本文主要是介绍PEARL: 一个轻量的计算短文本相似度的表示模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 💻 [code] | 💾 [data] | 🤗 PEARL-small | 🤗 PEARL-base | 论文
如何计算短文本相似度是一个重要的任务,它发生在各种场景中:
- 字符串匹配(string matching)。我们计算两个字符串是否表达同一个含义,比如“university” 和 “universities” 尽管看起来不同,但它们有着相同的语义。我们希望一个模型能够捕捉这种有形态变化的相似性。
- 模糊匹配 (Fuzzy Join)。这是数据科学中经常遇到的困难,当我们在join不同的表时候,列和列之间的名词并不是完全匹配的。比如在一个关于工资的表中有一个列叫avg_salary,而在另一个表中这个列叫做average_wage,这就使得我们很难匹配到相关的列。这里我们需要一个模型能够捕捉这种语义相似性。
- 实体检索 (Entity Retrieval)。这个任务目的是从一个实体候选集 (比如知识库)中找出最匹配的查询实体。比如输入的查询是“The New York Times”,候选集中有三个实体名称["NYTimes", "New York Post", "New York"]。这里我们需要一个模型去找出“NYTimes”是最相关的实体。值得注意的是,有时候实体候选集非常大,可能达到百万千万级别,因此模型的速度也是需要考虑的。
传统的方法使用文本编辑距离计算文本相似度,这种方法简单速度快,缺点就是不能捕捉语义的相似度,比如例子2和例子3的情况。FastText是可以基于词向量计算语义相似度,但是它的效果不如现在流行的上下文相关的语言模型,比如BERT。
这篇文章我们要介绍一个轻量的表示模型PEARL,它只有34M参数,可以计算各种短文本的相似度。比如上面实体检索的案例,PEARL可以知道"The New York Times"和“NYTimes”有着相同的语义。
query_texts = ["The New York Times"]
doc_texts = [ "NYTimes", "New York Post", "New York"]
input_texts = query_texts + doc_textstokenizer = AutoTokenizer.from_pretrained('Lihuchen/pearl_base')
model = AutoModel.from_pretrained('Lihuchen/pearl_base')# encode
embeddings = encode_text(model, input_texts)# calculate similarity
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())# expected outputs
# [[85.61601257324219, 73.65624237060547, 70.36172485351562]]PEARL的主要思想是使用对比学习框架来学习段文本表示。因为相同意思的文本本身会有多种多样的形式,比如上面“The New York Times”的案例。为了刻画这些特征,PEARL在训练中引入增强样本学习多样性。比如引入字母,单词以及词组级别增强,如下图所示:
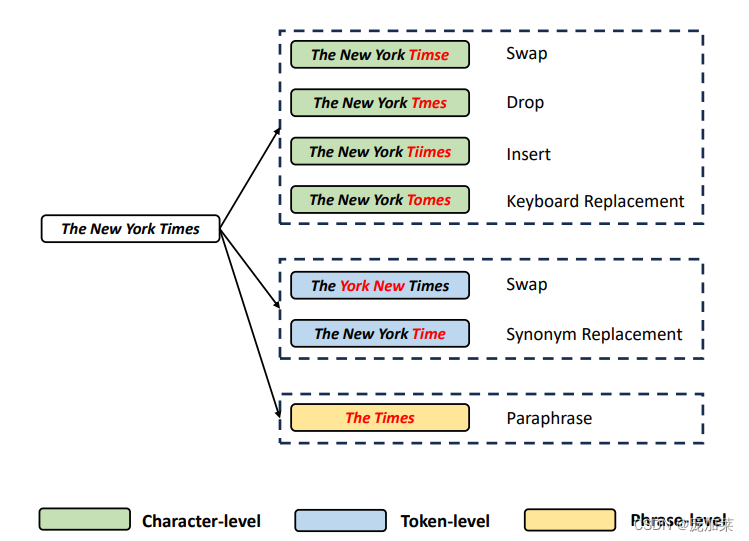
同时,PEARL还在训练中引入了一个辅助任务:短文本类别识别。 PEARL在训练中会让模型的类别,比如“The New York Times”是一个与organization相关的名词短语,noun phrase organization (NP-ORG)。通过这个任务,不同类别的短文本会被区分开,我们也会学到更好的表示。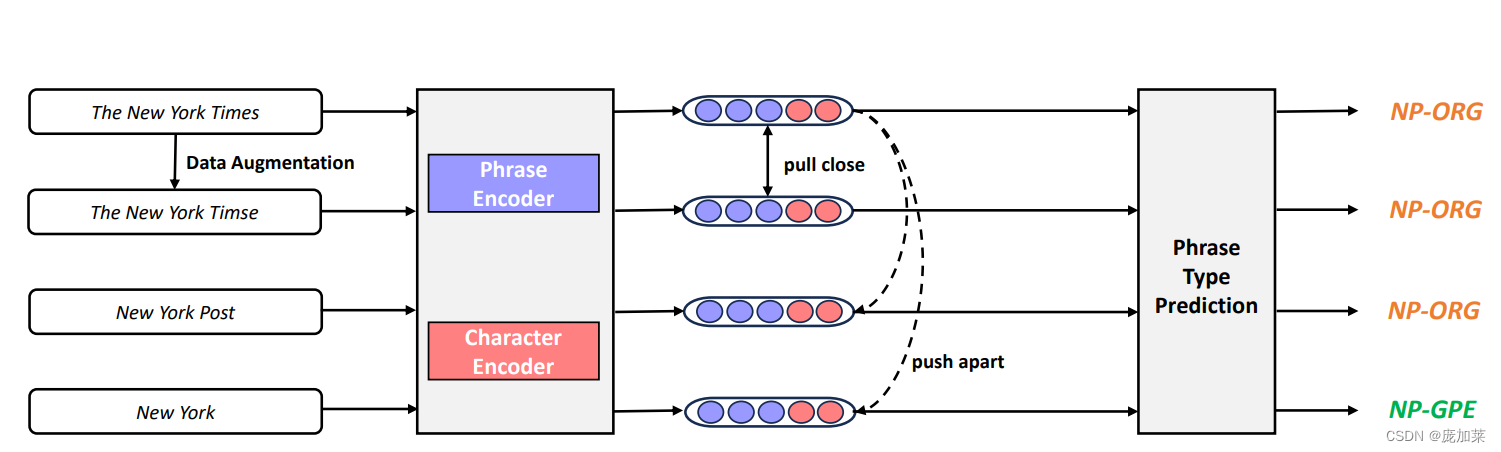
实验结果表明,PEARL在五个任务(Paraphrase Classification,Phrase Similarity,Entity Retrieval,Entity Clustering,Fuzzy Join)都取得了最好的表现:
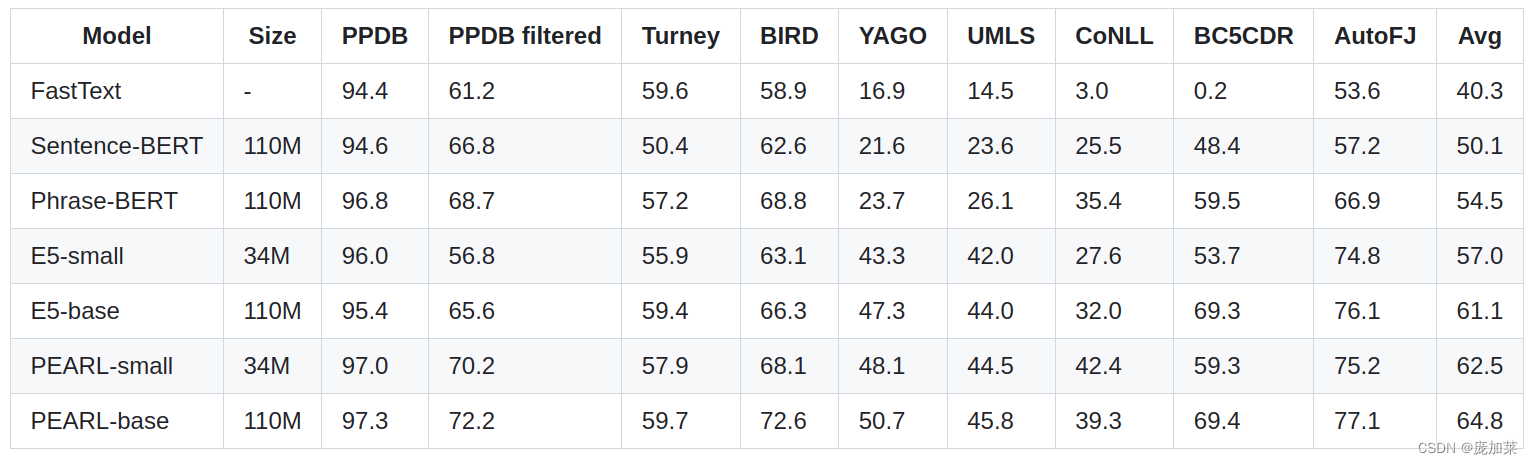
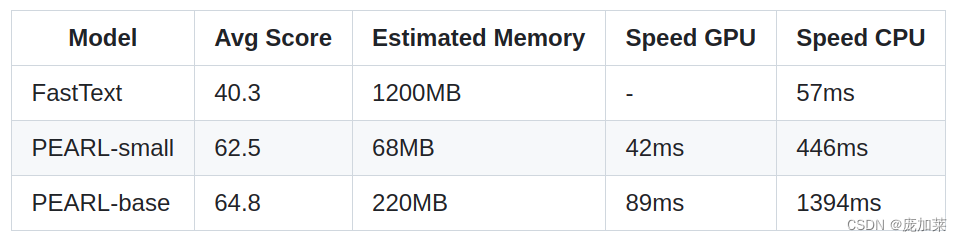
同时PEARL在内存和推理速度花销上并没有比FastText高很多。PEARL模型是FastText的很好的替代方案:
 | 💻 [code] | 💾 [data] | 🤗 PEARL-small | 🤗 PEARL-base | 论文 |
| 💻 [code] | 💾 [data] | 🤗 PEARL-small | 🤗 PEARL-base | 论文 |
作者主页:chenlihu.com
如果觉得以上论文或代码有用,请引用或者给出小星星😊
@article{chen2024learning,title={Learning High-Quality and General-Purpose Phrase Representations},author={Chen, Lihu and Varoquaux, Ga{\"e}l and Suchanek, Fabian M},journal={arXiv preprint arXiv:2401.10407},year={2024}
}这篇关于PEARL: 一个轻量的计算短文本相似度的表示模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









