本文主要是介绍Solr搜索引擎第九篇-DataImportHadler导入MySQL数据超详细,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 了解Index Handler
- 通过DIH导入Mysql数据
- 步骤一:准备mysql数据库和表数据
- 步骤二:拷贝mysql的驱动jar
- 步骤三:在solrconfig.xml配置DIH
- 步骤四:集成中文分词器IKAnalyzer
- 步骤五:配置Solr存储字段的格式
- 步骤六:编写dih-data-config.xml文件
- 配置数据源
- 配置document对应的实体
- 单表全量
- 多表全量
- 单表增量
- 多表增量
- 动态入参
- API接口
- 全量导入
- 增量导入
- 查看导入状态
- 重新加载dih配置文件
- 终止当前操作
- 总结
了解Index Handler
Index handler 索引处理器,是一种Request handler 请求处理器。
Solr对外提供http服务,每类服务在solr中都有对应的request handler来接收处理,Solr中提供了默认的处理器实现,如有需要我们也可提供我们的扩展实现,并在conf/solrconfig.xml中进行配置。在 conf/solrconfig.xml中,requestHandler的配置就像我们在web.xml中配置servlet-mapping(或spring mvc 中配置controller 的requestMap)一样:配置该集合/内核下某个请求地址的处理类。
Solrconfig中通过updateHandler元素配置了一个统一的更新请求处理器支持XML、CSV、JSON更新请求(映射地址为/update),它根据请求提交内容流的内容类型Content-Type将其委托给适当的ContentStreamLoader来解析内容,再进行索引更新。
我们可以打开内核主目录下的/conf/solrconfig.xml配置文件,查看默认配置了的update的处理器内容:
<!-- The default high-performance update handler -->
<updateHandler class="solr.DirectUpdateHandler2">
除此之外,我们还可以自定义handler(一般使用默认的就可以了):
<requestHandler name="/update" class="solr.UpdateRequestHandler"/>
通过DIH导入Mysql数据
前提:
- 启动一个Solr服务实例
- 创建一个名称为mycore内核
步骤一:准备mysql数据库和表数据
新建一个mysql数据库:dih_test
创建并导入如下表和数据:
create table t_product(prod_id varchar(64) PRIMARY key,name varchar(200) not null,simple_intro LONGTEXT,price bigint,uptime datetime,brand_id varchar(64),last_modify_time datetime,isDelete char(1)
) comment '产品表';create table t_brand(id varchar(64) PRIMARY key,name varchar(200) not null,last_modify_time datetime
) comment '产品对应的品牌表';create table t_cat(id varchar(64) PRIMARY key,name varchar(200) not null,last_modify_time datetime
) comment '产品的分类表';create table t_prod_cat(prod_id varchar(64),cat_id varchar(64) ,last_modify_time datetime
) comment '产品-分类关系表';INSERT INTO t_brand VALUES ('b01', '华为', '2018-5-17 00:00:00');
INSERT INTO t_brand VALUES ('b02', '戴尔', '2018-5-18 00:00:00');INSERT INTO t_cat VALUES ('c01', '台式机', '2018-5-17 00:00:00');
INSERT INTO t_cat VALUES ('c02', '服务器', '2018-5-17 00:00:00');INSERT INTO t_product VALUES ('tp001', '华为(HUAWEI)RH2288HV3服务器', '12盘(2*E5-2630V4 ,4*16GB ,SR430 1G,8*2TSATA,4*GE,2*460W电源,滑轨) ', 4699900, '2018-5-8 00:00:00', 'b01', '2018-5-8 00:00:00', '0');
INSERT INTO t_product VALUES ('tp002', '戴尔 DELL R730 2U机架式服务器', '戴尔 DELL R730 2U机架式服务器(E5-2620V4*2/16G*2/2T SAS*2热/H730-1G缓存/DVDRW/750W双电/导轨)三年', 2439900, '2018-5-18 15:32:13', 'b02', '2018-5-18 17:32:23', '0');INSERT INTO t_prod_cat VALUES ('tp001', 'c01', '2018-5-8 14:48:56');
INSERT INTO t_prod_cat VALUES ('tp001', 'c02', '2018-5-8 14:49:15');
INSERT INTO t_prod_cat VALUES ('tp002', 'c01', '2018-5-18 15:32:48');
INSERT INTO t_prod_cat VALUES ('tp002', 'c02', '2018-5-18 18:29:23');
表结构说明:
- t_product:商品表,主表
- t_brand:品牌表,子表,商品表和品牌表是一对一关系
- t_cat:商品分类表,子表,商品表和商品分类表是一对多关系,一个商品有多个分类,通过t_prod_cat表进行关联
步骤二:拷贝mysql的驱动jar
因为Solr底层会通过mysql的驱动jar去连接数据库,获取数据后导入到引擎中,因此这里需要将mysql的驱动jar拷贝到D:\Program Files\solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib
我这里拷贝的是:mysql-connector-java-6.0.6.jar
步骤三:在solrconfig.xml配置DIH
在创建的内核mycore主目录的/conf/solrconfig.xml文件中添加一个requestHandler,名称为dataimport,具体内容如下:
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" /><requestHandler name="/dataimport" class="solr.DataImportHandler"><lst name="defaults"><str name="config">dih-data-config.xml</str></lst>
</requestHandler>
lib说明:
- DIH的jar包默认是没有引入的,需要引入
- DIH的jar包是存放在D:\Program Files\solr-7.5.0\dist中的
requestHandler 说明:
- name必须为/dataimport
- dih-data-config.xml文件是必须要配置的,该文件可以使绝对路径或相对集合主目录conf/的相对路径,这里直接配置在conf/目录下。该文件是最核心的部分,在后面会讲述到。
步骤四:集成中文分词器IKAnalyzer
因为有些字段需要进行分词,比如name、simple_intro,且这些字段又是中文的,因此solr中要集成中文分词器IKAnalyzer,具体如何集成请看我的另一篇文章,有非常详细的说明:Solr搜索引擎第六篇-Solr集成中文分词器IKAnalyzer
集成完毕后,确认在mycore内核主目录下的/conf/managed-schema.xml文件中有添加中文分词的FieldType:
<fieldType name="zh_CN_text" class="solr.TextField"><analyzer><tokenizer class="com.dalomao.framework.lucene.analizer.ik.IKTokenizer4Lucene7Factory" useSmart="true" /> </analyzer>
</fieldType>
步骤五:配置Solr存储字段的格式
将上述的产品表对应的字段数据导入到solr中,需要定义映射到solr中的哪些字段,这些前提工作需要先做好。
这部分需要根据自己的实际情况去定义(是否需要分词、索引、存储、多值等情况),这里我列出映射关系(其中brand_name和cat_name两个字段是需要关联出来的,isDelete只是逻辑删除标志这里不会用到):
| | | |
|---|---|---|
| prod_id | solr_prod_id | 商品ID,唯一键,字符串,不分词,索引,存储 |
| name | solr_name | 商品名称,字符串,中文分词,索引,存储 |
| simple_intro | solr_simple_intro | 商品简介,字符串,中文分词,索引,不存储 |
| price | solr_price | 价格,整数(单位元),不分词,索引,存储 |
| uptime | solr_uptime | 上架时间,时间类型,不分词,索引、存储,docValues支持排序 |
| brand_id | solr_brand_id | 品牌ID,字符串,不分词,不索引,存储 |
| brand_name | solr_brand_name | 品牌名称,字符串,不分词,索引,存储,docValues支持分页查询 |
| cat_name | solr_cat_name | 分类名称,多值,不分词,索引,存储,docValues支持分页查询 |
| last_modify_time | solr_last_modify_time | 最后更新时间,时间类型,不分词,索引,存储,docValues支持排序 |
根据上述表格中solr字段格式定义,修改mycore主目录下的/conf/managed-schema.xml文件,添加如下内容:
<field name="solr_prod_id" type="string" indexed="true" stored="true" required="true" />
<field name="solr_name" type="zh_CN_text" indexed="true" stored="true" required="true" />
<field name="solr_simple_intro" type="zh_CN_text" indexed="true" stored="false" />
<field name="solr_price" type="pint" indexed="true" stored="true" />
<field name="solr_uptime" type="pdate" indexed="true" stored="true" docValues="true" />
<field name="solr_brand_id" type="string" indexed="false" stored="true" />
<field name="solr_brand_name" type="string" indexed="true" stored="true" docValues="true" />
<field name="solr_cat_name" type="strings" indexed="true" stored="true" />
<field name="solr_last_modify_time" type="pdate" indexed="true" stored="true" docValues="true" />
这里我不使用solr自带的唯一键id,而重新设置唯一键为solr_prod_id,需要改两个地方:
<!-- 将原来的唯一键id设置非必须 required=false -->
<field name="id" type="string" indexed="true" stored="true"
required="false" multiValued="false" /><!-- 唯一键设置为solr_prod_id -->
<uniqueKey>solr_prod_id</uniqueKey>
步骤六:编写dih-data-config.xml文件
在mycore主目录的/conf/目录下创建dih-data-config.xml文件
配置数据源
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/dih_test?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT" user="root" password="123456" />
serverTimezone=GMT是为解决引入最新版mysql驱动jar报时区错误而加入的连接请求参数
上面配置的是单数据源,如果想配置多数据源的话,则需要多加一个属性name,如下:
<dataSource type="JdbcDataSource" name="ds-1" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db1-host/dbname" user="db_username" password="db_password"/>
<dataSource type="JdbcDataSource" name="ds-2" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db2-host/dbname" user="db_username" password="db_password"/>
说明:
- name、type是通用属性,type默认是JdbcDataSource
- 其他属性是非固定的,支持多种数据库
配置document对应的实体
这一部分是最核心的配置部分,我们分为如下情况进行说明:
- 单表全量:单张表的全量数据导入的情形
- 多表全量:多张关联表(存在父子表)的全量数据导入的情形
- 单表增量:单张表的增量数据导入的情形
- 多表增量:多张关联表(存在父子表)的增量数据导入的情形
单表全量
dih-data-config.xml文件加入字段映射关系:
<document><entity name="product" query="SELECT * FROM t_product"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/></entity>
</document>
注意:document下可包含一个或多个entity数据实体
entity标签独有的属性有如下:
- name:必须,表示实体的唯一名称
- dataSource:当配置多个数据源时,指定使用的数据源的名字
- processor:当数据源是非RDBMS时,必须指定处理器。默认是SqlEntityProcessor
- transformer:应用在该实体上的转换器
- rootEntity:默认document元素的子entity是rootEntity,如果把rootEntity属性设为false,则它的子类会被作为rootEntity(以此类推),rootEntity返回的每一行会创建一个document
- pk:仅用于增量导入,实体的主键列名,表示的是数据库表中的主键,和模式中的唯一键是两个不同的东西。
- onError:当处理entity的行为document的过程中发生异常该如何处理:默认是 abort,放弃导入。skip:跳过这个文档,continue:继续索引该文档
- preImportDeleteQuery:在全量导入前,如果需要进行索引清理cleanup,可以通过此属性指定一个清理的索引删除查询,否则默认是删除所有。只有document的直接子entity设置此属性有效
- postImportDeleteQuery:指定全量导入后需要进行索引清理的delete查询。只有document的直接子entity设置此属性有效
entity中没有配置processor处理器,则默认使用的是SqlEntityProcessor。该处理器也有一些默认的属性,这些属性主要是用于全量或增量导入的时候指定sql语句查询数据库,属性说明如下:
- query:必须,从数据库中加载实体数据用的SQL语句。
- deltaQuery:仅用于增量导入,指定增量数据pk的查询SQL。
- parentDeltaQuery:指定增量关联父实体的pk的查询SQL。
- deletedPkQuery:仅用于增量导入,被删除实体的pk查询SQL。
- deltaImportQuery:仅用于增量导入,指定增量导入实体数据的查询SQL。如果没有指定该查询语句,solr将使用query属性指定的语句,经修改后来查询加载增量数据(这很容易出错),因此一般有增量查询的时候往往需要定义该属性的增量查询语句。在该语句中往往需要引用deltaQuery查询结果的列值,通过 $ {dih.delta.< column-name >} 来引用,如:select * from tbl where id=${dih.delta.id}
单表全量情形下的dih-data-config.xml文件最终内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig><dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/dih_test?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT" user="root" password="123456" /><document><entity name="product" query="SELECT * FROM t_product"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/></entity></document>
</dataConfig>
有两种方式触发全量导入,一种是登陆web控制台操作,一种是访问url发送post请求,这里只说明用web控制台操作的方式,http api放在最后统一说明。
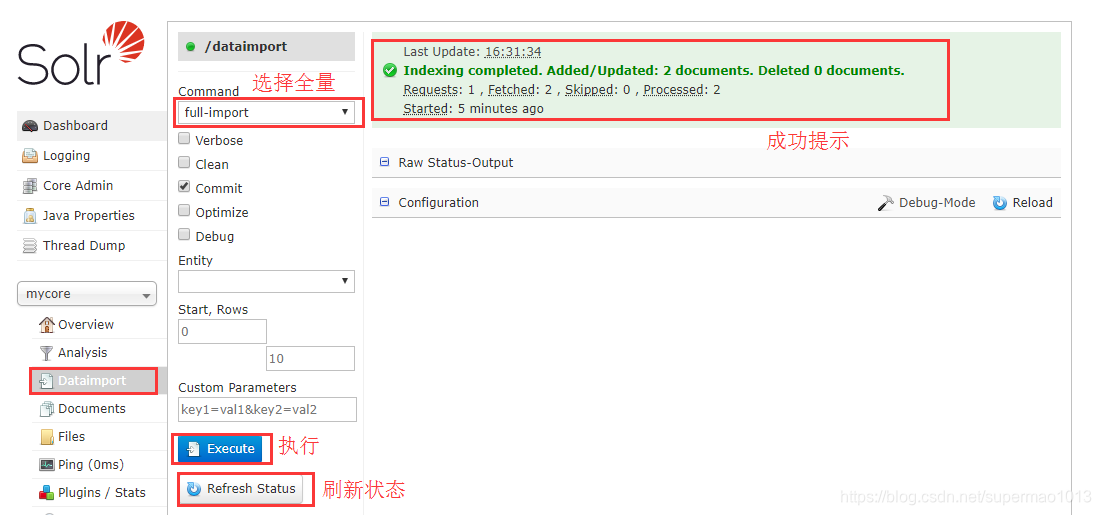
然后去查询界面,确实已经导入了:
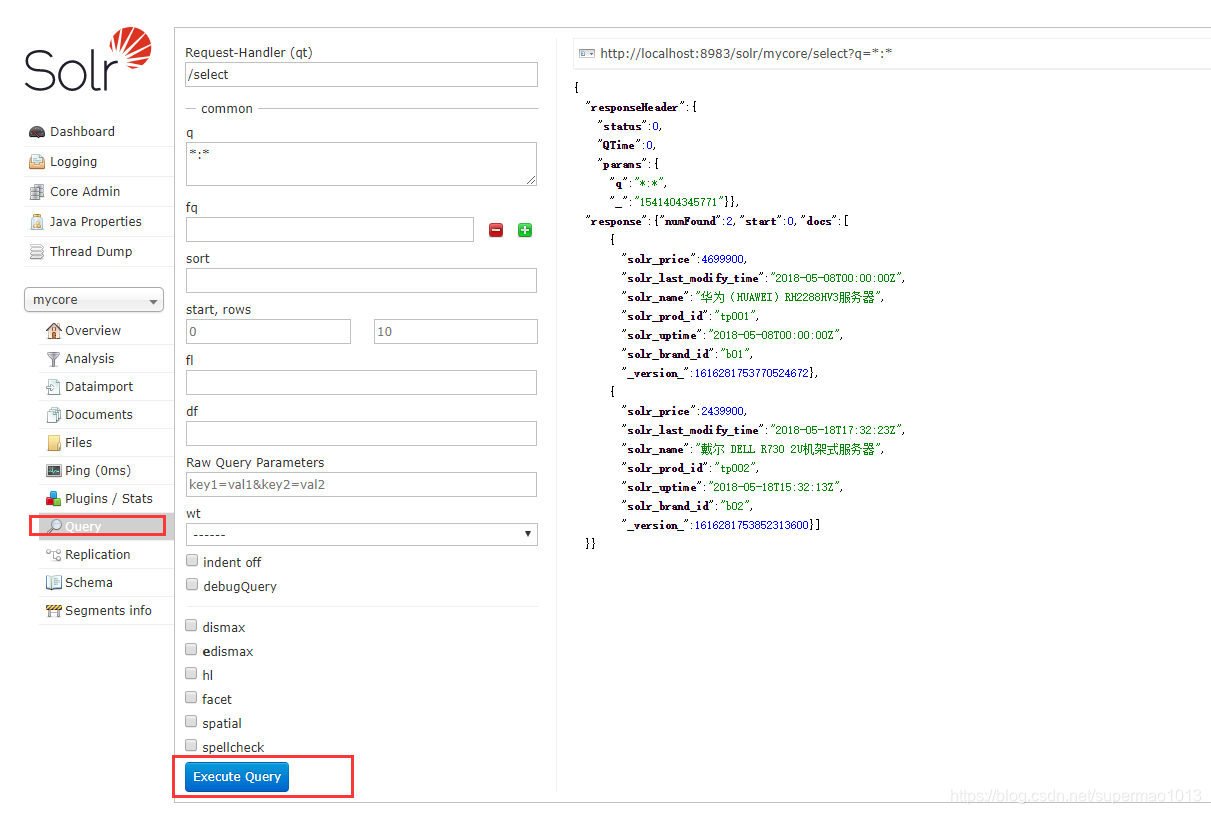
注意:在全量数据导入成功之后,solr会自动在内核主目录/conf/下生成dataimport.properties文件,记录上次导入的时间,主要用于下次增量导入的起始时间。
多表全量
此时我们需要额外导入两个字段solr_brand_name、solr_cat_name,而这两个字段是在子表中,需要关联出来的。solr提供了嵌套entity的写法,可以获取子表中的数据,如下:
<document><entity name="product" query="SELECT * FROM t_product"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/><entity name="brand" query="SELECT name FROM t_brand WHERE id='${product.brand_id}'"><!-- 商品的品牌 --><field column="name" name="solr_brand_name"/></entity><entity name="product_cat" query="SELECT cat_id FROM t_prod_cat WHERE prod_id='${product.prod_id}'"><entity name="cat" query="SELECT name FROM t_cat WHERE id='${product_cat.cat_id}'"><!-- 商品的分类 --><field column="name" name="solr_cat_name"/></entity></entity></entity>
</document>
上述写法,应该很简单明了,基本都看得懂,就是主表和子表的LEFT JOIN关系给他拆分成多个嵌套的entity,几个点说明一下:
- 第一层的entity为rootEntity,嵌套的entity都是子entity,你可以理解为主表和子表的关系
- ${product.brand_id}这种写法很容易理解,product就是上层entity的名称,关联的使用会用到
- 若主表和子表的关系嵌套很深,则多些几个嵌套entity即可
- ${xxx}这种写法一定要带上单引号,否则会报错!
登陆控制台查询,导入正确:
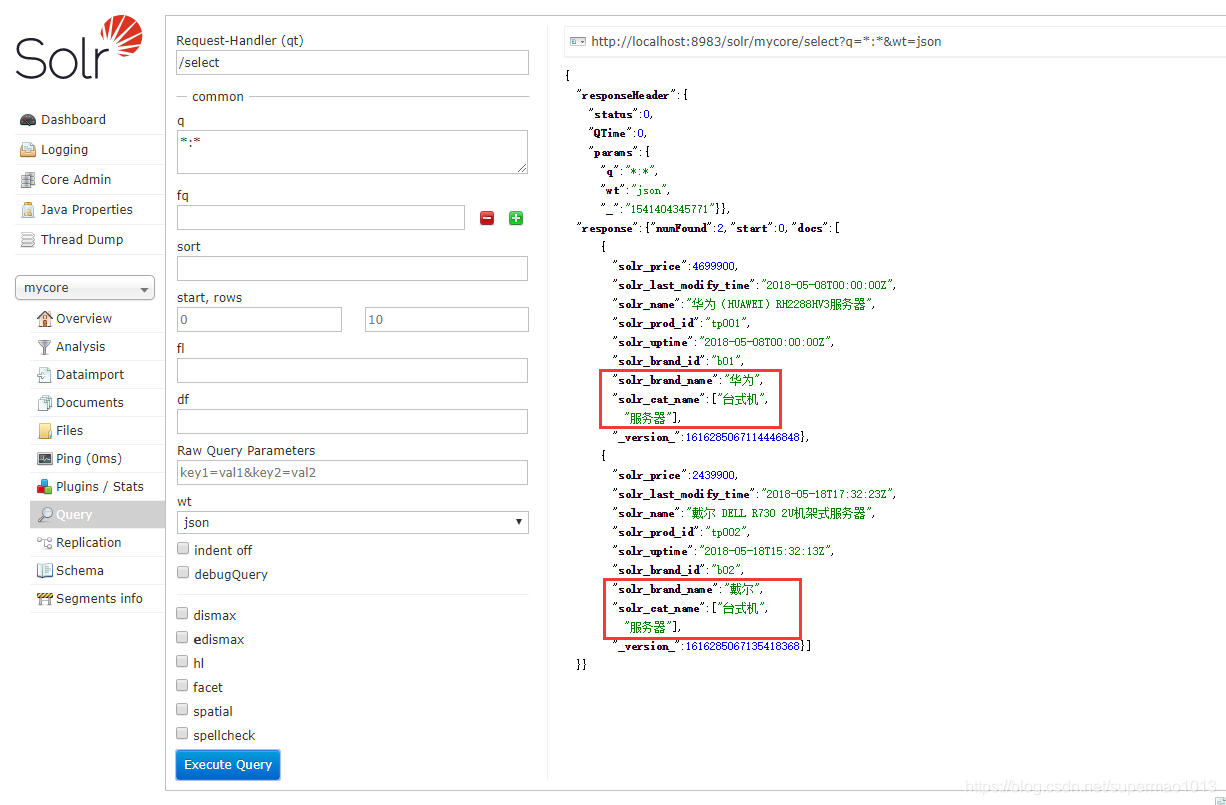
单表增量
单表增量导入,首先这张表必须有两个字段:更新时间、逻辑删除标志,缺一不可!因为增量导入会分为更新、删除两种情况,所以在一开始设计表结构的时候就要注意!就当前这个例子的话,就是指last_modify_time、isDelete两个字段.
单表增量只需要添加entity的几个属性即可,如下:
<document><entity name="product" query="SELECT * FROM t_product"deltaQuery="SELECT prod_id FROM t_product WHERE last_modify_time > '${dataimporter.last_index_time}'"deltaImportQuery="SELECT * FROM t_product WHERE prod_id='${dih.delta.prod_id}'"deletedPkQuery="SELECT prod_id FROM t_product WHERE isDelete='1'"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/></entity>
</document>
说明:
- query:用于全量导入的语句,前面已经介绍过了,这里不用改动它
- deltaQuery:用来同步更新的数据,根据dataimporter.properties每次刷新的last_index_time获取变更后的数据,这里只能返回主键prod_id
- deltaImportQuery:用来同步更新的数据,solr首先会从deltaQuery语句查询修改的主键,然后使用deltaImportQuery语句并传入deltaQuery查出来的主键去查询出最终更新后的数据
- deletedPkQuery:用来同步删除的数据,当然在mysql层面是逻辑删除,而在solr这里是直接删除该文档
- ${dataimporter.last_index_time}是默认的固定写法,表示上次同步的时间,前面也有介绍,每次全量更新或增量更新后,solr内部会维护这么一个变量(保存在mycore主目录/conf/dataimport.properties文件中)
- ${dih.delta.prod_id}:deltaImportQuery语句中会引用deltaQuery语句中的字段,引用于法dih.delta是固定写法,后面跟上deltaQuery查询出来的字段名
具体如何测试,这里不详细描述。无非就是改下mysql中的last_modify_time和isDelete,然后看下solr中是否会同步更新及删除document数据,但是在操作solr更新的时候要选择同步更新delta-import,这个要注意下:
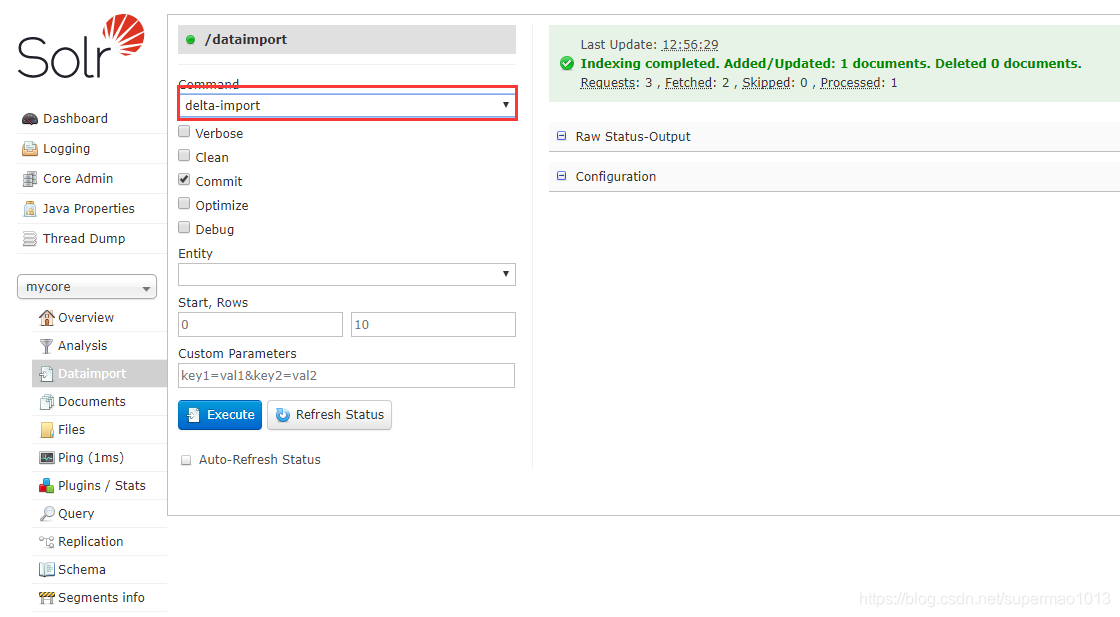
多表增量
父子关联表,当父表或任何一张子表发生变更了,则都是需要同步更新到solr,因此子表也必须有更新时间这个字段,这里只演示更新时间,至于子表的逻辑删除同父表的处理逻辑一致,修改后的dih-data-config.xml文件如下:
<document><entity name="product" query="SELECT * FROM t_product"deltaQuery="SELECT prod_id FROM t_product WHERE last_modify_time > '${dataimporter.last_index_time}'"deltaImportQuery="SELECT * FROM t_product WHERE prod_id='${dih.delta.prod_id}'"deletedPkQuery="SELECT prod_id FROM t_product WHERE isDelete='1'"pk="prod_id"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/><entity name="brand" query="SELECT name FROM t_brand WHERE id='${product.brand_id}'"deltaQuery="SELECT id FROM t_brand WHERE last_modify_time > '${dataimporter.last_index_time}'"deltaImportQuery="SELECT name FROM t_brand WHERE id='${dih.delta.id}'"parentDeltaQuery="SELECT prod_id FROM t_product WHERE brand_id='${brand.id}'"pk="id"><!-- 商品的品牌 --><field column="name" name="solr_brand_name"/></entity><entity name="product_cat" query="SELECT cat_id FROM t_prod_cat WHERE prod_id='${product.prod_id}'"deltaQuery="SELECT prod_id,cat_id FROM t_prod_cat WHERE last_modify_time > '${dataimporter.last_index_time}'"parentDeltaQuery="SELECT prod_id FROM t_product WHERE prod_id='${product_cat.prod_id}'"pk="prod_id"><entity name="cat" query="SELECT name FROM t_cat WHERE id='${product_cat.cat_id}'"deltaQuery="SELECT id FROM t_cat WHERE last_modify_time > '${dataimporter.last_index_time}'"deltaImportQuery="SELECT name FROM t_cat WHERE id='${dih.delta.id}'"parentDeltaQuery="SELECT prod_id,cat_id FROM t_prod_cat WHERE cat_id='${cat.id}'"pk="id"><!-- 商品的分类 --><field column="name" name="solr_cat_name"/></entity></entity></entity>
</document>
看起来有点复杂~~
- 首先,每张表都可能更新,因此都需要写deltaQuery和deltaImportQuery语句。其实也可以不写deltaImportQuery语句,如果不写的话,那么query就会被拿来用,查询出最终的实体数据。但这样容易出错,所以建议分开。
- query语句是全量更新的,这里我们不改,保留之前的即可。
- pk:查询增量的时候,每一个entity都要指定一个pk值,对应的是数据库中的主键
- parentDeltaQuery:子表有更新,必须向上关联出父表的id,然后将更新信息一直向上传递,parentDeltaQuery就是这个作用,主要用来通过子表查询出父表的主键
- product_cat这个entity是中间表,会有两个主键,这里pk随便指定一个即可
- 查询流程是这样的:主表或子表通过deltaQuery语句查询出本身更新后的主键,若本身是主表,则直接使用deltaImportQuery语句查询出更新的数据;若本身是子表,则通过parentDeltaQuery语句查询出更新后的父表的主键,并向上传递通知父表(直到传递到rootEntity),然后所有的父表和本身通过deltaImportQuery语句查出更新的数据。
这种情况在子表很多的情况下就显得比较复杂,因此还有一种写法,将父表和所有子表的更新统一写到父表的deltaQuery语句,如下:
<document><entity name="product" query="SELECT * FROM t_product"deltaQuery="SELECT prod_id FROM t_product WHERE last_modify_time > '${dataimporter.last_index_time}'OR brand_id IN (SELECT id FROM t_brand WHERE last_modify_time > '${dataimporter.last_index_time}')OR prod_id IN (SELECT prod_id FROM t_prod_cat WHERE last_modify_time > '${dataimporter.last_index_time}'OR cat_id IN (SELECT id FROM t_cat WHERE last_modify_time > '${dataimporter.last_index_time}'))"deltaImportQuery="SELECT * FROM t_product WHERE prod_id='${dih.delta.prod_id}'"deletedPkQuery="SELECT prod_id FROM t_product WHERE isDelete='1'"pk="prod_id"><field column="prod_id" name="solr_prod_id"/><field column="name" name="solr_name"/><field column="simple_intro" name="solr_simple_intro"/><field column="price" name="solr_price"/><field column="uptime" name="solr_uptime"/><field column="brand_id" name="solr_brand_id"/><field column="last_modify_time" name="solr_last_modify_time"/><entity name="brand" query="SELECT name FROM t_brand WHERE id='${product.brand_id}'"><!-- 商品的品牌 --><field column="name" name="solr_brand_name"/></entity><entity name="product_cat" query="SELECT cat_id FROM t_prod_cat WHERE prod_id='${product.prod_id}'"><entity name="cat" query="SELECT name FROM t_cat WHERE id='${product_cat.cat_id}'"><!-- 商品的分类 --><field column="name" name="solr_cat_name"/></entity></entity></entity>
</document>
动态入参
如果DIH配置文件中需要使用请求时传入的参数,可以用${dataimporter.request.paramname}表示引用请求参数。
配置实例:
<dataSource driver="org.hsqldb.jdbcDriver" url="${dataimporter.request.jdbcurl}" user="${dataimporter.request.jdbcuser}" password="${dataimporter.request.jdbcpassword}" />
请求传参实例:
http://localhost:8983/solr/mycore/dataimport?command=full-import&jdbcurl=jdbc:hsqldb:./example-DIH/hsqldb/ex&jdbcuser=sa&jdbcpassword=secret
API接口
除了使用web控制台进行全量和增量的导入,还可以使用post工具。
全量导入
API接口:http://127.0.0.1:8983/solr/mycore/dataimport?command=full-import
会返回导入正在进行中的状态信息,导入会在一个新线程中开启(可能需要一定时间完成导入)。导入完成后,导入的开始时间将存入到conf/dataimport.properties文件中,用于后面的增量导入。增量导入完成后也会存入增量开始的时间到这个文件,用于下一次增量导入。全量导入期间并不会阻塞solr查询。
可以附加的参数如下:
- entity:指定导入 下的哪些实体(必须是直接子entity),如果没有给定该参数,则是其下所有子entity
- clean:指定是否在导入前清理索引,默认true
- commit:指定导入后是否提交,默认true
- optimize:是否进行优化,默认false
- debug:是否以调试模式运行,开发下使用,默认false。调试模式下不会提交,除非明确指定commit=true.
增量导入
API接口:http://127.0.0.1:8983/solr/mycore/dataimport?command=delta-import
支持的附加参数同全量导入
查看导入状态
API接口:http://127.0.0.1:8983/solr/mycore/dataimport?command=dataimport
导入是异步进行的,该命令可以查看导入的进度、状态信息
重新加载dih配置文件
API接口:http://127.0.0.1:8983/solr/mycore/dataimport?command=reload-config
终止当前操作
API接口:http://127.0.0.1:8983/solr/mycore/dataimport?command=abort
总结
- Solr支持从很多数据源导入数据
- Solr内部实现了很多处理器和转换器,在导入过程中,最重要的是编写dih-data-config.xml文件
- 参考地址:
http://lucene.apache.org/solr/guide/7_5/uploading-structured-data-store-data-with-the-data-import-handler.html
https://wiki.apache.org/solr/DataImportHandle
这篇关于Solr搜索引擎第九篇-DataImportHadler导入MySQL数据超详细的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





