本文主要是介绍洛谷 P1038 [NOIP2003 提高组] 神经网络【拓扑序处理】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原题链接:https://www.luogu.com.cn/problem/P1038
题目背景
人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。对神经网络的研究一直是当今的热门方向,兰兰同学在自学了一本神经网络的入门书籍后,提出了一个简化模型,他希望你能帮助他用程序检验这个神经网络模型的实用性。
题目描述
在兰兰的模型中,神经网络就是一张有向图,图中的节点称为神经元,而且两个神经元之间至多有一条边相连,下图是一个神经元的例子:
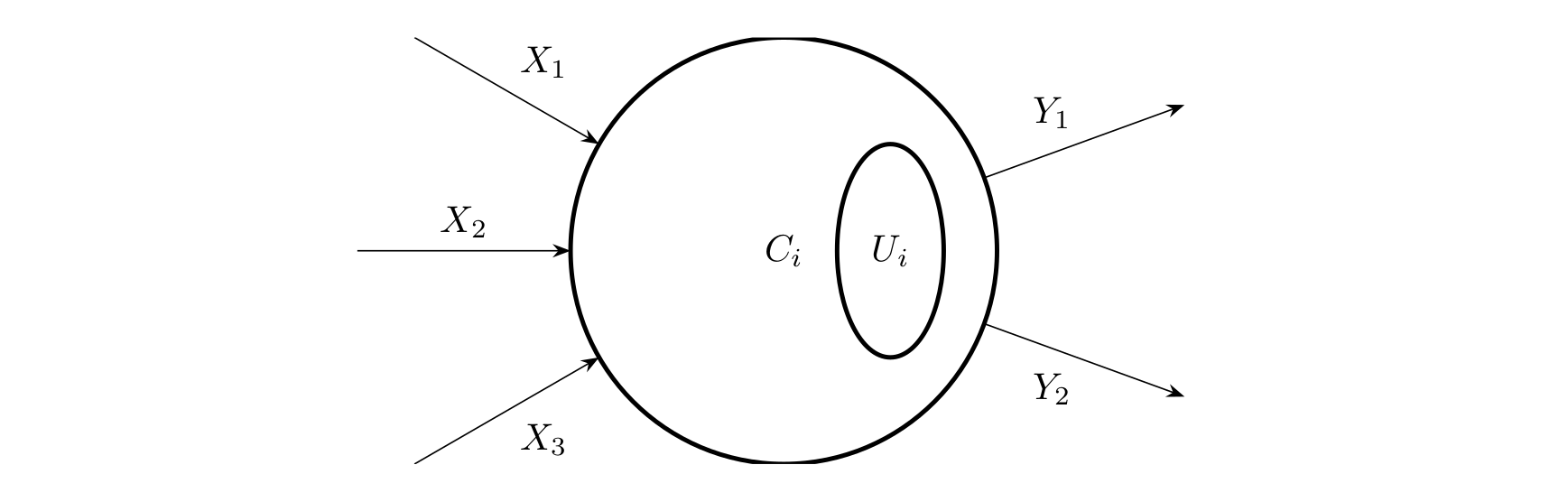
神经元(编号为 i)
图中,X1∼X3 是信息输入渠道,Y1∼Y2 是信息输出渠道,Ci 表示神经元目前的状态,Ui 是阈值,可视为神经元的一个内在参数。
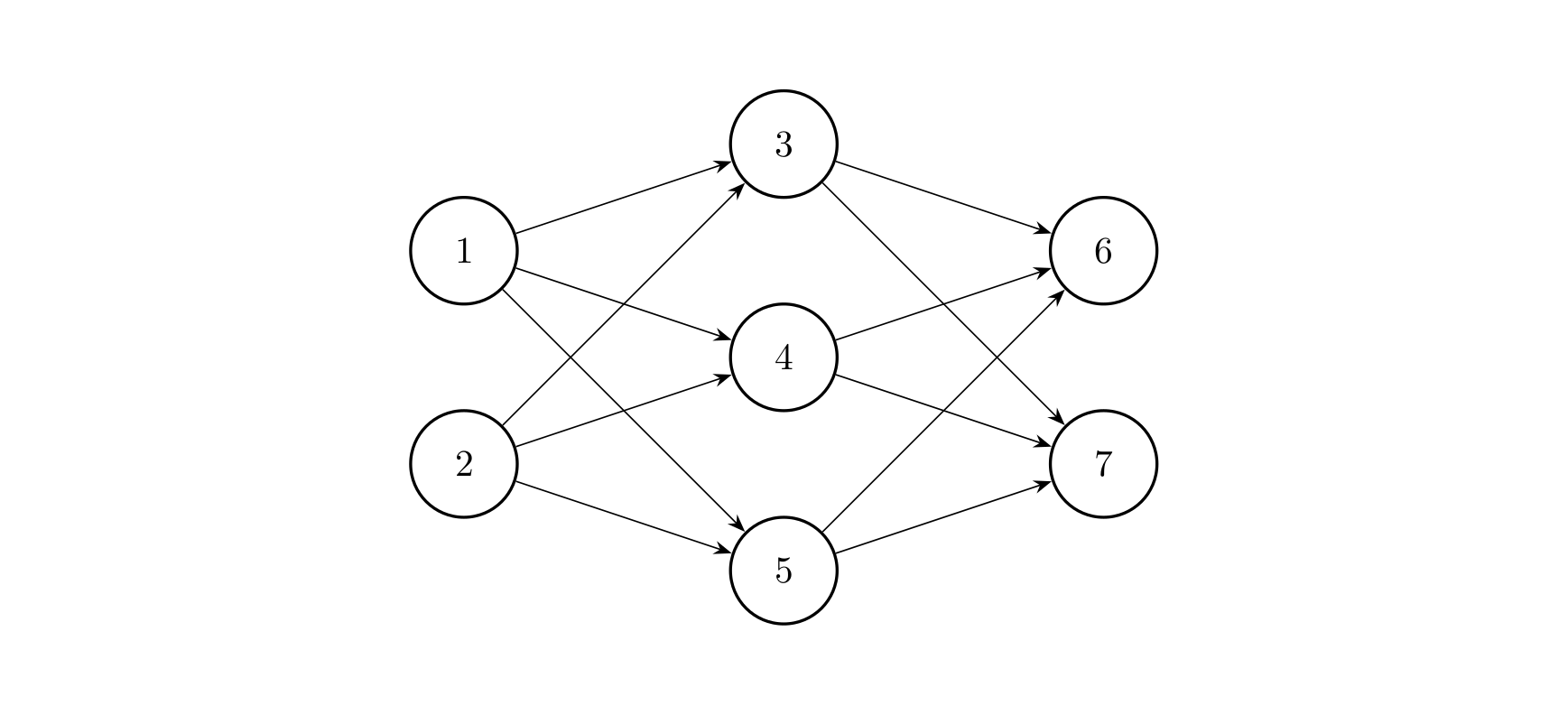
神经元按一定的顺序排列,构成整个神经网络。在兰兰的模型之中,神经网络中的神经元分为几层;称为输入层、输出层,和若干个中间层。每层神经元只向下一层的神经元输出信息,只从上一层神经元接受信息。下图是一个简单的三层神经网络的例子。
兰兰规定,Ci 服从公式:(其中 n 是网络中所有神经元的数目)
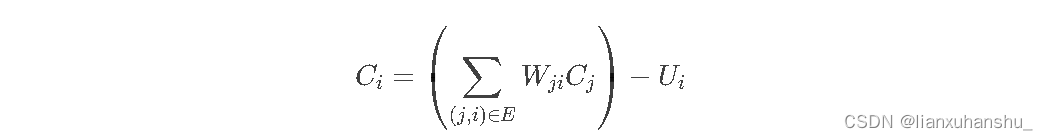
公式中的 Wji(可能为负值)表示连接 j 号神经元和 i 号神经元的边的权值。当 Ci 大于 0 时,该神经元处于兴奋状态,否则就处于平静状态。当神经元处于兴奋状态时,下一秒它会向其他神经元传送信号,信号的强度为 Ci。
如此.在输入层神经元被激发之后,整个网络系统就在信息传输的推动下进行运作。现在,给定一个神经网络,及当前输入层神经元的状态(Ci),要求你的程序运算出最后网络输出层的状态。
输入格式
输入文件第一行是两个整数 n(1≤n≤100)和 p。接下来 n 行,每行 2 个整数,第 i+1 行是神经元 i 最初状态和其阈值(Ui),非输入层的神经元开始时状态必然为 0。再下面 p 行,每行有两个整数 i,j 及一个整数 Wij,表示连接神经元i,j 的边权值为 Wij。
输出格式
输出文件包含若干行,每行有 2 个整数,分别对应一个神经元的编号,及其最后的状态,2 个整数间以空格分隔。仅输出最后状态大于 0 的输出层神经元状态,并且按照编号由小到大顺序输出。
若输出层的神经元最后状态均小于等于 0,则输出 NULL。
输入输出样例
输入 #1
5 6 1 0 1 0 0 1 0 1 0 1 1 3 1 1 4 1 1 5 1 2 3 1 2 4 1 2 5 1
输出 #1
3 1 4 1 5 1
说明/提示
【题目来源】
NOIP 2003 提高组第一题
解题思路:
这个题目题目背景比较复杂,然后题目也比较长,但是读完题目,你会发现,这就是一个拓扑序结构,然后给出了传递的规则和公式,所以我们直接根据拓扑序处理即可,思路是非常简单的,但是可能细节比较多,稍不注意就会出错,下面描述一下几个细节处理的地方。
细节1:输入层点的阈值U[i]是没有意义的,所以输入点的C[i]就是C[i],非输入点后面还要减去U[I],在前面减去和在后面减去是没有区别的,对于非输入层的点在输入的时候直接C[i]-=U[i]即可。
细节2:题目说了只有当i号点处理完之后,C[i]值为正i号点才能往后面进行传输,但是为了保证拓扑排序处理过程的正确进行,就算C[i]<=0我们也必须要将这个点i加入队列,我们只要不将C[i]*w[i]的值传输给后面的点即可。
时间复杂度:拓扑排序时间复杂度为O(n),链式向前星建图时间复杂度为O(n+m),其中n表示点数,m表示边数,所以时间复杂度为O(n+m)。
空间复杂度:O(n+m)。
cpp代码如下:
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>using namespace std;const int N = 110, M = N * N;int n, p;
int C[N], U[N];
int din[N], dout[N];
int h[N], w[M], e[M], ne[M], idx;void add(int a, int b, int c)
{e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx++;
}
void topsort()
{queue<int> q;for (int i = 1; i <= n; i++)if (!din[i])q.push(i);while (q.size()){int t = q.front();q.pop();for (int i = h[t]; i != -1; i = ne[i]){int j = e[i];din[j]--;if (C[t] > 0) //只要当C[i]值大于0,才往后面的点传输C[i]*w[i]的值{C[j] += C[t] * w[i];}if (!din[j])q.push(j);}}
}int main()
{cin >> n >> p;for (int i = 1; i <= n; i++){scanf("%d%d", &C[i], &U[i]);if (C[i] == 0)C[i] -= U[i]; //非输入层的点C[i]-=U[i]}memset(h, -1, sizeof h);for (int i = 0; i < p; i++) {int a, b, c;scanf("%d%d%d", &a, &b, &c);dout[a]++, din[b]++; //dout[i]表示点i的出度,din[i]表示点i的入读add(a, b, c), add(b, a, c);}topsort(); //拓扑排序vector<pair<int, int>> ans;for (int i = 1; i <= n; i++)if (dout[i] == 0 && C[i] > 0) //对于输出层的点,其中C[i]值大于0的点才是答案里面的点{ans.push_back({i, C[i]});}//输出答案if (ans.size() == 0){puts("NULL");}else{for (int i = 0; i < ans.size(); i++)printf("%d %d\n", ans[i].first, ans[i].second);}return 0;
}这篇关于洛谷 P1038 [NOIP2003 提高组] 神经网络【拓扑序处理】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




