本文主要是介绍【Linux系统化学习】深入理解匿名管道(pipe)和命名管道(fifo),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
进程间通信
进程间通信目的
进程间通信的方式
管道
System V IPC(本地通信)
POSIX IPC(网络通信)
管道
什么是管道
匿名管道
匿名管道的创建
匿名管道的使用
匿名管道的四种情况
匿名管道的五种特性
命名管道
指令级的命名管道
代码级的命名管道
读端
写端
匿名管道与命名管道的区别

进程间通信
从Linux这个专栏开始我们已经系统学习了两大块内容——进程和文件系统。但是内存中的文件离不开进程;因此可见进程的重要性,但是我们只是对单一的一个进程进行研究。可实际我们总能发现需要将一个程序的输出交给另一个程序进行处理,这就是进程间的通信;但是进程具有独立性,我们不可以将一个进程的数据拷贝给另一个进程,因此两个进程通信必须含有一个中间媒介用于音系交流。
进程间通信的本质就是:让不同的进程先看到同一份资源。
进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信的方式
管道
- 匿名管道pipe
- 命名管道FIFO
System V IPC(本地通信)
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC(网络通信)
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
管道
什么是管道
- 管道是Unix中最古老的进程间通信的形式。
- 我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
注意:是因为含有一种数据的传送方式类似管道才有的管道,而不是因为管道这个名词而建立的一种数据传送方式。(注意这两种的因果关系)


匿名管道
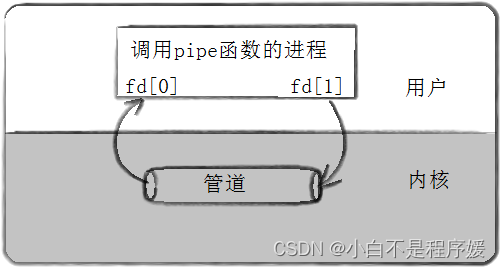
匿名管道的创建
#include<unistd.h>
int pipe(int fd[2]);功能:创建一个匿名管道
参数
- fd:文件描述符数组,其中fd[0]表示读端,fd[1]表示写端
- 返回值:成功返回0,失败返回错误码。
匿名管道的使用
#include<iostream>
#include<cstring>
#include<unistd.h>
#include<cassert>
#include<wait.h>
using namespace std;
#define MAX 1024int main()
{//第一步,建立管道int fd[2]={0};int n = pipe(fd);assert(n==0);(void)n;//第二步,创建子进程pid_t id = fork();if(id<0){perror("fork");return 1;}//子写父读//第三步:父子双方关闭不需要的fd,形成单行通道if(id==0){//childclose(fd[0]);char massage[MAX];int cnt =10;while(cnt){snprintf(massage,sizeof(massage),"I am a child , pid : %d ppid : %d cnt : %d ",getpid(),getpid(),cnt--);// w - 只向管道写入write(fd[1],massage,strlen(massage));sleep(1);}exit(0);}//fatherclose(fd[1]);char buffer[MAX];while(true){// r - 只从管道读取ssize_t n = read(fd[0],buffer,sizeof(buffer)-1);if(n>0){buffer[n]={0};cout<<getpid()<<"child say:"<<buffer<<endl;}sleep(1);}pid_t rid = waitpid(id,nullptr,0);if(rid==id){cout<<"wait success"<<endl;}return 0;
}
现象的解释:
在创建子进程前,建立管道;然后创建子进程,父进程关闭写端只做读取,子进程关闭读端只做写入;通过管道子进程写入的数据通过管道被父进程读取。
匿名管道的四种情况
1. 正常情况,如果管道没有数据了,读端必须等待,直到有数据为止(写端写入数据了)
2. 正常情况,如果管道被写满了,写端必须等待,直到有空间为止(读端读走数据)
3. 写端关闭,读端一直读取, 读端会读到read返回值为0, 表示读到文件结尾
4. 读端关闭,写端一直写入,操作系统会直接杀掉写端进程,通过想目标进程发送SIGPIPE(13)信号,终止目标进程。
匿名管道的五种特性
1. 匿名管道,可以允许具有血缘关系的进程之间进行进程间通信,常用与父子,仅限于此
2. 匿名管道,默认给读写端要提供同步机制
3. 面向字节流的
4. 管道的生命周期是随进程的
5. 管道是单向通信的,半双工通信的一种特殊情况
从文件描述符的角度来理解管道的原理
管道的原理需要结合文件系统来描述。当进程分别以读和写打开同一个文件,进程会创建PCB;PCB含有指向关于该进程打开的所有文件信息结构体(struct files_struct)的指针(struct files_struct*),这个结构体中含有一个数组,数组的每个下标代表所打开的每个文件,数组的每个元素为一个指针(struct file* fd——array[])指向被打开的文件;读和写在内存中都会加载该内存,在内存中虽然有两个文件但是这两个文件公用一个缓冲区。当fork()创建子进程的时候,会发生浅拷贝;因此子进程中的所有数据和父进程是一样的,包括指针信息。子进程中数组元素也是指向父进程所打开的读写文件,这两个文件又公用一个缓冲区;这两个文件被连个指针所指向,使用引用计数而实现需不需要文件的关闭。关闭父进程的写文件和关闭子进程的的读文件,这样子进程将信息写到缓冲区中,父进程将数据自己读取,不加载到内存中,这样就实现了管道。

命名管道
- 匿名管道的一个限制就是只能在具有共同祖先(具有血缘关系)的进程间通信
- 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
- 命名管道是一种特殊类型的文件
指令级的命名管道
命名管道可以在命令行上创建,使用下面指令:
mkfifo 文件名

现象的解释:这个过程是动态的,由于动图太大不方便演示。在一个文件夹中创建了一个管道文件。echo指令进行循环写入,在另一个端口下cat命令进行读取。通过这个管道文件实现了两个不相关进程之间的通信。这个管道文件为中间媒介是实现了两个进程间的通信。
代码级的命名管道
管道也可以在程序里创建,相关函数为:
int mkfifo(const char *filename,mode_t mode)其实命名管道就是个文件,在一个进程中创建这个文件,进行写入/读取,或者在同时在另一个文件中进行读取和写入操作,本质就是:两个不同的进程同时对同一个文件进行文件操作。这个文件就实现了进程间的通信,这个文件就是管道。
读端
在程序的一开始,直接打开这个文件;当文件不存在时创建这个管道文件,直到创建成功为止;
然后使用系统调用文件操作读函数,对文件进行读取。
#include <iostream>
#include <cstring>
#include <cerrno>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "RW.h"bool MakeFifo()
{int n = mkfifo(FILENAME, 0666);if(n < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;return false;}std::cout << "mkfifo success... read" << std::endl;return true;
}int main()
{
Start:int rfd = open(FILENAME, O_RDONLY);if(rfd < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;if(MakeFifo()) goto Start;else return 1;}std::cout << "open fifo success..." << std::endl;char buffer[1024];while(true){ssize_t s = read(rfd, buffer, sizeof(buffer)-1);if(s > 0){buffer[s] = 0;std::cout << "Client say# " << buffer << std::endl;}else if(s == 0){std::cout << "client quit, server quit too!" << std::endl;break;}}close(rfd);std::cout << "close fifo success..." << std::endl;return 0;
}写端
也是在程序一开始直接打开指定的管道文件,判断是否打开成功;打开成功后使用你系统调用文件操作写函数对文件进行写入。
#include <iostream>
#include <cstring>
#include <cerrno>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "RW.h"int main()
{int wfd = open(FILENAME, O_WRONLY);if (wfd < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;return 1;}std::cout << "open fifo success... write" << std::endl;std::string message;while (true){std::cout << "Please Enter# ";std::getline(std::cin, message);ssize_t s = write(wfd, message.c_str(), message.size());if (s < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;break;}}close(wfd);std::cout << "close fifo success..." << std::endl;return 0;
}
现象的解释:当我们同时在两个窗口运行这两个可执行程序时,在写端写入回车成功后;将数据写到管道文件中,当读端检测到管道文件中数据时会将这条消息读取。其实这个过程是同步进行的,由于这里动图太大,不方便演示。
从底层来看命名管道的原理和匿名管道的原理基本相同这里就不过多赘述了。
匿名管道与命名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,打开用open
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的意义。
今天对Linux下管道实现进程间通信的分享到这就结束了,希望大家读完后有很大的收获,也可以在评论区点评文章中的内容和分享自己的看法;个人主页还有很多精彩的内容。您三连的支持就是我前进的动力,感谢大家的支持!!!
这篇关于【Linux系统化学习】深入理解匿名管道(pipe)和命名管道(fifo)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









