本文主要是介绍流数据存储之Elasticsearch添加发送器常见问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:lly
背景
近期很多小伙伴在使用流数据对接Elasticsearch遇到了问题,今天就来分享一下在使用Elasticsearch添加发送器可能遇到的问题。
对于Elasticsearch的搭建和iServer使用基础教程,可以参考往期文章:
1.ElasticSearch集群部署
2.流数据存储之Elasticsearch
常见问题
1.Elasticsearch添加发送器各参数如何填写,如下图:

其中队列名即ES中的索引名即"_index",目录名为文档名即"_type"(ES从6.x开始_type不再起作用,所以写入时_type值都为_doc,低版本则为设置的目录名);这些参数如果没有提前在集群中创建,iServer会根据所填参数自动进行创建。
2.使用Elasticsearch添加发送器入库数据时,报错ES only supports latitude and longitude projection data,如下图

这个错误是由于ElasticSearch中存储地理坐标数据需要使用geo-point类型,换句话说目前只支持经纬度坐标系的点;出现这个问题首先去检查我们数据接收器的元数据里,要素的数据类型是否为POINT,如下图:

其次经纬度字段命名必须为大写的X,Y如下图:

3.使用Elasticsearch添加发送器入库数据时,报错Connection error (check network and/or proxy settings)- all nodes failed; tried,如下图:

出现这个错误一般是由于Elasticsearch配置导致无法连接上集群,可在elasticsearch.yml中增加以下配置
node.name: elasticsearch
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["elasticsearch"]
http.cors.enabled: true
http.cors.allow-origin: "*"
4.查看iServer支持的ES版本,在iServer的根目录\webapps\iserver\WEB-INF\lib下,可以查看iServer当前所用的ES包版本,ES版本最低兼容需小于此版本,查看最低兼容版本可启动集群后,访问9200端口查看集群概览,如下图:


5.相同模型写入ES单节点成功,写入ES集群失败,并且Spark抛出以下错误
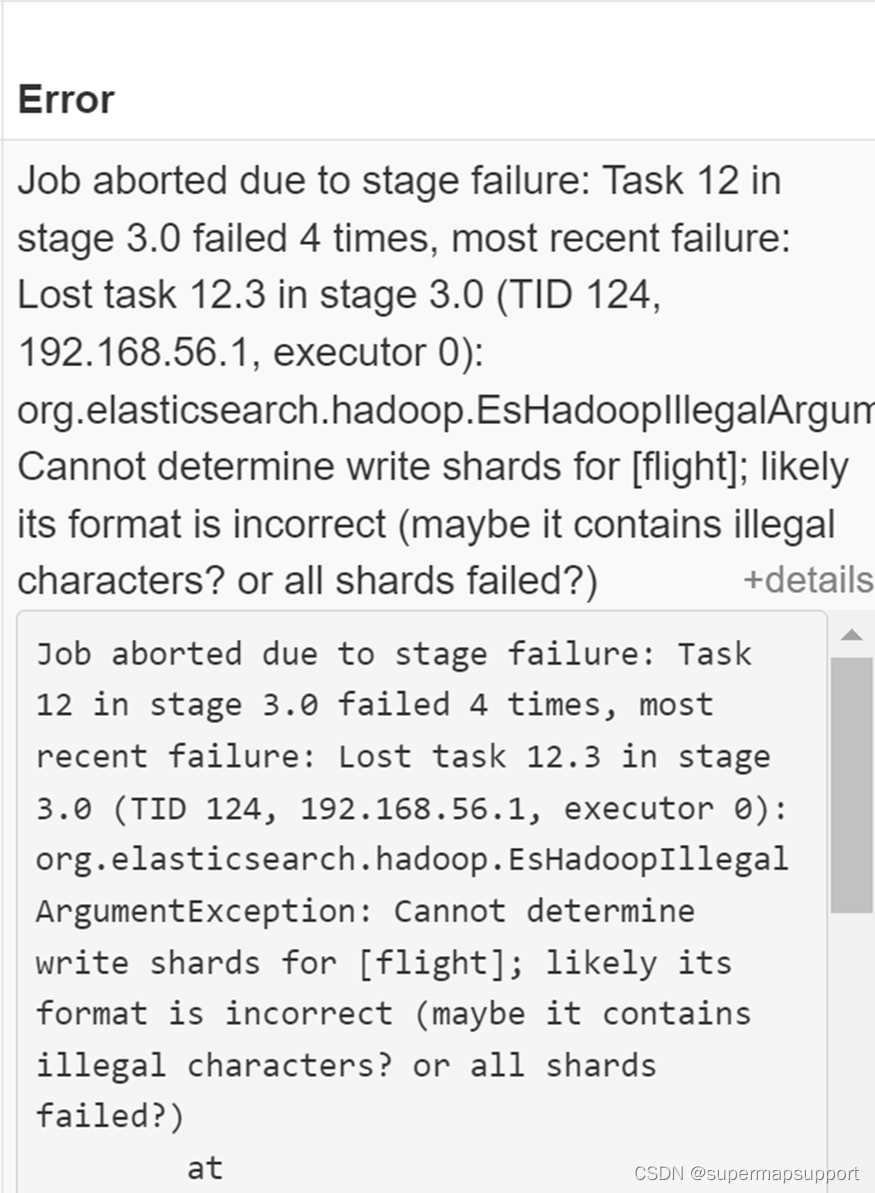
查看ES日志报错low disk

这是由于磁盘空间到达85%时,es会将节点上面的索引标为只读,导致不能写入数据,可以释放空间,或者关闭阀值设置
cluster.routing.allocation.disk.threshold_enabled: false
这篇关于流数据存储之Elasticsearch添加发送器常见问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




