本文主要是介绍【MySQL高可用集群】MySQL的MGR搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情提要:
MySQL官方在 5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR),使用类似 zookeeper 的多于一半原则。在一个集群由 2N+1 个节点共同组成一个复制组,一个事务的提交,必须经过 N+1 (也就是集群节点数 / 2+ 1)个节点决议并通过后才可以提交。这是目前 MySQL 数据库高可用与高扩展的最优解决方案。MGR有以下几个限制条件:
1、存储引擎必须为Innodb,即仅支持InnoDB表
2、每张表必须有主键,用于做write set的冲突检测
3、不支持外键于save point特性,无法做全局间的约束检测与部分部分回滚
4、必须开启GTID特性,二进制日志格式必须设置为ROW,用于选主与write set
5、二进制日志binlog不支持Replication event checksums
6、多主模式(也就是多写模式) 下:不支持SERIALIZABLE事务隔离级别,不完全支持级联外键约束,不支持在不同节点上对同一个数据库对象并发执行DDL
8、只支持ipv4网络,最多支持9个节点
一、环境准备
Ubuntu 22.04 LTS (三台虚拟机),每台上面安装MySQL 8.0.33。
分别在每个节点配置 /etc/hosts 主机域名映射。
IP 主机名
10.53.207.20 master1
10.53.207.21 slave1
10.53.207.22 slave2关闭 ubuntu 防火墙或者设置三个节点进白名单。
二、MySQL配置文件设置
分别在三个节点进行配置,内容基本相同,只有server_id、report_host、group_replication_local_address 值不同。它们在三个接点的值分别设置如下:
10.53.207.20:server_id=20;report_host = 10.53.207.20,group_replication_local_address = "10.53.207.20:33061"
10.53.207.21:server_id=21;report_host = 10.53.207.21;group_replication_local_address = "10.53.207.21:33061"
10.53.207.22:server_id=22;report_host = 10.53.207.22;group_replication_local_address = "10.53.207.22:33061"
属性 group_replication_bootstrap_group 配置是否引导组复制,如果某个节点设置此属性为ON,则先启动此节点创建一个组服务并成为 master 节点,接受其他后启动节点加入组复制集群。
如果属性 group_replication_single_primary_mode =ON,则其他后启动组复制服务的节点会以slave 节点的身份自动加入复制组 ,最终组成一主多从集群。如果属性 group_replication_single_primary_mode =OFF,则其他后启动组复制服务的节点会以master 节点的身份自动加入复制组 ,最终组成多主集群。复制组白名单group_replication_ip_whitelist 在 8.03以后变为group_replication_ip_allowlist,配置形式可以直接使用ip地址或者C类ip地址[C类的为255.255.255.0(/24)]表示,例如 10.53.207.20/24 表示 10.53.207.x 的地址都可访问。
[mysqld]
#禁止 MGR 不支持的引擎
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
server_id=20
report_host = 10.53.207.20
#GTID
gtid_mode=ON
enforce_gtid_consistency=ON
#binlog
#log_bin=binlog
binlog_format=ROW
expire_logs_days=10
binlog_ignore_db = mysql
binlog_ignore_db = information_schema
binlog_ignore_db = performance_schema
binlog_ignore_db = sys
#relaylog
relay_log_info_repository=TABLE
relay_log_recovery = 1
log_slave_updates=ON
master_info_repository=TABLE
#指示Server必须为每个事务收集写集合,并使用XXHASH64哈希算法将其编码为散列
transaction_write_set_extraction=XXHASH64
#MGR
#服务启动加载安装复制组插件
plugin_load_add='group_replication.so'
#复制组名称确保每个机器都一样,可以用“select uuid()”生成
group_replication_group_name="35693218-3d99-11ee-a7ba-489ebd770e95"
#MySQL启动时是否自动启动组复制
group_replication_start_on_boot=OFF
#当前主机的主机名和复制组端口
group_replication_local_address= "10.53.207.20:33061"
#复制组的成员信息
group_replication_group_seeds= "10.53.207.20:33061,10.53.207.21:33061,10.53.207.22:33061"
#复制组白名单
group_replication_ip_whitelist = '10.53.207.20,10.53.207.21,10.53.207.22'
#是否引导组服务,如果开启每次重启都会创建新的复制组,所以配置文件中一定要关闭
group_replication_bootstrap_group=OFF
#是否单主模式,默认是
#group_replication_single_primary_mode=ON
#多主模式下,强制检查每一个实例是否允许写操作,默认关闭
#group_replication_enforce_update_everywhere_checks=OFF配置完之后在centos命令进行重启服务:
systemctl restart mysqld登录MYSQL:
mysql -uroot -pMySQL中查看组复制插件是否安装:
show plugins;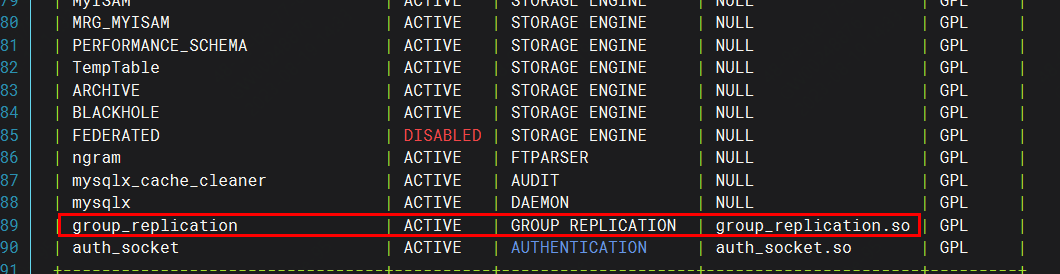
由图可知插件已经正常安装。
本实例是通过在 my.cnf 中添加 plugin_load_add='group_replication.so' 配置,在mysql 服务启动时自动安装。还有另外一种安装方式是通过MySQL命令行进行安装(命令行安装后必须重启):
INSTALL PLUGIN group_replication SONAME 'group_replication.so';三、MGR集群的配置和启动。
1、分别在三个节点执行以下SQL命令:
创建集群数据同步账户
SET SQL_LOG_BIN=0;
CREATE USER 'repl'@'10.53.207.%' IDENTIFIED BY 'P@repl';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'10.53.207.%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;为组复制通道指定账号密码
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='P@repl' FOR CHANNEL 'group_replication_recovery';2、启动组复制:
10.53.207.20 作为引导节点启动组复制服务,此节点将作为主节点接收其他节点加入集群。
SET GLOBAL group_replication_single_primary_mode=ON; # ON单主模式(如果是单主模式则当前引导节点为master,其他加入节点为slave)。OFF 多主模式(所有节点都是master)
SET GLOBAL group_replication_bootstrap_group=ON; #开启节点的引导模式,创建复制组并接受其他节点加入复制组
START GROUP_REPLICATION; #开启组复制数据同步服务
SET GLOBAL group_replication_bootstrap_group=OFF; #将当前节点设置为引导节点后关闭查看组复制信息:
SELECT * FROM performance_schema.replication_group_members;
然后启动另外两个节点(暂且叫做从节点以示区分)组复制服务加入集群,直接执行下面一条命令即可:
START GROUP_REPLICATION;发现报错了,报错如下(这是本人遇到的错误,读者朋友如果正常启动可以忽略下面异常相关的步骤):

查看日志详情:
Can't start group replication on secondary member with single-primary mode while asynch
ronous replication channels are running
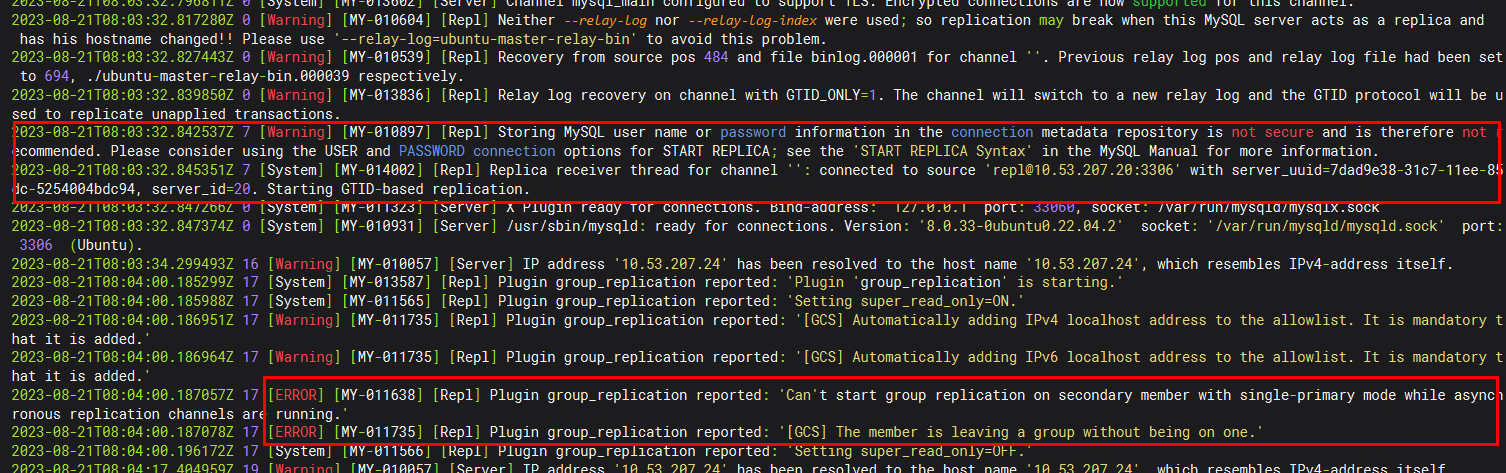
网上各种查资料都找不到原因,来来回回折腾好久。仔细看了日志,发现当前节点貌似连接到了一个空的channel上面,看下面这个日志:
Replica receiver thread for channel '': connected to source 'repl@10.53.207.20:3306' with server_uuid=7dad9e38-31c7-11ee-85
dc-5254004bdc94, server_id=20. Starting GTID-based replication.
这时恍然大悟,之前用这个节点做过基于GTID 的主从同步,然后通过 show slave status\G 查看了下,果然有相关信息,那就好办了,在两个从节点执行下面命令:
#停止数据同线程
stop slave;
#清理并重置binlog
reset master;
#启动组复制线程
start group_replication一切OK!注意reset master 生产环境不要使用,这是集群初始搭建重置binlog。
查看MGR集群状态:
SELECT * FROM performance_schema.replication_group_members;
如果要运行多主集群,需要在启动时设置每个节点的下列属性值。(可以通过配置文件设置,但建议通过命令行设置,这样就可以在线进行多主和单主模式的切换)
SET GLOBAL group_replication_single_primary_mode=OFF;
SET GLOBAL group_replication_enforce_update_everywhere_checks=true;四、集群监控
MySQL 的 performance_schema 库中记录了MGR集群的相关运行状态,相关表查看:
use performance_schema;
show tables like '%replication_group%';replication_group_members:记录组复制成员的实时状态,其中字段 MEMBER_STATE 有 5 种,分别是:ONLINE(在线)、OFFLINE(离线)、RECOVERING(恢复中)、ERROR(发生错误) 和 UNREACHABLE(无法通信)。
replication_group_member_stats :记录组复制中每个成员事务的验证和应用的统计信息。
replication_connection_status:复制组中连接状态信息,处理事务的 I/O 线程状态,以及 clone 通道状态信息。
五、集群验证
在 primary节点(10.53.207.20)执行命令:stop group_replication,此节点变为OFFLINE状态,在另外两个节点查看MGR集群状态,如下图。主节点 primary 从 10.53.207.20 变为了 10.53.207.21,说明主从切换成功。再重启 10.53.207.20 节点的组复制服务 start group_replication,发现它会作为从节点加入集群。

在primary节点进行数据的更新,会同步至其他节点。
至此,MGR 集群搭建完成!
这篇关于【MySQL高可用集群】MySQL的MGR搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






