本文主要是介绍leetcode练习之商品折扣后的最终价格(单调栈算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目描述
给你一个数组 prices ,其中 prices[i] 是商店里第 i 件商品的价格。
商店里正在进行促销活动,如果你要买第 i 件商品,那么你可以得到与 prices[j] 相等的折扣,其中 j 是满足 j > i 且 prices[j] <= prices[i] 的 最小下标 ,如果没有满足条件的 j ,你将没有任何折扣。
请你返回一个数组,数组中第 i 个元素是折扣后你购买商品 i 最终需要支付的价格。
测试用例
输入:prices = [8,4,6,2,3]
输出:[4,2,4,2,3]
解释:
商品 0 的价格为 price[0]=8 ,你将得到 prices[1]=4 的折扣,所以最终价格为 8 - 4 = 4 。
商品 1 的价格为 price[1]=4 ,你将得到 prices[3]=2 的折扣,所以最终价格为 4 - 2 = 2 。
商品 2 的价格为 price[2]=6 ,你将得到 prices[3]=2 的折扣,所以最终价格为 6 - 2 = 4 。
商品 3 和 4 都没有折扣
解题方法
1. 直接两层循环遍历判断即可
代码示例:
class Solution {public int[] finalPrices(int[] prices) {for(int i = 0; i < prices.length; i++) {for(int j = i + 1; j < prices.length; j++) {if(prices[i] >= prices[j]) {prices[i] -= prices[j];break;}}}return prices;}
}
时间复杂度:O(N ^ 2)
空间复杂度:O(1)
2.单调栈
解题思路:
我们无非是要找到在自己后面比自己小并且离自己最近的一个值作为折扣,因此我们就可以维护一个栈,栈内的数据记录了从自己之后的第一个数据到最后一个数据之间的一些数据,这些数据有一个规律,从栈顶到栈底,数据是递减的,为什么?
以上面的测试用例为例:[8,4,6,2,3],当我们遍历到数据8时,栈中的数据从栈顶到栈底应该是[4,2],原因就是在我们看来,4比6小,那么如果6比8小的话,4一定比8小,意思是6这个数据压根没用,有用的应该是比4还小的数据,因此后面还有一个2,3也是同理,3比2还大,那3也就没用了
我们要维护一个这样的栈,就必须从后往前遍历,而如果从后往前开始遍历,为了便于理解,因此我们不在原数组进行修改,重新新建一个数组,遍历到每个数据时,栈的情况如下图所示:
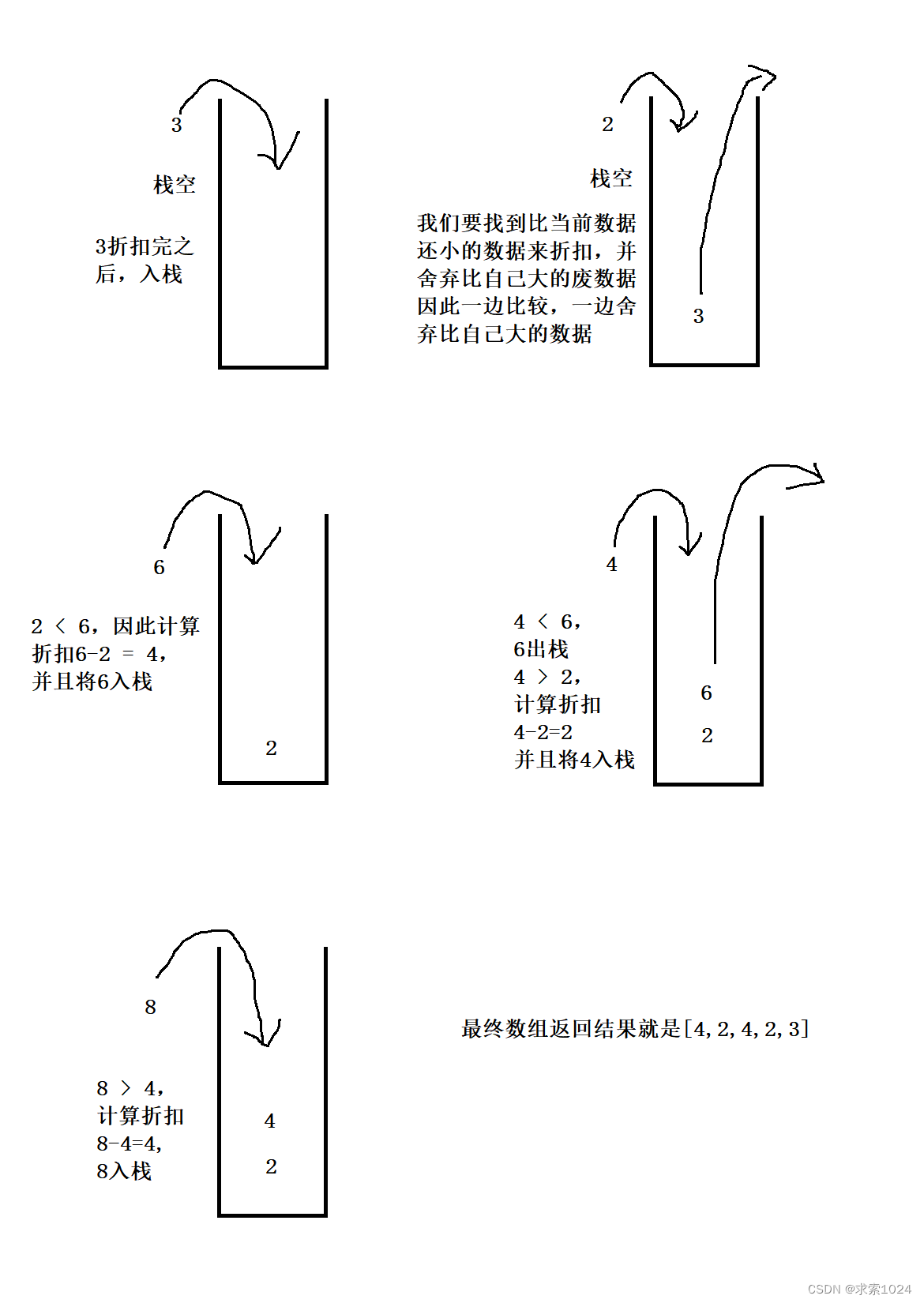
代码示例:
class Solution {public int[] finalPrices(int[] prices) {int len = prices.length;int[] ans = new int[len];Stack<Integer> stack = new Stack<>();for(int i = len - 1; i >= 0; i--) {while(!stack.empty() && stack.peek() > prices[i]) {stack.pop();}ans[i] = stack.empty() ? prices[i] : prices[i] - stack.peek();stack.push(prices[i]);}return ans;}
}
时间复杂度:O(N)(最多只遍历两遍)
空间复杂度:O(N)
这篇关于leetcode练习之商品折扣后的最终价格(单调栈算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









