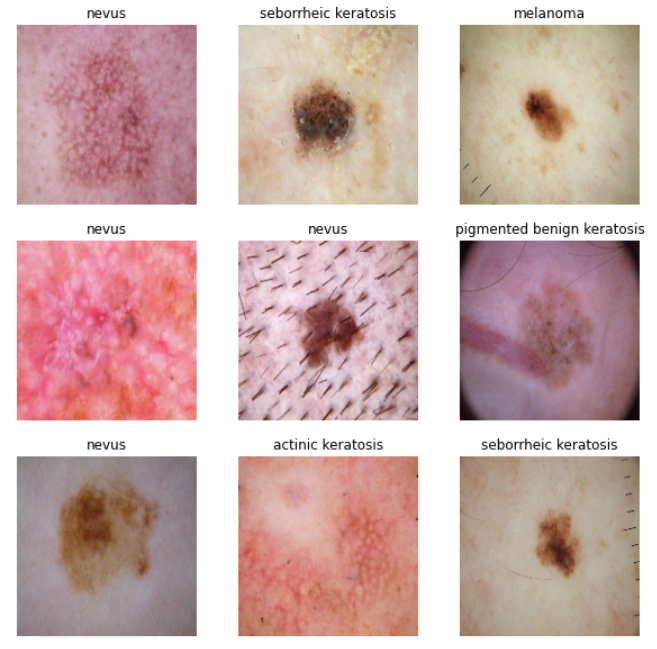
皮肤疾病是一种常见的临床问题,对患者的生活质量和健康状况造成很大的影响。因此,对皮肤疾病的研究和治疗一直备受关注。在皮肤疾病中,痣、黑色素瘤、鳞状细胞癌、血管病变、脂溢性角化病、色素性良性角化病、皮肤纤维瘤、基底细胞癌和光化性角化病等是常见的类型。
-
Nevus是一种常见的皮肤疾病,通常是无害的,但有些情况下可能是黑色素瘤的前兆。Melanoma是一种恶性肿瘤,通常由痣恶变而来,早期诊断和切除是关键。Squamous Cell Carcinoma是一种常见的皮肤癌,通常由长期暴露于紫外线引起。Vascular Lesion是一种血管病变,通常不影响健康,但有些情况下可能是恶性病变。Seborrheic Keratosis是一种常见的皮肤病,通常在老年人中发生,常常被误认为是黑色素瘤。 Pigmented Benign Keratosis是一种色素性良性角化病,通常是无害的,但有些情况下可能会影响美观。Dermatofibroma是一种皮肤纤维瘤,通常是无害的,但有些情况下可能会影响美观。Basal Cell Carcinoma是一种常见的皮肤癌,通常由痣恶变而来,早期诊断和切除是关键。Actinic Keratosis是一种光化性角化病,通常由长期暴露于紫外线引起,早期诊断和切除是关键。
-
在本数据集中,我们涵盖了上述所有的皮肤疾病类型,旨在提供一个全面的数据集,帮助开发更加准确的皮肤疾病诊断和治疗算法。我们使用了高质量的图像数据和精确的标注,以确保数据的准确性和可靠性。我们相信,本数据集将对皮肤疾病的研究和治疗产生积极的影响,为未来的研究提供有价值的资源。
| English | 中文名 |
|---|---|
| nevus | 痣 |
| melanoma | 黑色素瘤 |
| squamous_cell_carcinoma | 鳞状细胞癌 |
| vascular_lesion | 血管病变 |
| seborrheic_keratosis | 脂溢性角化病 |
| pigmented_benign_keratosis | 色素性良性角化病 |
| dermatofibroma | 皮肤纤维瘤 |
| basal_cell_carcinoma | 基底细胞癌 |
| actinic_keratosis | 光化性角化病 |
2. 实现步骤
2.1 环境配置 & 解压数据集
! pip install "paddlex==1.3.10" -i https://mirror.baidu.com/pypi/simple #安装PaddleX
!unzip data/data225795/skin-cancer-detection.zip #解压数据集
!mkdir datasets #创建datases目录
!mv 'skin-cancer-detection' datasets/skin #将数据集移动到datasets目录,并重命名为skin
#将预处理数据移动到skin目录
!mv datasets/skin/labels.txt datasets/skin
!mv datasets/skin/train_list.txt datasets/skin
!mv datasets/skin/val_list.txt datasets/skin
2.2 数据预处理(不用运行)我已经做好啦!仅供参考
#labels
import os
import glob
%cd /home/aistudio/datasets/skin/
# !touch label.txt
# # 目录路径
directory = '/home/aistudio/datasets/skin/Train'
# 遍历目录,获取所有文件路径
files = glob.glob(os.path.join(directory, '*')) # 打开label.txt文件,并写入文件路径和标签
with open('labels.txt', 'w') as f: for file in files: #提取文件名filename = os.path.basename(file) label = '' # 文件的标签,可以根据需要进行更改 f.write(f'{filename}\n') #\n表示换行print("over")
#train_list
import os
import glob
%cd /home/aistudio/datasets/skin/Train/
# # 目录路径
directory = '/home/aistudio/datasets/skin/Train/nevus/' #记得修改路径根据label.txt的顺序来
# 遍历目录,获取所有文件路径
files = glob.glob(os.path.join(directory, '*'))
# 打开train.txt文件,并写入文件路径和标签
with open('train_list.txt', 'w') as f: #'a' #注意:从第二次开始,这里'w'改为'a',不然会覆盖源文件for file in files: #提取文件名label = '0' # 文件的标签,可以根据需要进行更改 #label=0、1、2、3、4、5、6、7、8(根据label.txt的顺序来)f.write(f'{file} {label}\n') #\n表示换行print("over")
#eval_list
import os
import glob
%cd /home/aistudio/datasets/skin/Test/
# # 目录路径
directory = '/home/aistudio/datasets/skin/Test/nevus/' #记得修改路径根据label.txt的顺序来
# 遍历目录,获取所有文件路径
files = glob.glob(os.path.join(directory, '*'))
# 打开train.txt文件,并写入文件路径和标签
with open('eval_list.txt', 'w') as f: #'a' #注意:从第二次开始,这里'w'改为'a',不然会覆盖源文件for file in files: #提取文件名label = '0' # 文件的标签,可以根据需要进行更改 #label=0、1、2、3、4、5、6、7、8(根据label.txt的顺序来)f.write(f'{file} {label}\n') #\n表示换行print("over")
#移动到skin目录
%cd ~
!mv datasets/skin/Train/train_list.txt datasets/skin
!mv datasets/skin/Test/eval_list.txt datasets/skin
2.3 模型训练
配置GPU
import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
定义图像处理流程transforms
定义数据处理流程,其中训练和测试需分别定义,训练过程包括了部分测试过程中不需要的数据增强操作,如在本示例中,训练过程使用了RandomCrop和RandomHorizontalFlip两种数据增强方式,更多图像预处理流程transforms的使用可参见paddlex.cls.transforms。
from paddlex.cls import transforms
train_transforms = transforms.Compose([transforms.RandomCrop(crop_size=224),transforms.RandomHorizontalFlip(),transforms.Normalize()
])
eval_transforms = transforms.Compose([transforms.ResizeByShort(short_size=256),transforms.CenterCrop(crop_size=224),transforms.Normalize()
])
定义数据集
分类使用ImageNet格式的数据集,因此采用pdx.datasets.ImageNet来加载数据集,该接口的介绍可参见文档paddlex.datasets.ImageNet。
#将标注文件移动到skin目录
%cd ~
!mv train_list.txt datasets/skin
!mv val_list.txt datasets/skin
!mv labels.txt datasets/skin
train_dataset = pdx.datasets.ImageNet(data_dir='datasets/skin',file_list='datasets/skin/train_list.txt',label_list='datasets/skin/labels.txt',transforms=train_transforms,shuffle=True)
eval_dataset = pdx.datasets.ImageNet(data_dir='datasets/skin',file_list='datasets/skin/val_list.txt',label_list='datasets/skin/labels.txt',transforms=eval_transforms)
模型训练
使用本数据集在P40上训练。
更多训练模型的参数可参见文档paddlex.cls.MobileNetV3。
模型训练过程每间隔save_interval_epochs轮会保存一次模型在save_dir目录下,同时在保存的过程中也会在验证数据集上计算相关指标,具体相关日志参见文档。
AIStudio使用VisualDL查看训练过程中的指标变化
- 点击左边菜单图标的『可视化』;
- 设置logdir,logdir的路径为训练代码中
save_dir指定的目录下的vdl_log目录,例如output/mobilenetv3/vdl_log - 点击下方『启动VisualDL服务按钮』,再『打开VisualDL』即可
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_large(num_classes=num_classes)
model.train(num_epochs=20,train_dataset=train_dataset,train_batch_size=64,eval_dataset=eval_dataset,lr_decay_epochs=[20, 20, 20],save_interval_epochs=1,learning_rate=0.005,save_dir='output/mobilenetv3',use_vdl=True)
2.4 模型预测
我主要使用了PaddleX库和Matplotlib库。具体地,首先通过pdx.load_model函数加载训练好的模型文件,并指定要预测的图片文件名。然后,通过model.predict函数对图片进行预测,得到预测结果。接着,使用OpenCV库读取原始图片,并通过cv2.cvtColor函数将BGR格式的图片转换为RGB格式。最后,使用Matplotlib库的plt.imshow函数和plt.show函数显示原始图片和预测结果。
%matplotlib inline
import paddlex as pdx
import matplotlib.pyplot as plt
import numpy as np
import cv2
model = pdx.load_model('output/mobilenetv3/best_model')
image_name = 'nevus.jpg'
result = model.predict(image_name)
print("Predict Result:", result)
origin_pic = cv2.imread('nevus.jpg')
origin_pic = cv2.cvtColor(origin_pic, cv2.COLOR_BGR2RGB)
plt.imshow(origin_pic)
plt.axis('on') # 显示坐标轴
print(result)
plt.show()
rigin_pic, cv2.COLOR_BGR2RGB)
plt.imshow(origin_pic)
plt.axis('on') # 显示坐标轴
print(result)
plt.show()2023-06-25 09:04:19 [INFO] Model[MobileNetV3_large] loaded.
Predict Result: [{'category_id': 0, 'category': 'nevus', 'score': 0.83332306}]
[{'category_id': 0, 'category': 'nevus', 'score': 0.83332306}]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QXAgqvSY-1688106547455)(output_29_1.png)]
可以看到模型的效果还是不错的,能够达到83%的置信度
3. 总结
3.1 作者:徐嘉祁 飞桨开发者技术专家 飞桨领航团团长
3.2 为什么要使用 MobileNetV3?
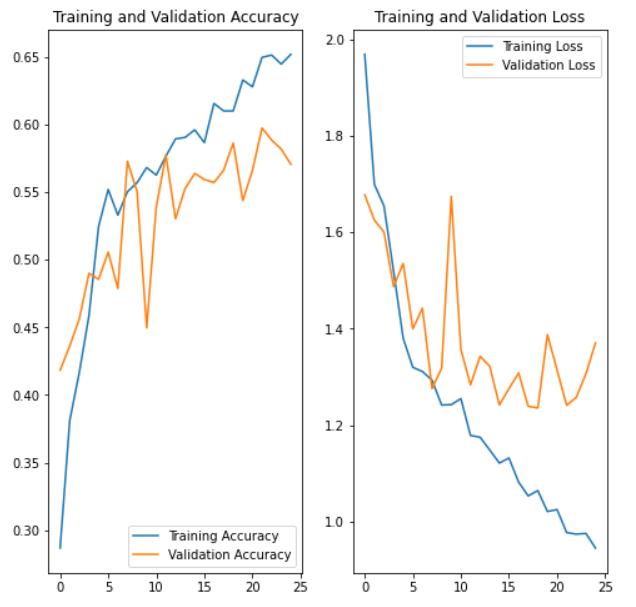
3.2.1 为什么不使用CNN?
在这个项目中,我想大多数人一开始更我一样想要用更加简单的网络(CNN)来解决这个问题,但是CNN网络仍然存在很多不足。下图是使用CNN网络模型准确率和Loss在训练集和测试集上的表现。
3.2.2 MobileNetV3网络的优势
MobileNetV3_large网络是一个轻量级深度学习模型,适合于在资源受限的移动设备上进行皮肤癌检测。以下是使用该网络的优势和特点:
- 轻量级:MobileNetV3_large网络具有较小的参数数量和计算量,可以在低功耗设备上运行。
- 高性能:该网络具有较高的分类精度和推理速度,可以快速准确地检测皮肤癌。
- 加速推理:MobileNetV3_large网络使用了深度可分离卷积技术,可以加速推理过程,提高模型性能。
- 适用于移动设备:该网络适合在移动设备上进行皮肤癌检测,可以方便地集成到移动应用中。
- 综上所述,使用MobileNetV3_large网络进行皮肤癌检测具有许多优势,可以提供高效、准确和轻量级的解决方案。
该皮肤疾病分类项目具有重要的意义和价值。首先,通过对皮肤疾病的研究和诊断,可以有效地提高人们的健康水平和生活质量。其次,该项目可以提供给皮肤科医生、病理学家等相关人员一个全面的数据集,帮助他们更好地理解和识别不同的皮肤疾病类型。最后,该项目还可以为人工智能和机器学习领域的发展提供重要的数据支持和参考价值。
点赞加关注 找我不迷路 ❤~
此文章为搬运
原项目链接
这篇关于【AI+医疗】— MobileNetV3实现皮肤癌检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







