本文主要是介绍为什么先进的 RAG 方法对 AI 的未来至关重要?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号(NLP Research),及时查看最新内容

原文标题:Why Are Advanced RAG Methods Crucial for the Future of AI?
原文地址:https://medium.com/towards-data-science/why-are-advanced-rag-methods-crucial-for-the-future-of-ai-462e0dc5a208
掌握先进的RAG技术:解锁AI驱动应用的未来
介绍
检索增强生成(RAG)是生成式人工智能领域的一大进步,它将高效的数据检索与大型语言模型的强大功能结合在一起。
RAG 的核心工作是利用向量搜索挖掘相关的现有数据,将这些检索到的信息与用户的查询结合起来,然后通过类似 ChatGPT 的大型语言模型进行处理。
这种 RAG 方法可确保生成的响应不仅精确,而且还能反映当前的信息,从而大大减少输出中的不准确或 “幻觉”。
然而,随着人工智能应用领域的不断扩大,对 RAG 提出的要求也变得更加复杂多样。基本的 RAG 框架虽然强大,但可能已不足以满足不同行业和不断发展的使用情境的细微需求。这就是高级 RAG 技术发挥作用的地方。这些增强的方法被量身定制以解决特定的挑战,在信息处理中提供更高的精度、适应性和效率。
了解 RAG 技术
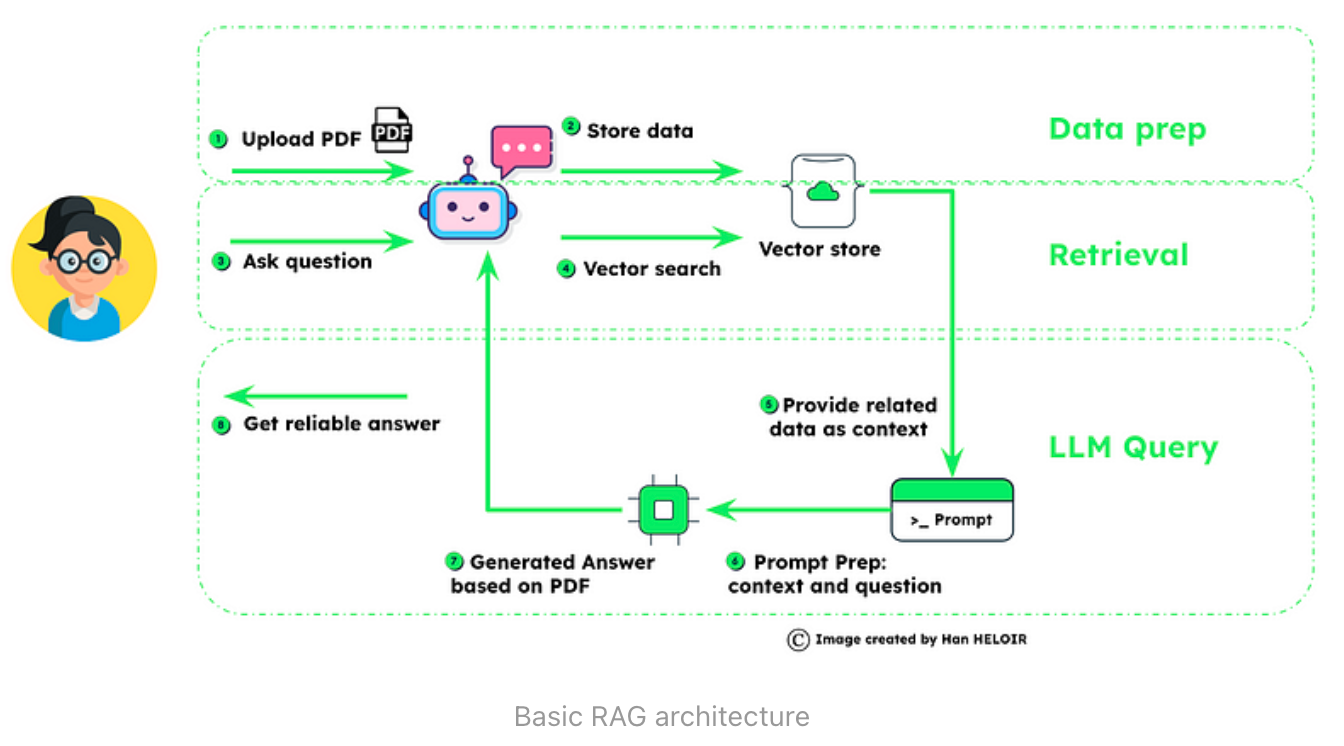
基本RAG的实质
检索增强生成(RAG)将数据管理与智能查询相结合,以提高人工智能的响应精度。
-
数据准备:首先是用户上传数据,然后对数据进行分块并用嵌入式技术存储,为检索奠定基础。
-
检索:一旦提出问题,系统就会利用矢量搜索技术对存储的数据进行挖掘,找出相关信息。
-
LLM 查询:检索到的信息被用于为语言模型 (LLM) 提供上下文,语言模型通过将上下文与问题相结合来准备最终的提示。结果是根据所提供的丰富的上下文数据生成答案,这证明 RAG 能够生成可靠、明智的答案。
整个过程如图所示,强调了 RAG 对可靠数据处理和根据上下文生成答案的重视,这对于高级人工智能应用至关重要。
随着人工智能技术的发展,RAG 的能力也在不断提高。先进的 RAG 技术层出不穷,不断突破这些模型所能达到的极限。这些进步不仅仅是更好的检索或更流畅的生成。它们包含一系列改进,包括增强对上下文的理解、更复杂地处理细微查询,以及无缝集成各种数据源的能力。
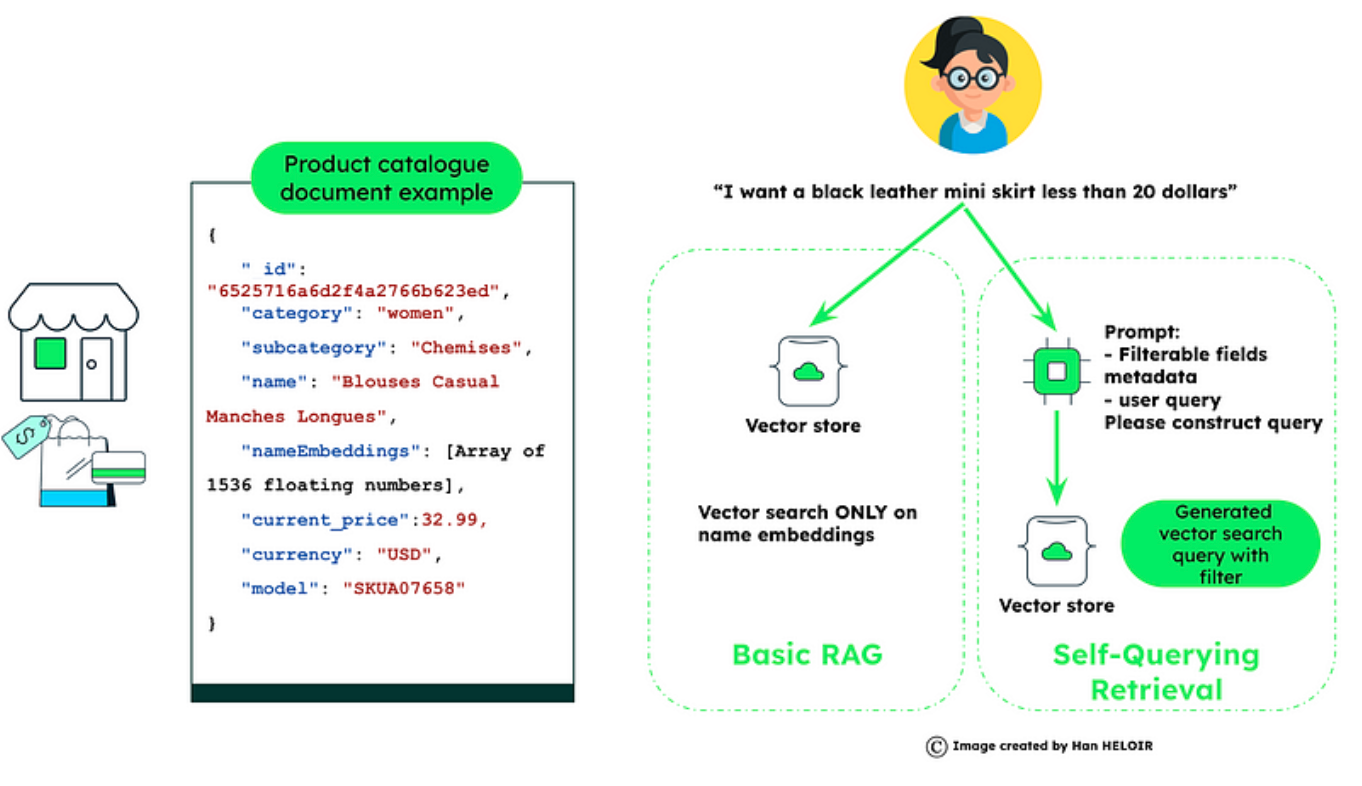
技术 1:Self-Querying Retrieval(自查询检索)
自查询检索是人工智能驱动的数据库系统中的一项前沿技术,它通过自然语言理解来增强数据查询功能。例如,如果您有一个产品目录数据集,您想搜索 “a black leather mini skirt less than 20 dollars”,您不仅要对产品描述进行语义搜索,还可以对产品的子类别和价格进行过滤。

-
Natural Language Query Processing(自然语言查询处理):首先由 LLM 解释用户的自然语言查询,提取意图和上下文。
-
Metadata Field Information(元数据字段信息):要实现这一点,必须预先提供文档中的元数据字段信息。这些元数据定义了数据的结构和属性,为构建有效的查询和筛选提供指导,确保搜索结果的准确性和相关性。
-
Query Construction(查询构建):接下来,LLM 会构建一个结构化查询,既包括用于向量搜索的语义元素,又包括用于提高精度的元数据过滤器。
-
Executing the Query(执行查询):该结构化查询应用于 MongoDB 的向量搜索,根据语义相似性和元数据相关性过滤结果。
通过从自然语言中构建结构化查询,自查询检索可同时考虑语义元素和元数据,从而确保数据获取的效率和精度。
import openai
import pymongo
from bson.json_util import dumps# OpenAI API key setup
openai.api_key = 'your-api-key'# Connect to MongoDB
client = pymongo.MongoClient('mongodb://localhost:27017/')
db = client['your_database']
collection = db['your_collection']# Function to use GPT-3.5 for interpreting natural language query and outputting a structured query
def interpret_query_with_gpt(query):response = openai.Completion.create(model="gpt-3.5-turbo",prompt=f"Translate the following natural language query into a MongoDB vector search query:\n\n'{query}'",max_tokens=300)return response.choices[0].这篇关于为什么先进的 RAG 方法对 AI 的未来至关重要?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






