本文主要是介绍Python 数据可视化之密度散点图 Density Scatter Plot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
密度散点图(Density Scatter Plot),也称为密度点图或核密度估计散点图,是一种数据可视化技术,主要用于展示大量数据点在二维平面上的分布情况。与传统散点图相比,它使用颜色或阴影来表示数据点的密度,从而更直观地展示数据的分布情况。密度散点图能更好地揭示数据的集中趋势和分布模式,尤其是在数据量非常大时,避免了散点图中点重叠导致的可视化混乱问题。
密度散点图涉及的基础概念:
-
散点图(Scatter Plot):基础的二维数据表示形式,用于展示两个变量之间的关系。每个数据点的位置由这两个变量的值决定。当数据量庞大时,很多点会重叠在一起,使得无法清晰看到数据的分布。
-
核密度估计(Kernel Density Estimation,KDE):一种用于估计随机变量概率密度函数的非参数方法。通过平滑处理来填补单独观测值之间的空白,从而生成一个连续的概率密度函数。KDE 通常涉及到选择一个核函数(如高斯核)和带宽(控制平滑程度的参数)。
-
颜色编码:在密度散点图中,不同密度区域通常会使用不同颜色或深浅来表示,颜色深浅代表了该区域内数据点的密集程度。
可视化原理:
-
数据映射:首先将每个数据点映射到二维平面上。这与普通散点图相同,这一步骤确定了每个点在图上的位置。
-
密度估计:对所有数据点应用核密度估计算法。这一步骤是通过在每个数据点周围放置一个“核”,然后对整个数据集覆盖区域内所有核进行求和来完成的。结果是得到整个二维空间上每一位置的密度估计值。
-
颜色映射:根据得到的密度估计值为不同区域分配颜色或深浅。高密度区域将被赋予更深或更鲜艳的颜色,而低密度区域则使用较浅或较淡的颜色。
-
渲染显示:最后将带有颜色编码的二维平面呈现出来,形成最终的密度散点图。可选项:在绘制的密度散点图的右方或下方展示颜色条 colorbar。
为什么要用密度散点图?
- 探索数据分布:通过颜色编码表示不同密度级别,密度散点图能够揭示出数据中可能隐含的各种模式、聚类或趋势。这对于探索性数据分析尤其有用,因为它可以帮助研究人员发现未被预见到的关系或行为模式。我们可以看到哪些区域有更密集的数据点,哪些区域相对稀疏。在处理包含上万个数据点的大型数据集时,传统散点图可能会导致严重的过度绘制(overplotting),即不同数据点在图表上的位置重叠,使得无法清晰地看到数据分布。密度散点图通过表示区域内数据点的相对密度来解决这个问题,从而提供了一种更清晰、更有效地理解数据分布的方式。
- 优化视觉呈现:密度散点图通过采用渐变色或色阶映射等方法,帮助清晰地展示数据,相比传统散点图的混乱和模糊。这样可以更容易区分高密度和低密度区域,使整体呈现更美观、易于理解。高灵活性的密度散点图支持多种定制选项,比如调整颜色映射、透明度、标记大小等,以适应不同类型和规模的数据集。此外,还可以结合其他类型的可视化技术(比如轮廓线或网格)来增强表达能力。
- 异常值检测:密度散点图可以帮助我们识别异常值。如果某个区域的密度远高于其他区域,那么可能存在异常值。
- 聚类分析:密度散点图可以帮助我们发现数据的聚集区域。如果某个区域有较高的密度,那么这可能是一个数据聚类的中心。
- 模型预测结果分析:密度散点图非常适合用于可视化观测值和拟合值的情况,能观察到模型预测的潜在偏移与合理性。
- 促进决策制定:在商业智能、金融分析、生物统计等领域,了解和分析复杂数据集中的模式对于指导决策至关重要。密度散点图提供了一种直观方法来识别关键变量之间的关系和动态变化,从而帮助决策者基于深入洞察做出更加明智的选择。
总结来说,使用密度散点图在处理大规模和 / {/} /或复杂数据集时提供了一种极具价值的工具。它不仅能够有效解决过度绘制问题,还能揭示出隐藏在庞大数据背后的结构和模式,同时提供优雅且功能强大的视觉展示方式。无论是在科研、工业还是商业领域,掌握并应用这种技术都将极大地增强对数据的理解和利用能力。
下面讲解一个带拟合曲线的密度散点图的绘图示例。
导入需要的依赖库:
import numpy as np
from numpy import polyfit, poly1d
import matplotlib as mpl
from matplotlib import cm
from matplotlib import ticker
from matplotlib import colors
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from scipy.stats import gaussian_kde
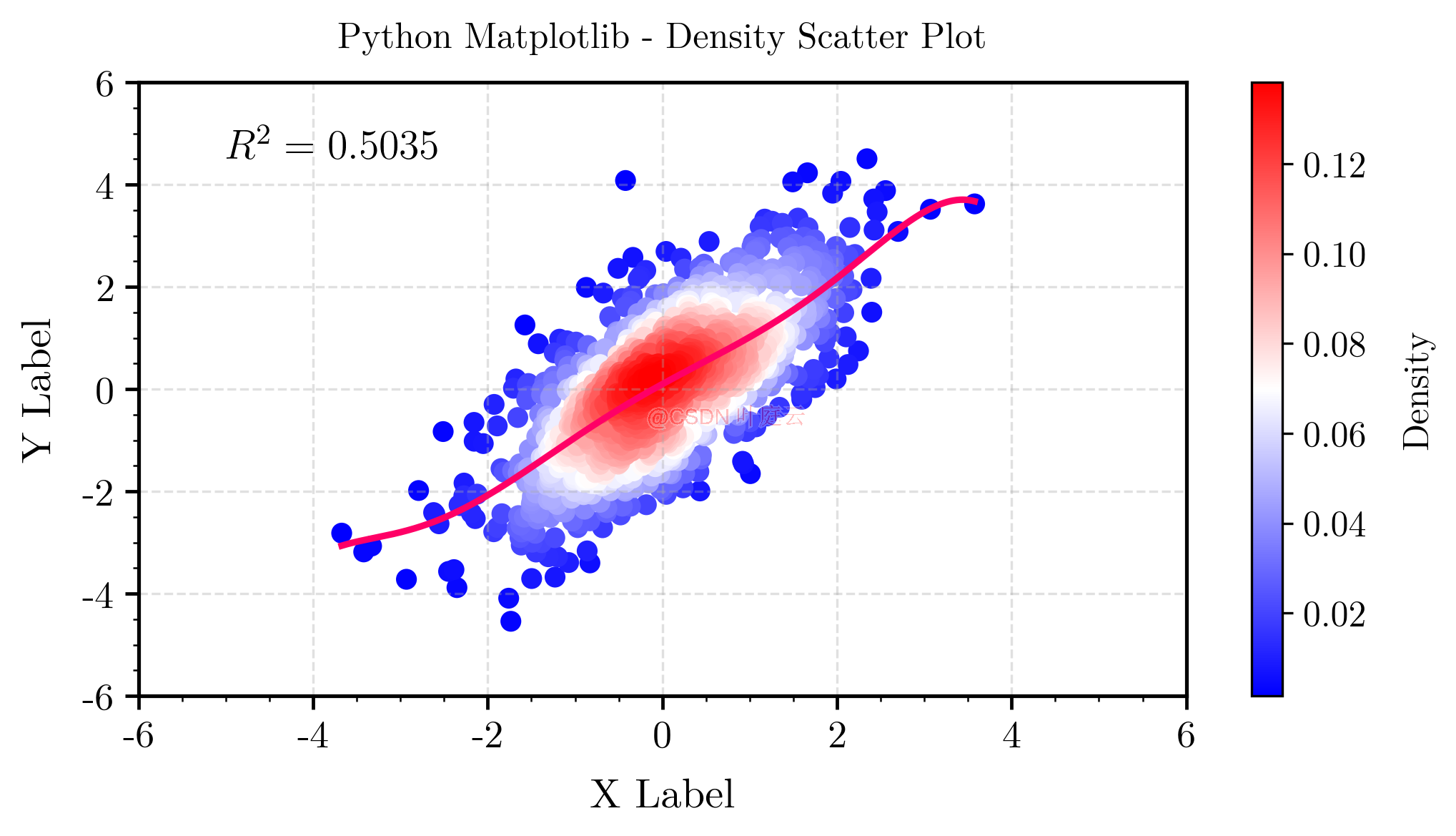
绘制带拟合曲线的密度散点图的 Python 代码如下:
# 固定 numpy 的随机种子
np.random.seed(2024)# 构造二维数据 x 和 y
x = np.random.normal(loc=0.0, scale=1.0, size=1000)
y = x + np.random.normal(loc=0.1, scale=1.0, size=1000)# 核密度估计
x_and_y = np.vstack([x, y])
kde = gaussian_kde(x_and_y)
z = kde(x_and_y)
idx = z.argsort()
x, y, z = x[idx], y[idx], z[idx]is_cbar = True# 创建图形和坐标轴
fig, ax = plt.subplots(figsize=(7, 4), dpi=150)# cmap: bwr、Spectral_r、viridis_r、spring、gist_rainbow_r、RdBu_r
# 可设置的 colormaps - https://matplotlib.org/tutorials/colors/colormaps.html
my_cmap = "bwr"# 绘制密度散点图
ax.scatter(x, y, c=z, cmap=my_cmap)# 用 7 次多项式拟合,调用 poly1d 方法得到多项式系数。
y_fit = polyfit(x, y, 7)
y_fit_1d = np.poly1d(y_fit)
y_hat = np.polyval(y_fit, x)# 计算相关系数和 R^2
print('Correlation coefficients:')
print(np.corrcoef(y_hat, y))
correlation = np.corrcoef(y_hat, y)[0, 1]
R_square = correlation ** 2
print("R^2:", R_square)xtick = np.linspace(min(x), max(x), 1000)
# 拟合的多项式曲线
plt.plot(xtick, y_fit_1d(xtick), color="#FF0066", lw=2.2)# 坐标轴刻度的数值使用 Latin Modern Math 字体
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontproperties(font_latex2) for label in labels]
[label.set_color('black') for label in labels]# 设置坐标轴刻度
plt.tick_params(axis='x', direction='out', labelsize=13, length=4.6, width=1.15)
plt.tick_params(axis='y', direction='out', labelsize=13, length=4.6, width=1.15)# 展示 X 和 Y 轴的子刻度
ax.xaxis.set_minor_locator(ticker.AutoMinorLocator())
ax.yaxis.set_minor_locator(ticker.AutoMinorLocator())# 颜色条的设置:刻度、字体、字号等
if is_cbar:norm = colors.Normalize(vmin=np.min(z), vmax=np.max(z))cbar = plt.colorbar(cm.ScalarMappable(norm=norm, cmap=my_cmap), ax=ax)cbar.ax.set_ylabel("Density", fontproperties=font_latex2, labelpad=12)cbar.ax.tick_params(labelsize=12)labels = cbar.ax.get_xticklabels() + cbar.ax.get_yticklabels()[label.set_fontproperties(font_latex2) for label in labels][label.set_color('black') for label in labels]tick_locator = ticker.MaxNLocator(nbins=8)cbar.locator = tick_locatorcbar.update_ticks()# 设置 X 轴和 Y 轴的刻度值范围
ax.set_xlim(left=-6, right=6.0000001)
ax.set_xticks(np.arange(-6, 6.000001, step=2.0))
ax.set_ylim(bottom=-6, top=6.0000001)
ax.set_yticks(np.arange(-6, 6.000001, step=2.0))# 画图对象周围的框的加粗一点
lw = 1.25
ax.spines["right"].set_linewidth(lw)
ax.spines["left"].set_linewidth(lw)
ax.spines["top"].set_linewidth(lw)
ax.spines["bottom"].set_linewidth(lw)# 设置 X 轴和 Y 轴的标签、字体、刻度和刻度标签在内的坐标轴边界框中的间距
plt.xlabel("X Label", fontproperties=font_latex1, labelpad=8)
plt.ylabel("Y Label", fontproperties=font_latex1, labelpad=8)# 设置标题 字体 大小 以及距绘图对象的距离
plt.title("Python Matplotlib - Density Scatter Plot",fontproperties=font_latex2, pad=12)# 文本的位置是根据数据坐标来确定的
ax.text(x=-5, y=4.5, s=r'$\ {R^2} = 0.522$', usetex=True,fontsize=14, fontweight="bold")# 显示网格 虚线和透明度
plt.grid(alpha=0.360, ls="--", which="major", color="#A9A9A9")
# 紧凑布局
plt.tight_layout()plt.savefig("./Figures/密度散点图.png", dpi=300, bbox_inches="tight")
plt.show()
整体解释:这段代码首先导入了所需的库,然后生成了测试数据 x x x 和 y y y(实际应用还可能是真实值 y y y 和预测值 y ^ \hat y y^)。接着,它使用核密度估计(KDE)来计算数据的密度分布。之后,它绘制了一个密度散点图,并使用多项式拟合来生成一个曲线。最后,它计算了相关系数和 R 2 R^2 R2 值,并设置了各种图形属性,如坐标轴刻度、颜色条、网格等。最后,它将图像保存为一个 .png 文件并显示出来。
可视化结果如下所示:
📚️ 参考链接:
- 使用 Python 绘制散点密度图(用颜色标识密度)
- 复现顶刊 RSE 散点密度验证图(附代码)
这篇关于Python 数据可视化之密度散点图 Density Scatter Plot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






