本文主要是介绍记录第一次Python爬虫实战:获取招聘单位名称与相应链接,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我的勤工助学工作是在就业中心推送招聘信息,其中有个每日必推的文章叫做“明日宣讲”,里面的内容是明天所有来学校做宣讲的单位名称、时间、地点以及链接到就业中心官网的单位招聘信息的二维码。

每年九月十月是校招高峰期,所以这个时候工作量特别大,几乎每天都有四五十个单位来校宣讲,然而二维码是我们每天负责的编辑用“草料二维码”手动制作的,非常耗时又辛苦,不少编辑同学又是在读大二大三,每天的课余时间有限,手动制作已经不能满足我们当前的需要。
看着学校就业网站上整齐排列的招聘信息,我们几个编辑叫苦不迭。在“草料”制作二维码时,我惊喜地发现,它竟然支持批量生成二维码!只需导入表格,点击几下鼠标即可。我陷入沉思:是否可以使用Python的爬虫技术,把就业网站上这些整齐的信息爬下来,然后生成表格呢?剩下的交给“草料”就完事了。说干就干!我开始了关于爬虫的学习之路。
根据“草料”批量生码的说明,我们只要能得到单位名称和对应的网页链接即可,单位名称用于二维码的文件名称,网页链接是二维码的内容。首先,我参考了nkwshuyi老师的入门教程:
如何用Python爬数据?(一)网页抓取_玉树芝兰-CSDN博客![]() https://blog.csdn.net/nkwshuyi/article/details/79435248
https://blog.csdn.net/nkwshuyi/article/details/79435248
环境搭建
我用的是Python3.7.4、Google Chrome浏览器和Visual Studio Code。下载requests_html模块和pandas模块:
pip install request_html
pip install pandas学习教程
按照教程我写了以下代码:
from requests_html import HTMLSessionsession = HTMLSession()
url = 'https://jobcareer.sdu.edu.cn//eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&type=ssoSearchXnzp&xjhType=all'
#url是学校就业网站
r = session.get(url)
print(r.html.text)
程序运行结果:
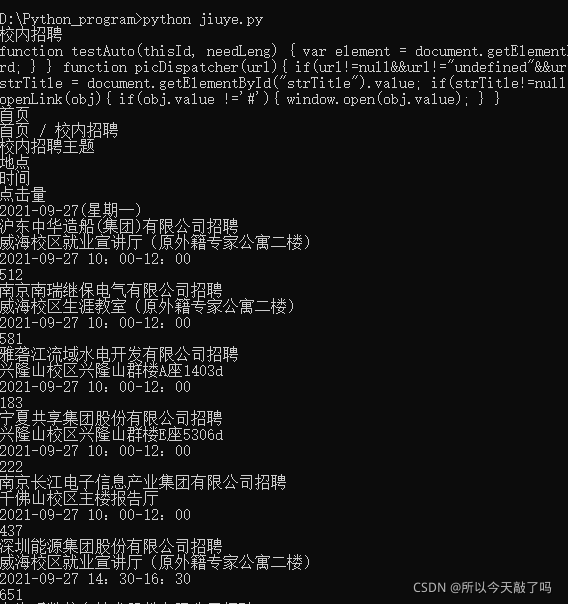
可以看到,程序运行后得到了我们想要的一些信息,但是我们制作二维码需要的链接还没有爬下来。
继续按照教程走,在就业网站空白处右键单击,菜单中选择“检查”,网页右侧出现分栏。点击分栏左上角的按钮,图中绿色箭头标出。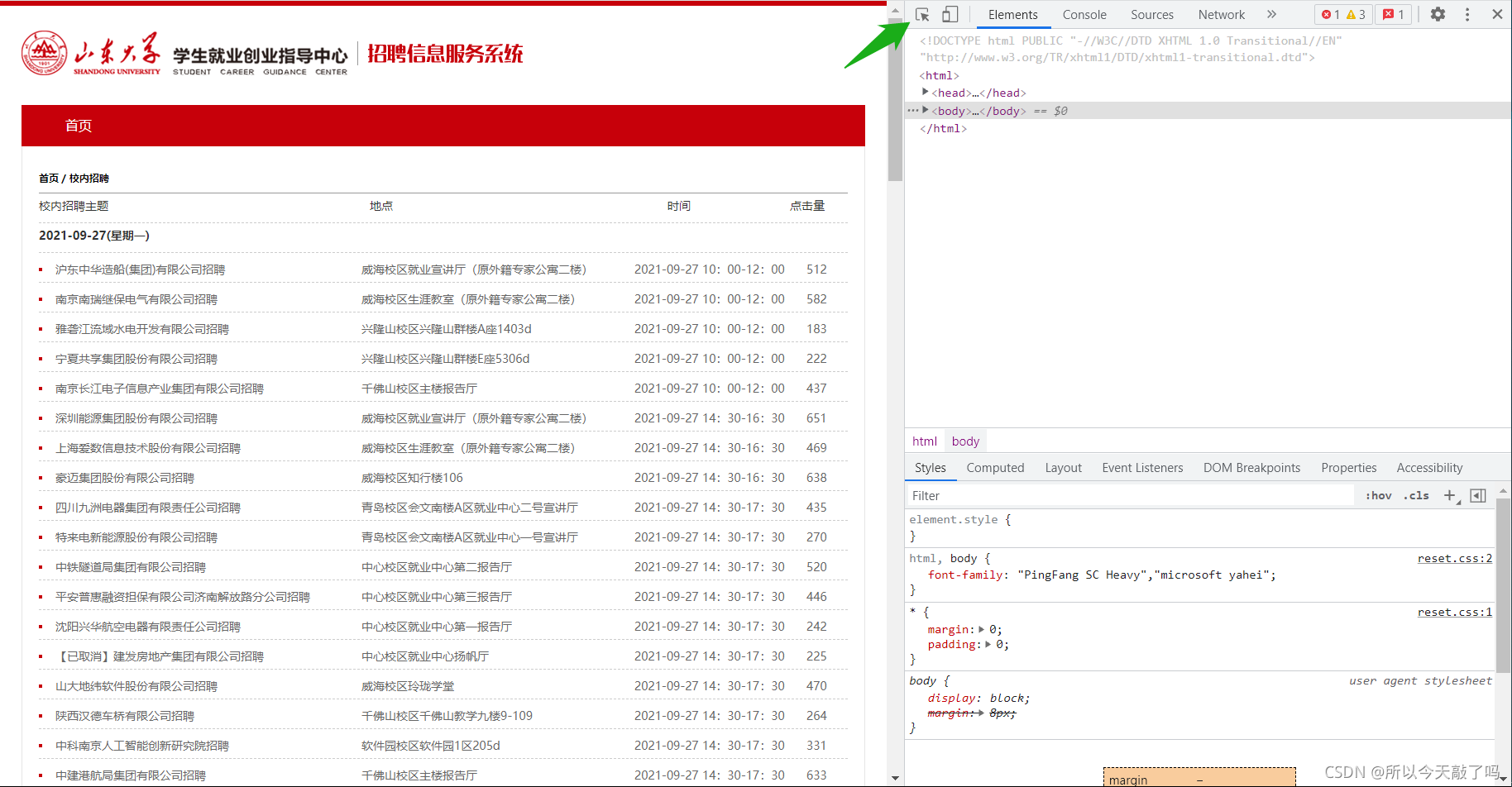
然后把鼠标悬停在第一个文内链接“沪东中华造船(集团)有限公司招聘”,点击一下。此时分栏里面,内容发生了变化。这个链接对应的源代码被放在分栏区域正中,高亮显示。
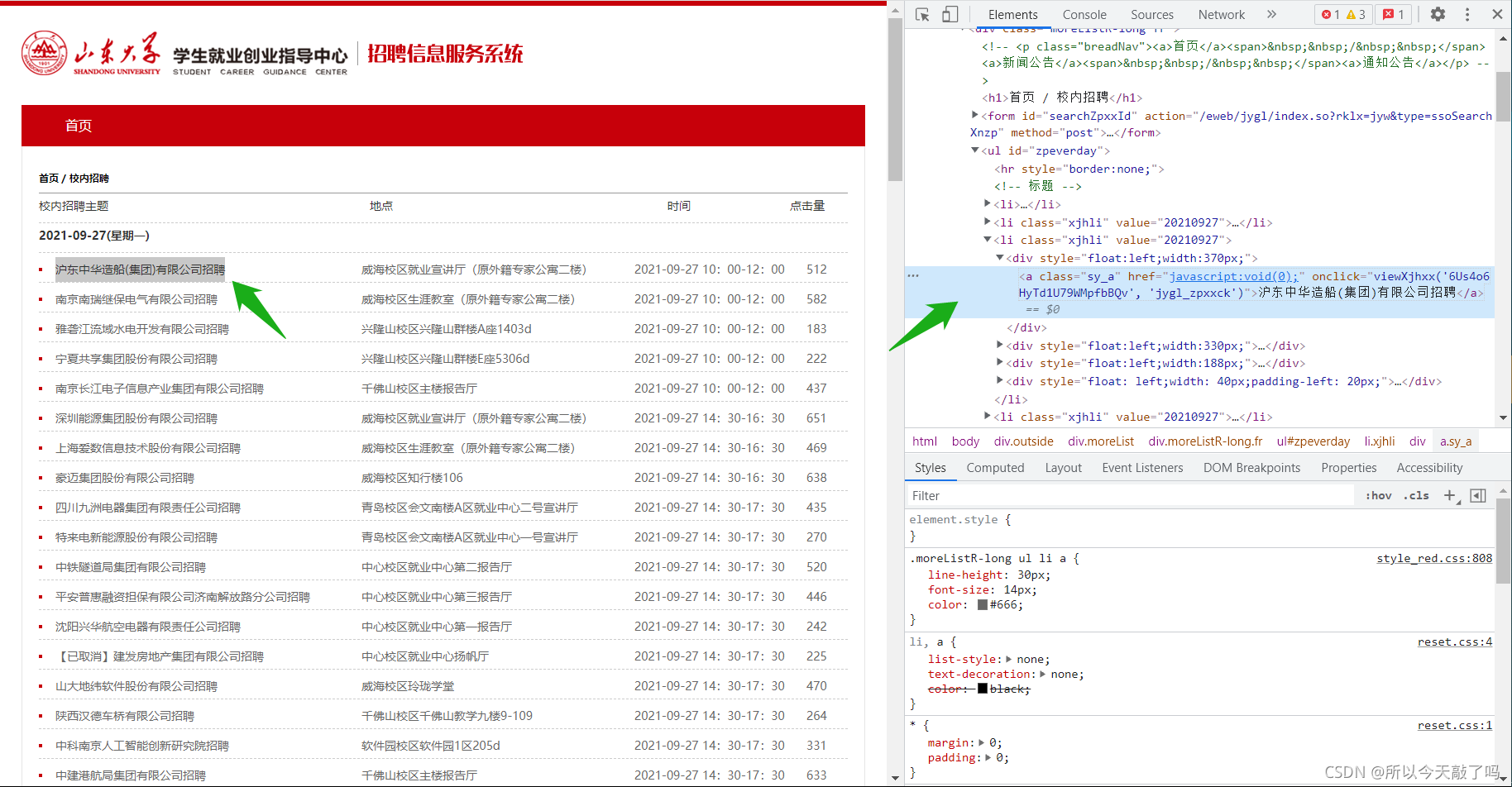
看着高亮的代码,我傻眼了:每个招聘单位代码里清一色的“javascript:void(0);”是什么鬼???教程里那可都是实实在在的网页链接啊!!!到后面我才知道,这种叫做“javascript动态网页”,想爬得另想办法。从这里开始,我只能靠自己了。
转换思路
我不甘心,想继续按照教程,期望能从网页中得到一些有用的信息。右键选择高亮区域代码,并且在弹出的菜单中,选择 Copy -> Copy selector。在VS Code中执行粘贴,发现复制了以下内容:
#zpeverday > li:nth-child(4) > div:nth-child(1) > a用这些内容定义sel变量,让 Python 从返回内容中,查找 sel 对应的位置,把结果存到 results 变量中。看看 results 里面都有什么。
from requests_html import HTMLSessionsession = HTMLSession()
url = 'https://jobcareer.sdu.edu.cn//eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&type=ssoSearchXnzp&xjhType=all'
r = session.get(url)
sel = '#zpeverday > li:nth-child(4) > div:nth-child(1) > a'
results = r.html.find(sel)
print(results)
看起来像是返回了和高亮代码内容差不多的列表,这个列表中只有一个元素。
我打算比较一下不同单位直接的网页链接,找出异同点。以前两个单位为例,他们的链接分别是:
#沪东中华造船(集团)有限公司
https://jobcareer.sdu.edu.cn/eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&rklx=jyw&type=ssoXnzpView&id=6Us4o6HyTd1U79WMpfbBQv
#南京南瑞继保电气有限公司
https://jobcareer.sdu.edu.cn/eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&rklx=jyw&type=ssoXnzpView&id=AEgnwsWqQpVZKW2vQz4vh2可以发现:除了最后一个等号后面的内容不同以外,前面都是一样的。这让我很是欣慰,前面相同的部分像是通式,后面相异的部分像是特征值,只要获取到每个单位的特征值,问题不就解决了吗!
回顾前面和高亮代码内容差不多的列表,我发现,里面就包含了单位的特征值!
现在我们需要做的就是把特征值给取出来,这里用到.split()方法,轻而易举便取出了特征值:
from requests_html import HTMLSessionsession = HTMLSession()
url = 'https://jobcareer.sdu.edu.cn//eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&type=ssoSearchXnzp&xjhType=all'
r = session.get(url)
sel = '#zpeverday > li:nth-child(4) > div:nth-child(1) > a'
results = r.html.find(sel)
print(results)eigenvalue = str(results)
eigenvalue_list = eigenvalue.split("'") #用'分割
for i in range(len(eigenvalue_list)):print(eigenvalue_list[i])查看运行结果,终于找到了特征值:列表倒数第四个元素。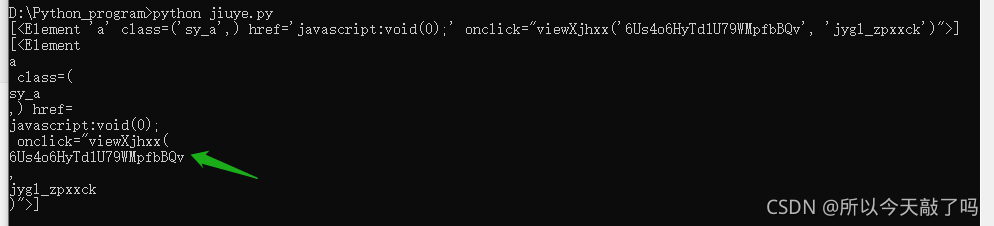
受教程启发,我又比较了不同单位Copy selector之后的内容:
#zpeverday > li:nth-child(4) > div:nth-child(1) > a #沪东中华造船(集团)有限公司招聘
#zpeverday > li:nth-child(5) > div:nth-child(1) > a #南京南瑞继保电气有限公司招聘非常幸运,和教程中的情况一致,只需去掉“li”后面的“:nth-child(n)”即可。
from requests_html import HTMLSessionsession = HTMLSession()
url = 'https://jobcareer.sdu.edu.cn//eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&type=ssoSearchXnzp&xjhType=all'
r = session.get(url)
sel = '#zpeverday > li > div:nth-child(1) > a'
results = r.html.find(sel)
print(results)运行程序,查看结果:

这一次,返回了一个具有很多元素的大列表!每一个元素对应一个单位。初步实现了获取招聘网站内所有单位特征值的功能。继续使用.split()方法即可取出特征值。
最后一步
整理并完善程序:去掉单位后面的“招聘”、过滤“已取消”的单位、并按顺序给单位编号,使用pandas模块,定制表头,生成excel表格,由于“草料”限制,只支持“.xlsx”文件。注意编码时使用“gbk”,否则可能出现乱码情况。
from requests_html import HTMLSession
import pandas as pdsession = HTMLSession()
url = 'https://jobcareer.sdu.edu.cn//eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&type=ssoSearchXnzp&xjhType=all'
r = session.get(url)def get_text_link_from_sel(sel):mylist = []results = r.html.find(sel)i = 1for result in results:mytext = str(i)+result.text.replace('招聘','')if '已取消' in mytext:continueeigenvalue = str(result)eigenvalue_list = eigenvalue.split("'")mylink = 'https://jobcareer.sdu.edu.cn/eweb/jygl/index.so?modcode=jygl_xjhxxck&subsyscode=zpfw&rklx=jyw&type=ssoXnzpView&id='+ eigenvalue_list[-4]mylist.append((mytext, mylink))i = i+1return mylistdf = pd.DataFrame(get_text_link_from_sel('#zpeverday > li > div:nth-child(1) > a'))
df.columns = ['company', 'link']
df.to_excel('output.xlsx', encoding='gbk', index=False)运行程序,查看生成的表格:
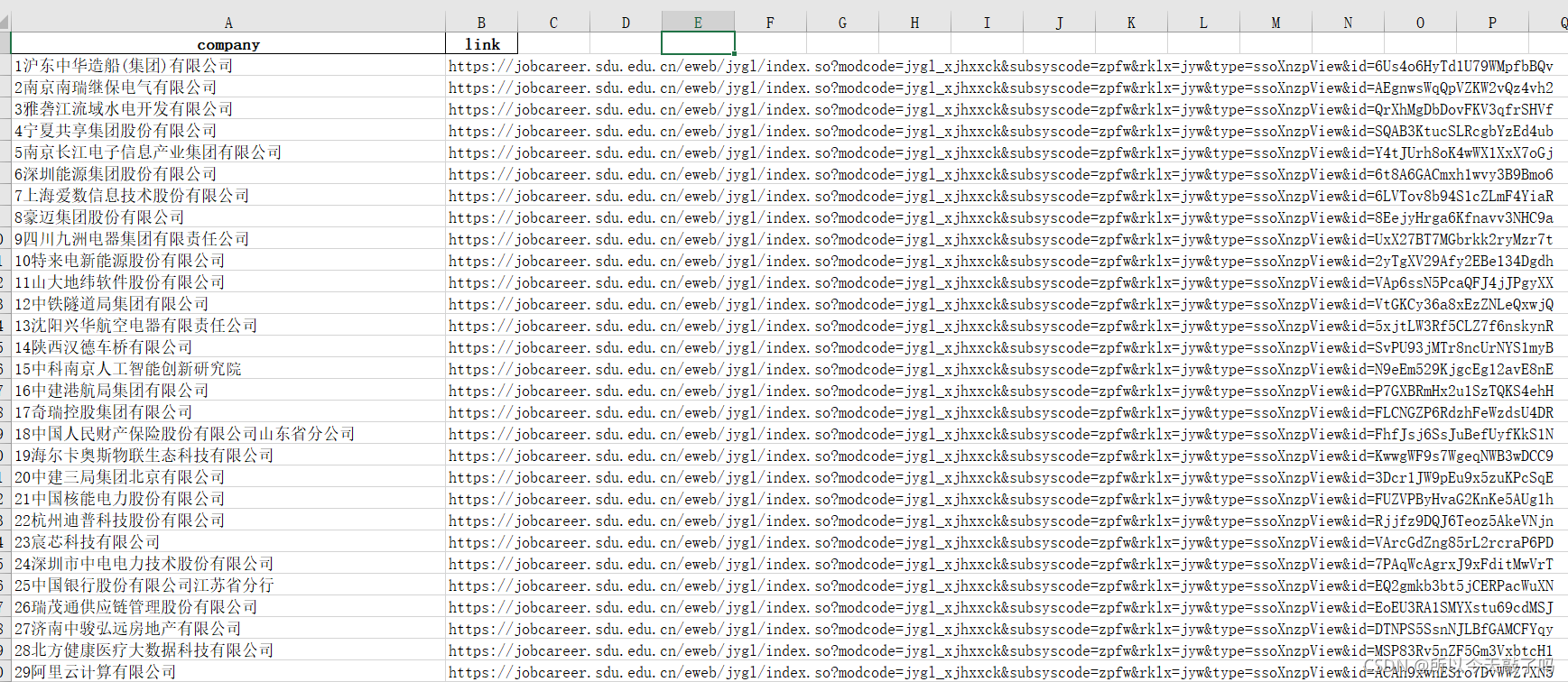
正合我意!接下来把表格文件导入“草料”,交给它就行了。至此,我获取了单位名称和对应链接,再也不必手动制作二维码了。当然,前文关于通式和特征值的结论是由两个推广到所有单位的,所以链接的正确性还有待验证。
这篇关于记录第一次Python爬虫实战:获取招聘单位名称与相应链接的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




