本文主要是介绍第3.4章:StarRocks数据导入——Routine Load,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:本篇文章阐述的是StarRocks-3.2版本的Routine Load导入机制
一、概述
Routine Load(例行导入)支持用户提交一个常驻的导入任务,可以将消息流存储在 Kafka 的Topic中,通过订阅Topic 中的全部或部分分区的消息,从而实现数据不间断的导入至 StarRocks。(Routine Load任务是常驻进程)
Routine Load 支持 Exactly-Once 语义,能够保证数据不丢不重。支持从Kakfa集群中消费 CSV、JSON、Avro (自 v3.0.1) 格式的数据。
官网文档地址:
使用 Routine Load 导入数据 | StarRocks
CREATE ROUTINE LOAD | StarRocks
总结:通过在数据库侧建立常驻消费者进程来拉取位于流系统上的数据,该消费者进程会按照定义好的消费逻辑和间隔,攒批数据之后调用stream load导入机制来实现数据导入。
二、Routine Load原理
2.1 流程图
Routine Load的导入执行流程如下:
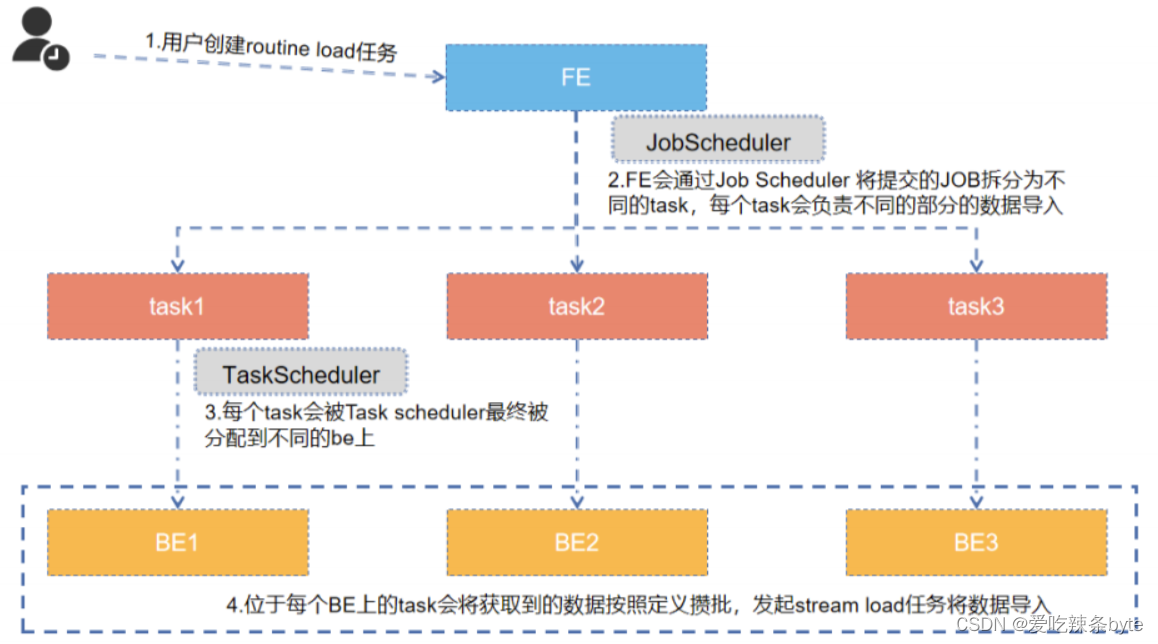
2.2 流程详解
(1)用户通过客户端发起创建routine load任务的请求
(2)FE在收到请求后,会将请求任务通过Job Scheduler将任务拆分成若干个Task,每个Task被TaskScheduler分配到指定的BE上执行
- 拆分规则:
- FE 根据期望任务并行度
desired_concurrent_number、Kafka Topic 的分区数量、存活 BE 数量等,计算得出实际任务并行度。- FE 根据实际任务并行度将导入作业分为若干导入任务,放入任务执行队列中。
- 每个topic会有多个分区,分区与导入任务之间的对应关系为:
- 每个分区的消息只能由一个对应的导入任务消费(一个分区只能由一个消费者消费)
- 一个导入任务可能会消费一个或多个分区(一个分消费者可以消费一个或多个分区)
- 分区尽可能均匀的分配给导入任务(kafka分区数尽量等于消费者数)
(3)拆分的每个task会被Task Scheduler调度到不同的BE节点上执行
即:多个导入任务并行进行,消费kafka多个分区的消费,导入至StarRocks
- 调度和提交导入任务
FE定时调度任务会去执行队列中的导入人物,分配给选定的 Coordinator BE。调度导入任务的时间间隔由
max_batch_interval参数空值。并且 FE 会尽可能均匀地向所有 BE 分配导入任务
- 执行导入任务
Coordinator BE 执行导入任务,消费分区的消息,解析并过滤数据。导入任务需要消费足够多的消息,或者消费足够长时间。
消费时间和消费的数据量由 FE 配置项
routine_load_task_consume_second、max_routine_load_batch_size决定。Coordinator BE将消息分发至相关Executor BE 节点,BE 节点将消息写入磁盘。
(4)位于每个BE节点的Task 任务会按照预先定义好的消费逻辑,数据攒批后调用stream load任务,完成对应批次数据的导入
(5)持续生成新的导入任务,不间断地导入数据
Executor BE 节点成功写入数据后, Coordonator BE 会向 FE 汇报导入结果。FE根据汇报结果,继续生成新的导入任务,或者对失败的导入任务进行重试,连续地导入数据,并且能够保证导入数据不丢不重。
总结:可以将上述的执行流程理解为一个个不断调度执行的Stream Load任务。在默认参数下,一个Stream Load任务被拆分成若干个Task,Task被调度后,开始对kafka进行为期15秒①的数据消费,并现在内存中攒批,15秒过后这批数据通过Stream Load的方式导入到对应数据表中,任务完成后向FE汇报,然后间隔10秒后②,Task被再次调度,如果循环进行。从Task被调度到本次Stream Load任务完成,整个过程的超时时间默认限制是60秒③。FE收到任务汇报结果后,会继续生成后续新的Task,或者对失败的Task进行重试(最多重试3次,都失败则任务暂停)。整个Stream Load作业通过不断的产生新的Task,来完成数据不间断的导入。
上述提到的三个时间参数可以结合实际的业务情况来修改:
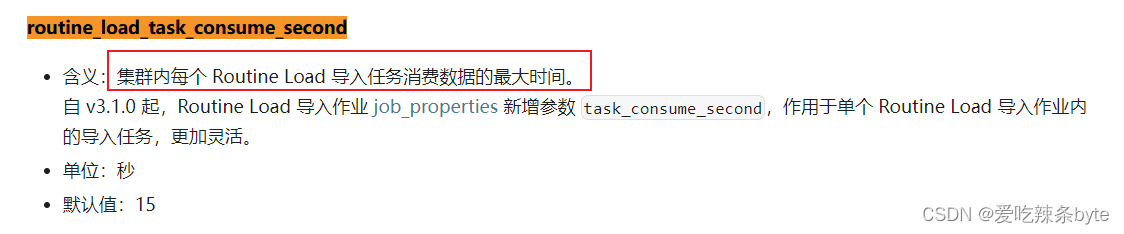
①:集群内每个Routine Load导入任务消费数据的最大时间,通过fe.conf中的routine_load_task_consume_second参数设置,默认为15s。(调整后需要重启 FE 使变更生效。)
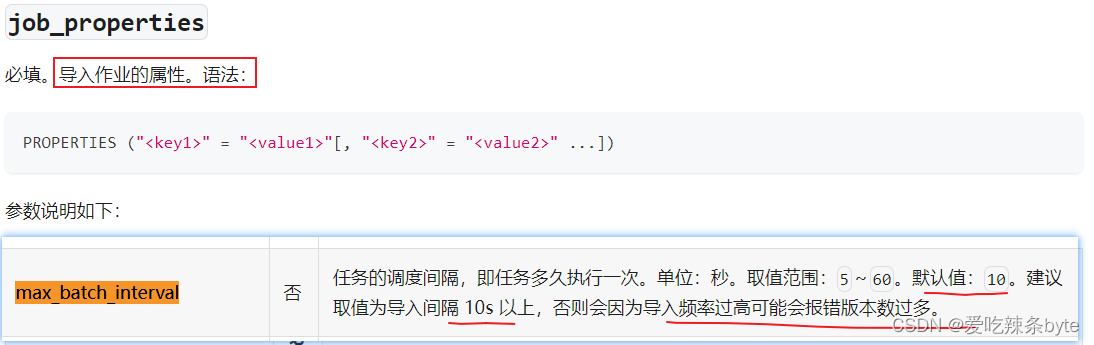
②:子任务调度周期,在Routine Load语句中设置,参数max_batch_interval,默认为10秒。缩短任务调度周期可以加速数据消费,但是更小的任务调度周期也可能会带来更多的CPU资源消耗,还可能会导致Compaction的问题。
③:集群内部所有Routine Load任务的执行超时时间:由fe.conf中的task_timeout_second控制,默认为60s

2.3 注意事项
-
Routine Load本质上还是调用的Stream load任务,需要注意攒批频次的设置,不能太过于频繁的去调用,避免未合并的版本数超限(compaction合并问题)。
-
Routine Load任务的消费频次:根据消息的峰值变化速率来设定不同任务的消费频次。
-
过多的Routine Load任务会占用一定的硬件资源,会导致查询性能的下降。(Routine Load任务是常驻进程)
2.4 应用案例
Routine Load导入案例,见文章:
第3.3章:StarRocks数据导入--Routine Load-CSDN博客
参考文章:
https://blog.csdn.net/ult_me/article/details/122865142?spm=1001.2014.3001.5501
这篇关于第3.4章:StarRocks数据导入——Routine Load的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





