本文主要是介绍CoreData数据持久化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CoreData介绍
CoreData是一门功能强大的数据持久化技术,位于SQLite数据库之上,它避免了SQL的复杂性,能让我们以更自然的方式与数据库进行交互。CoreData提供数据–OC对象映射关系来实现数据与对象管理,这样无需任何SQL语句就能操作他们。
CoreData数据持久化框架是Cocoa API的一部分,⾸次在iOS5 版本的系统中出现,它允许按照实体-属性-值模型组织数据,并以XML、⼆进制文件或者SQLite数据⽂件的格式持久化数据
CoreData与SQLite进行对比
SQLite
1、基于C接口,需要使用SQL语句,代码繁琐
2、在处理大量数据时,表关系更直观
3、在OC中不是可视化,不易理解
CoreData
1、可视化,且具有undo/redo能力
2、可以实现多种文件格式:* NSSQLiteStoreType* NSBinaryStoreType* NSInMemoryStoreType* NSXMLStoreTyp
3、苹果官方API支持,与iOS结合更紧密
CoreData核心类与结构
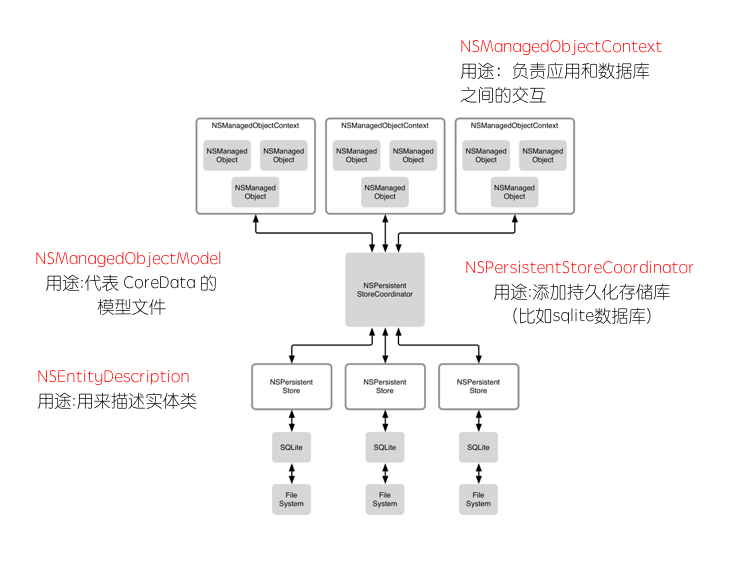
NSManagedObjectContext(数据上下文)
- 对象管理上下文,负责数据的实际操作(重要)
- 作用:插入数据,查询数据,删除数据,更新数据
NSPersistentStoreCoordinator(持久化存储助理)
- 相当于数据库的连接器
- 作用:设置数据存储的名字,位置,存储方式,和存储时机
NSManagedObjectModel(数据模型)
- 数据库所有表格或数据结构,包含各实体的定义信息
- 作用:添加实体的属性,建立属性之间的关系
- 操作方法:视图编辑器,或代码
NSManagedObject(被管理的数据记录)
- 数据库中的表格记录
NSEntityDescription(实体结构)
- 相当于表格结构
NSFetchRequest(数据请求)
- 相当于查询语句
后缀为.xcdatamodeld的包
- 里面是.xcdatamodel文件,用数据模型编辑器编辑
- 编译后为.momd或.mom文件
各类之间关系图
CoreData数据库 手动创建
创建步骤如下
1.创建模型文件 [相当于一个数据库]
2.添加实体 [一张表]
3.创建实体类 [相当模型--表结构]
4.生成上下文 关联模型文件生成数据库
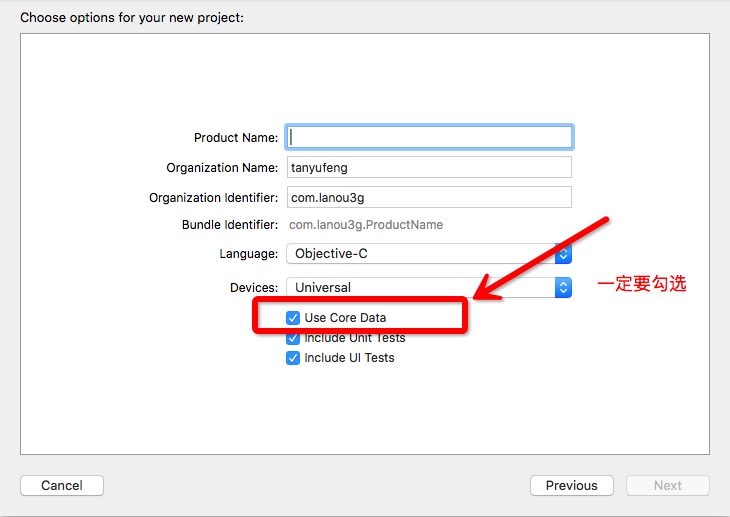
0、创建工程
1、手动创建CoreData数据时,我们创建一个和平常一样的工程,不需要勾选Use Core Data:
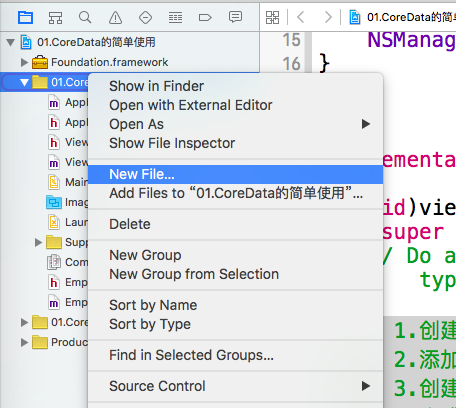
1、创建模型文件
1、进入创建新文件,command+N或者如下图
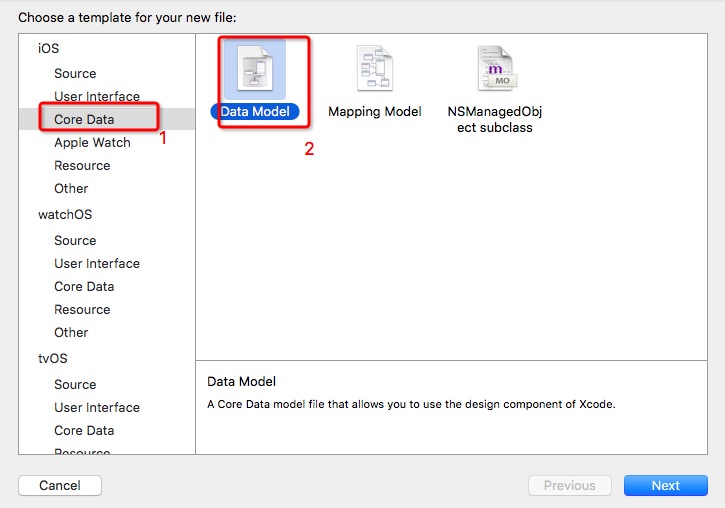
2、选择模型文件类型, 如下图:
3、设置文件名,如下图:
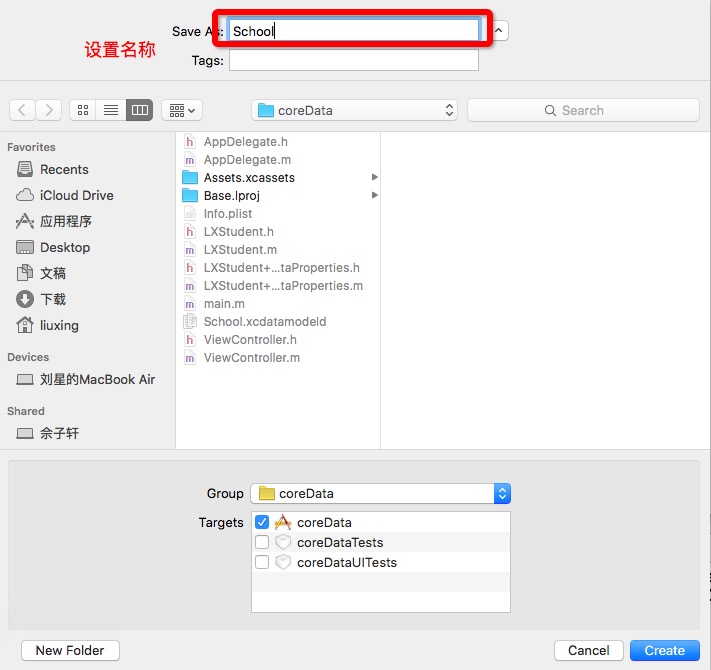
4、模型文件创建成功,会出现以后
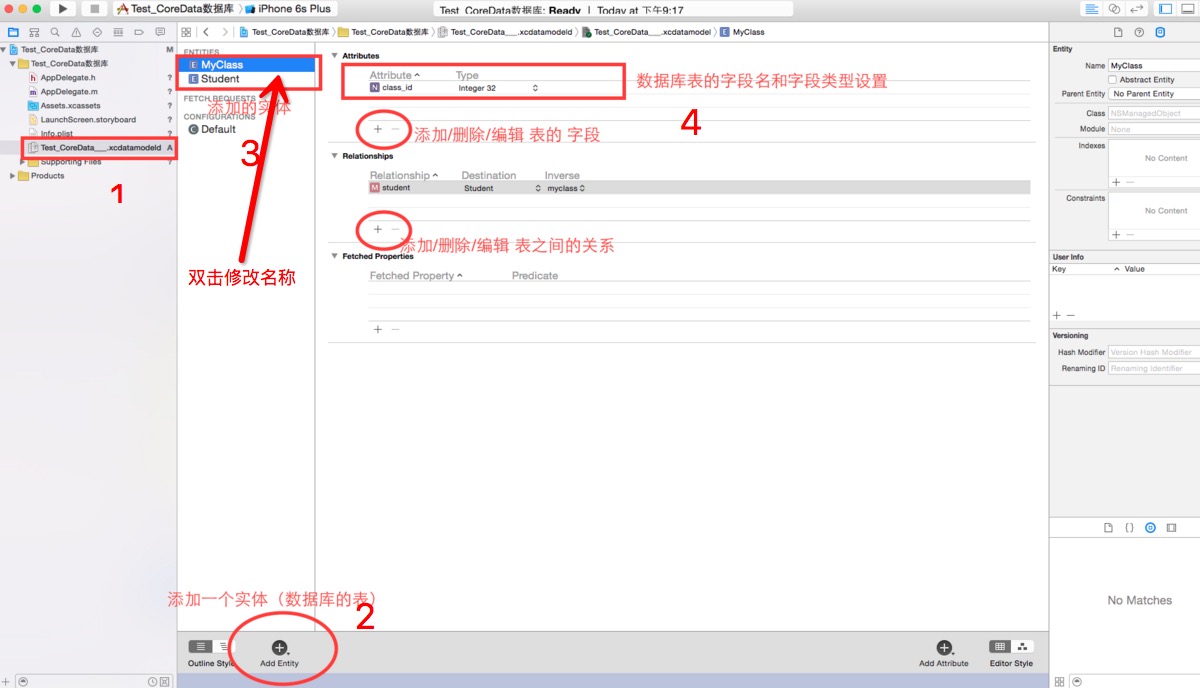
2、创建实体
1、利用可视化的方式创建实体,实体的功能就类似于我们的Model类,具体操作如下如:
3、创建实体类
利用可视化创建了实体,但是我们要想获取对应的数据和名称,就必须关联类,因此要创建实体类,创建步骤如下:
1、进入创建新文件
2、选择文件类型, 实体类文件类型选择:NSManagedObject subclass
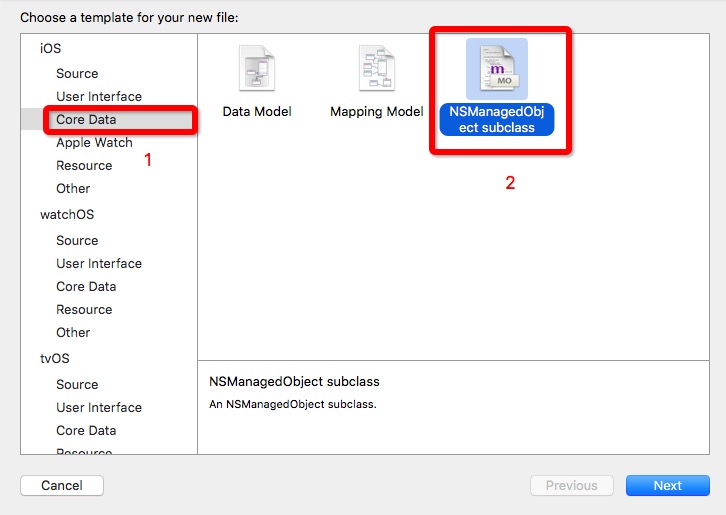
3、选择模型文件

4、选择实体
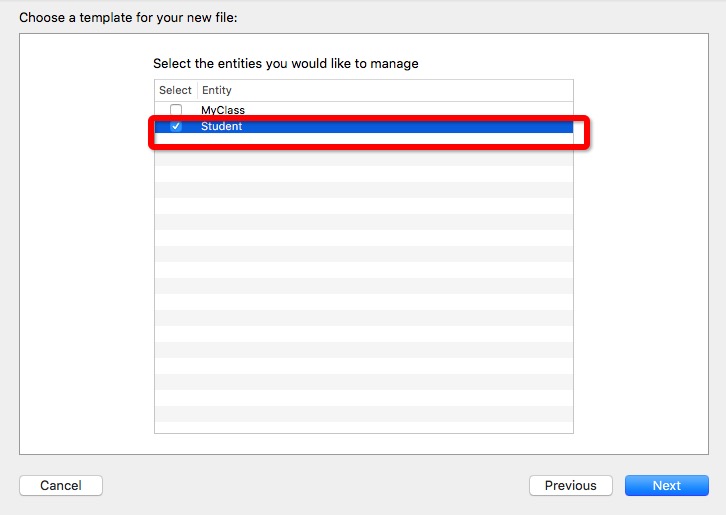
5、创建成功
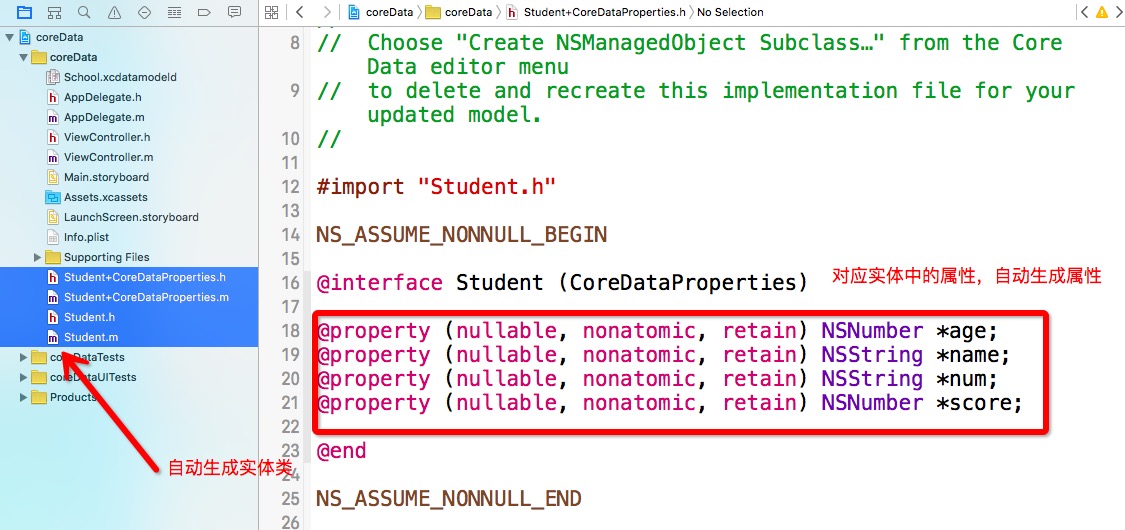
实体文件创建成功后系统自动帮我们生成对应的类和属性,类名对应实体名称, 属性对应实体中的属性名称;如果我们的属性是基本数据类型,那么默认会帮我们转换成NSNumber类型的属性.
* 老版本:只生成一对文件,即类和属性都在一起
* 新版本:生成一对类文件,再生成一对类目,在类目中生成属性
4、生成上下文 关联数据库
在创建上下文和关联数据库之前我们先来看看想对应的关系依赖图:
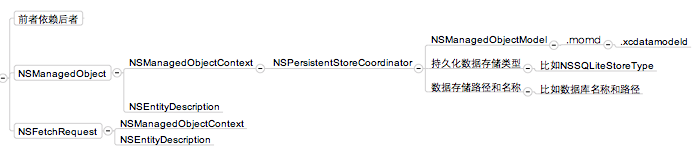
从上图我们看到,要想生成上下文,需要有数据库助理和模型的支持;就像SQLite中一样,想要操作数据库,你必须要有数据库,并且创建好表;我们来看实现代码:
<code class="hljs objectivec has-numbering">- (<span class="hljs-keyword">void</span>)viewDidLoad {[<span class="hljs-keyword">super</span> viewDidLoad];<span class="hljs-comment">//1、创建模型对象</span><span class="hljs-comment">//获取模型路径</span><span class="hljs-built_in">NSURL</span> *modelURL = [[<span class="hljs-built_in">NSBundle</span> mainBundle] URLForResource:@<span class="hljs-string">"School"</span> withExtension:@<span class="hljs-string">"momd"</span>];<span class="hljs-comment">//根据模型文件创建模型对象</span>NSManagedObjectModel *model = [[NSManagedObjectModel alloc] initWithContentsOfURL:modelURL];<span class="hljs-comment">//2、创建持久化助理</span><span class="hljs-comment">//利用模型对象创建助理对象</span>NSPersistentStoreCoordinator *store = [[NSPersistentStoreCoordinator alloc] initWithManagedObjectModel:model];<span class="hljs-comment">//数据库的名称和路径</span><span class="hljs-built_in">NSString</span> *docStr = [NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, <span class="hljs-literal">YES</span>) lastObject];<span class="hljs-built_in">NSString</span> *sqlPath = [docStr stringByAppendingPathComponent:@<span class="hljs-string">"mySqlite.sqlite"</span>];<span class="hljs-built_in">NSLog</span>(@<span class="hljs-string">"path = %@"</span>, sqlPath);<span class="hljs-built_in">NSURL</span> *sqlUrl = [<span class="hljs-built_in">NSURL</span> fileURLWithPath:sqlPath];<span class="hljs-comment">//设置数据库相关信息</span>[store addPersistentStoreWithType:NSSQLiteStoreType configuration:<span class="hljs-literal">nil</span> URL:sqlUrl options:<span class="hljs-literal">nil</span> error:<span class="hljs-literal">nil</span>];<span class="hljs-comment">//3、创建上下文</span>NSManagedObjectContext *context = [[NSManagedObjectContext alloc] initWithConcurrencyType:NSMainQueueConcurrencyType];<span class="hljs-comment">//关联持久化助理</span>[context setPersistentStoreCoordinator:store];_context = context;}
</code><ul style="" class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li><li>18</li><li>19</li><li>20</li><li>21</li><li>22</li><li>23</li><li>24</li><li>25</li><li>26</li><li>27</li><li>28</li><li>29</li><li>30</li><li>31</li><li>32</li><li>33</li><li>34</li><li>35</li></ul><ul style="" class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li><li>18</li><li>19</li><li>20</li><li>21</li><li>22</li><li>23</li><li>24</li><li>25</li><li>26</li><li>27</li><li>28</li><li>29</li><li>30</li><li>31</li><li>32</li><li>33</li><li>34</li><li>35</li></ul>
- 这样之后,我们整个CoreData数据库就算创建完成,整个过程都是我们手动,这样对于
原理能更好的理解; - 运行之后其实数据库就已经创建完成,进入对应路径下,我们能看到已经创建好的数据库文件;
- 利用工具打开后,发现里面对应的表也帮我们创建好了;
- 经过上面的步骤创建后,在后续的工作中我们就不需要进行任何和数据库相关的工作了,所有和数据库打交道的工作就都交给了CoreData来实现。
CoreData数据库 系统创建
利用系统自带的方式创建数据库和手动创建的方式内部步骤一样的,只是系统将创建模型文件、生成上下文、关联数据库的工作帮我们做了,这些工作我们无需再做;
说这么多,我们一起来看看如何利用系统自带来创建CoreData数据库
对于利用系统自带创建的话,只需要两个步骤:
- 创建工程
- 创建实体已经关联实体类
创建工程
1、手动创建CoreData数据库时,我们创建一个和平常一样的工程, 特别注意:一定要勾选Use Core Data:
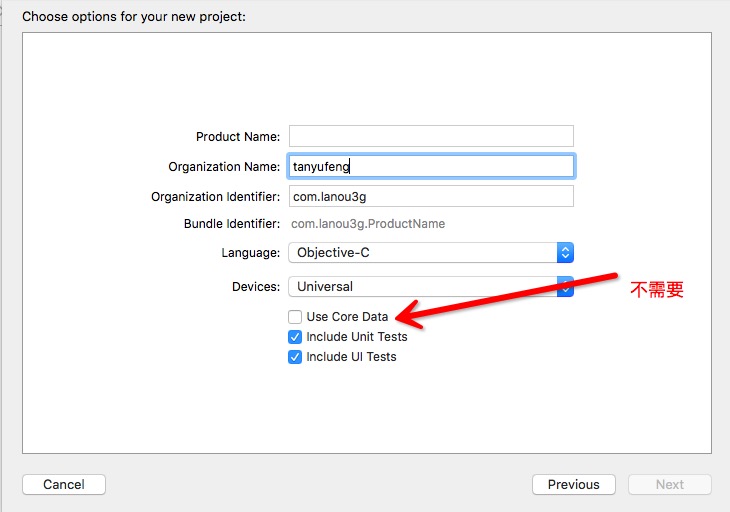
2、工程创建完后,系统会自动帮我们创建一个与工程同名的模型文件;以及帮我们写好了生成上下文和关联数据库的代码:
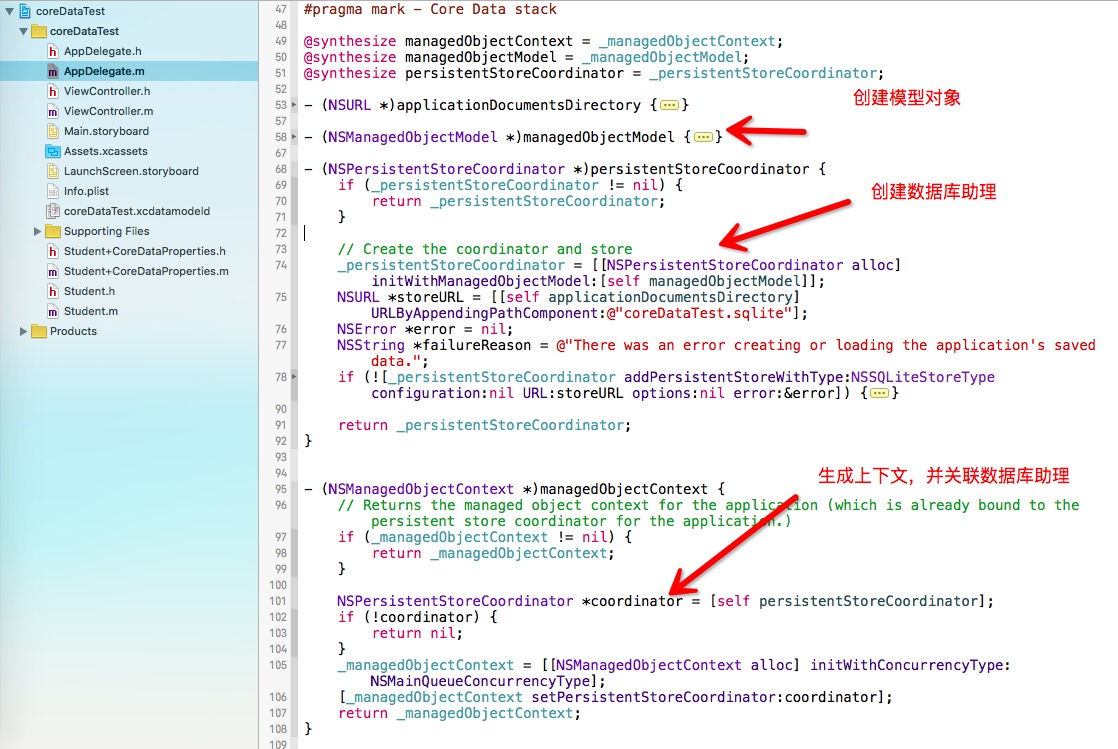
上面这些做好之后,我们只需要创建实体,以及关联实体类就可以
创建实体 关联实体类
创建实体和关联实体类和手动创建数据库的方式是一样的,参照手动创建2、3即可
简书链接:http://www.jianshu.com/p/880dd63c5f5e
这篇关于CoreData数据持久化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





