本文主要是介绍OpenShift Metrics(监控)部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenShift Metrics(监控)采用Kubernetes原生的kubelet api提供数据,然后使用 heapster进行收集存储到cassandra数据库中,这些监控数据最主要是用来进行 pad autoscalers。
一、准备工作
先在Master节点上安装1.8版本的JDK,并将其添加到PATH环境变量中。
二、切换项目到 openshift-infra
| [root@ocp ~]# oc project openshift-infra Now using project "openshift-infra" on server "https://ocp.192.168.40.141.nip.io:8443". |
三、通过 Ansible playbook 安装 OpenShift metrics
| ansible-playbook -i /etc/ansible/inventory.ini openshift-ansible/playbooks/openshift-metrics/config.yml -e openshift_metrics_install_metrics=True -e openshift_metrics_hawkular_hostname=hawkular-metrics.192.168.40.141.nip.io -e openshift_metrics_start_cluster=True -e openshift_metrics_duration=1 -e openshift_metrics_image_version=v3.9 |
参数说明:
- openshift_metrics_install_metrics=True:安装监控
- openshift_metrics_hawkular_hostname=hawkular-metrics.192.168.40.141.nip.io:指定访问域名
- openshift_metrics_image_version=v3.9:指定镜像版本,此处一定要指向该版本,否则默认会去拉v3.9.0的tag,但是docker hub里面没有这个tag。
- openshift_metrics_start_cluster=True:是否集群启动之后就开始数据收集
- openshift_metrics_duration=1:数据保留多长时间
- openshift_metrics_cassandra_storage_type=dynamic:动态分配pvc
四、Ansible playbook安装结束
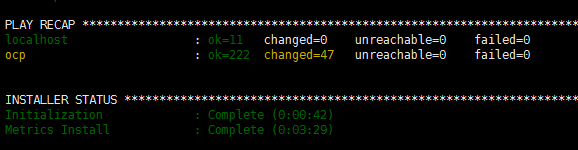
五、等待pod启动完成并查看部署情况

提示:运行监控的这三个模块很耗费资源,在第一次安装的时候,由于内存不足,导致三个容器没有一个启动成功的,最后只能将VMware的虚拟机内存增加到8G之后,才勉强运行起来。
六、Web端验证
由于3.9的web-console采用pod部署,配置文件在config map里面,所以在部署完监控之后会自动更新web-console的config map添加一条 metricsPublicURL:https://hawkular-metrics.192.168.40.141.nip.io/hawkular/metrics信息。
此时pod页面是还没有metrics选项的,有几种解决方法使更改的config map生效:
1、等一会,自动更新生效
2、干掉pod,重新生成
3、委婉一点,将副本数改为0,然后再设置为1
刷新页面,metrics选项就出来了
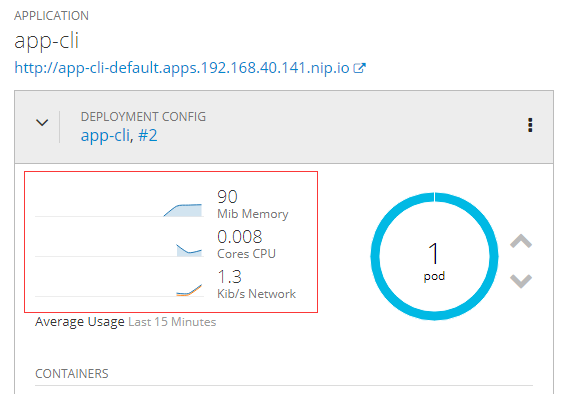
这篇关于OpenShift Metrics(监控)部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








